7种正则化方法
正则化是一种降低机器学习模型过拟合风险的技术。L1正则化公式:L2正则化公式:L1正则化实际上就是L1范数,L1简单示意图:L2正则化实际是L2范数,L2简单示意图:从上面两图可以看出L1和L2正则化函数是凸函数,可行域是凸集,对应的问题是一个凸优化问题 -- 简单问题(可以看王木头学科学的视频,我这里介绍的不清楚:“L1和L2正则化”直观理解(之一),从拉格朗日乘数法角度进行理解_哔哩哔哩_bi
L1正则化(Lasso)
L2正则化(Ridge)
弹性网络正则化
Dropout正则化
早停法
数据增强
目录
1. 什么是正则化
正则化是一种降低机器学习模型过拟合风险的技术。
2. 正则化实现方式
在损失函数中添加一个正则项来实现。
正则项:基于模型参数而构建;
例如L1正则项:由所有特征权重(参数)的绝对值之和组成: , w是模型参数;
3. 正则化为何有用
通过限制模型参数的数量或幅度来限制模型的复杂度;
过拟合的模型的复杂度较高,引入正则化后可以避免过拟合。
例如L1正则项:模型参数的绝对值之和作为正则项。它倾向于使一些参数变为零,约束参数的大小,防止因参数过大而导致误差和噪声被放大而出现误判的问题。
4. L1和L2正则化介绍
L1正则化公式:
L2正则化公式:
L1正则化实际上就是L1范数,L1简单示意图:
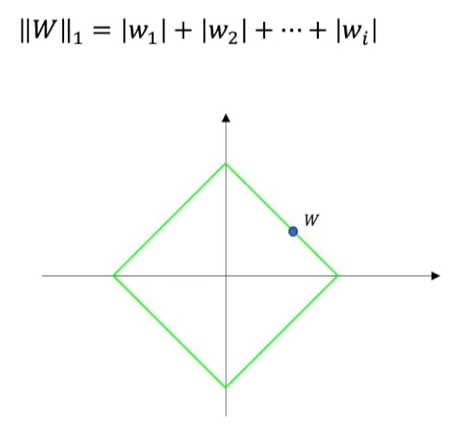
L2正则化实际是L2范数,L2简单示意图:
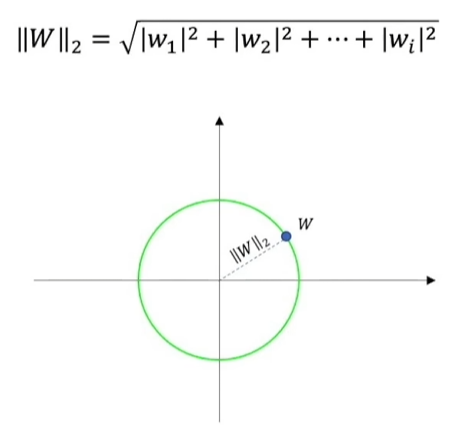
从上面两图可以看出L1和L2正则化函数是凸函数,可行域是凸集,对应的问题是一个凸优化问题 -- 简单问题
使用L1和L2正则化的原因:(可以看王木头学科学的视频,我这里介绍的不清楚: “L1和L2正则化”直观理解(之一),从拉格朗日乘数法角度进行理解_哔哩哔哩_bilibili)
产生过拟合的一个原因:学习到的函数很好的拟合了训练集,但在测试集效果不好,表现为其损失值取得最小,但在测试集损失值较大;
然而损失值取最小可能对应多种W和b, 但是当得到一个较大的权重值时对测试集的效果可能会变差,这是因为参数过大会导致误差和噪声被放大而出现误判的问题。
因此消除过拟合可以将学习到的需要设置好权重参数的范围,不能太大也不能太小,因此希望规范权重参数的范围:
这就有了:
对于L1约束:
对于L2 约束:
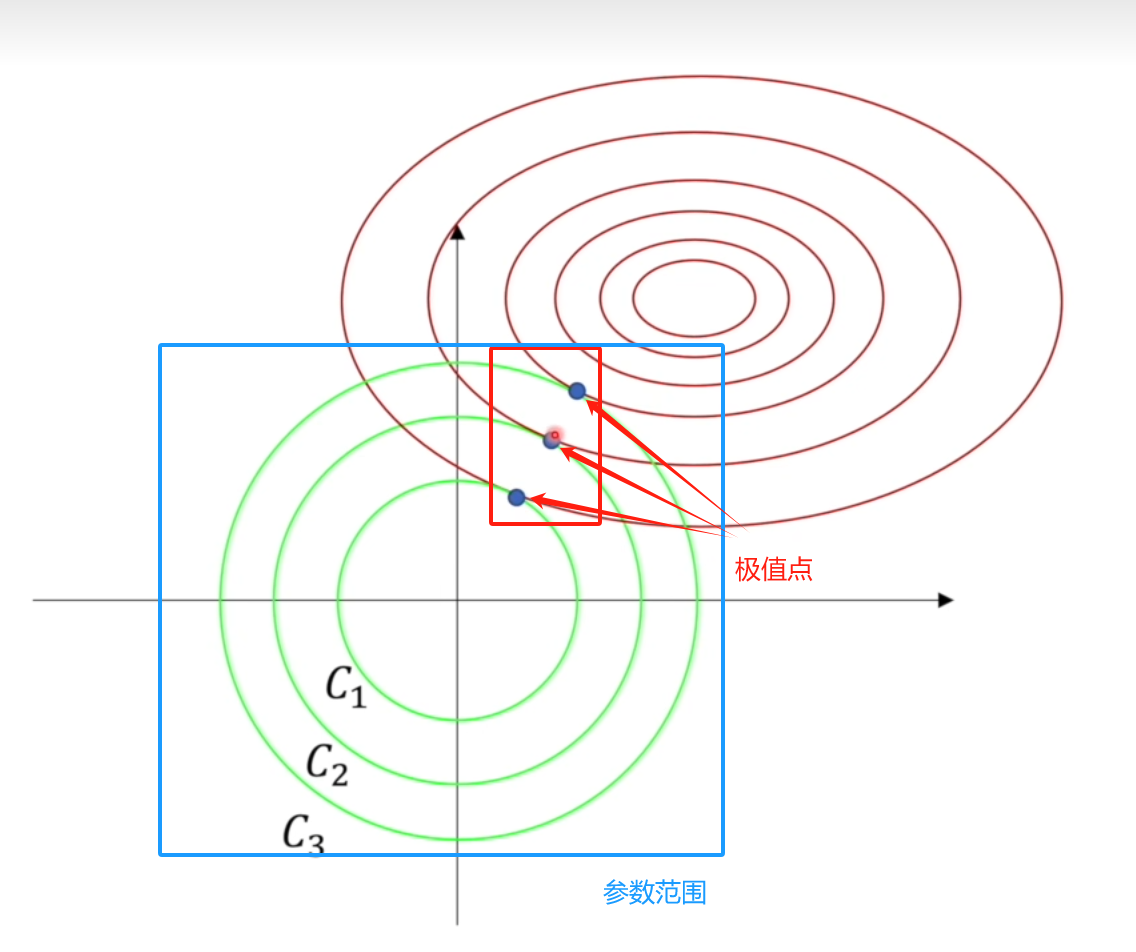
即,我们希望权重参数值被框在了C这个范围内,可视化图:
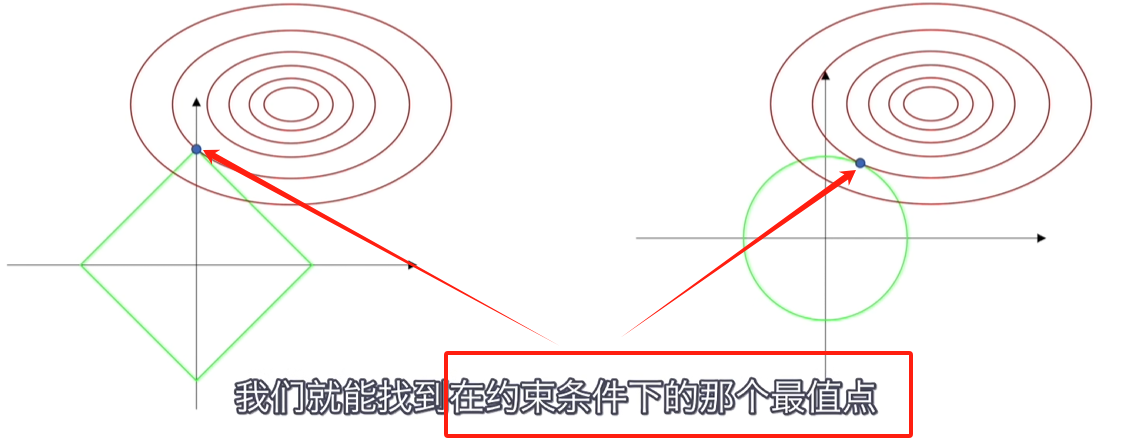
然而上述公式与正则化公式不同:,多了个C,但实际上求导后是等价的:即我们希望求出的权重参数是相同的
因此现在的正则化公式被表示为
L1正则化的特点: 可能会产生稀疏解,即部分权重参数会为0,如图:坐标轴上的参数,表示有些维度的值为0(只关注某些维度的特征),将无用特征的系数设为零
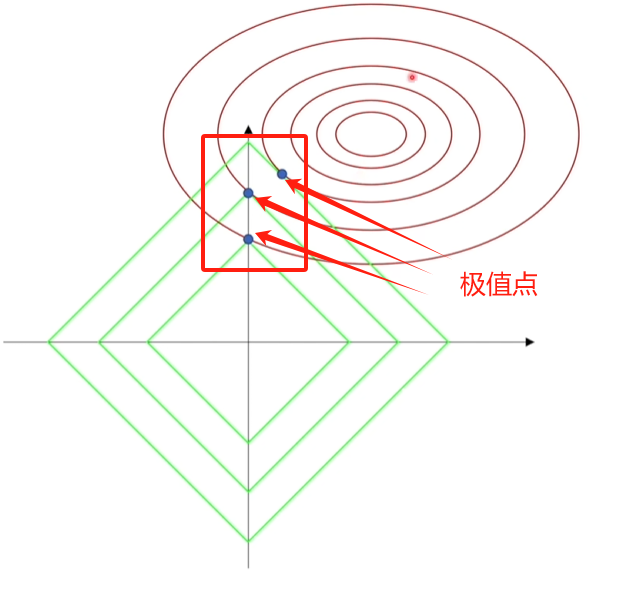
L2正则化的特点: 鼓励权重系数更平滑,即权重系数值不会相差太大(会同时考虑多个特征), 防止在特征高度相关时模型不稳定
5. 弹性网络正则化(Elastic Net)
结合了L1正则化和L2正则化的特点,弹性网络正则化可以综合利用L1和L2正则化的优势;
公式:
结合L1和L2的优点, 使得弹性网络正则化即考虑特征选择又考虑特征之间的相互影响
6. Dropout正则化
在训练过程中随机将一部分神经元的输出设置为零,防止神经元之间过度依赖, 从而减少神经网络中的过拟合现象.
例如:某一层的输出向量为: [0.2, 0.5, 1.3, 0.8, 1.1]
Dropout 概率 p=0.3 随机选择丢弃部分参数(设为0)。这意味着 70% 的参数将被保留,30% 的参数将被丢弃。比如,假设得到以下输出向量:[0, 0.5, 0, 0.8, 0]
剩余的参数需要进行按比例放大,以确保输出的期望值一致:
这是因为丢弃了一部分参数,剩余的参数需要补偿这些丢失的部分,否则就要在推理的时候做补偿;
按照 p=0.3,剩余的参数将乘以 1 / (1 - p) = 1 / 0.7 ≈ 1.4286,最后得到:[0, 0.7143, 0, 1.1429, 0]
在测试阶段,不再进行丢弃操作.
7. 早停法
在训练过程中监测验证误差,并根据验证误差的变化来确定何时停止训练模型,以避免过拟合。
8. 数据增强
通过对训练数据进行随机变换或扩充来增加数据集的多样性。这种方法可以帮助模型更好地泛化,并减轻过拟合问题。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)