具身智能体如何规划决策!ET-Plan-Bench:面向基础模型时空认知的具身任务级规划基准
论文提出了一个新的具身任务规划基准ET-Plan-Bench,并展示了现有基础模型在具身任务规划中的挑战和潜力。通过引入空间和时间约束,显著增加了任务的难度,发现SOTA的LLMs在处理这些复杂任务时表现不佳。通过监督微调,较小的模型也可以达到与SOTA模型相当的水平。该基准为未来的具身任务规划研究提供了一个大规模、自动化、细粒度的诊断框架。

-
作者:Lingfeng Zhang, Yuening Wang, Hongjian Gu, Atia Hamidizadeh, Zhanguang Zhang, Yuecheng Liu, Yutong Wang, David Gamaliel Arcos Bravo, Junyi Dong, Shunbo Zhou, Tongtong Cao, Yuzheng Zhuang, Yingxue Zhang, and Jianye Hao
-
单位:华为诺亚方舟实验室,华为云
-
标题:ET-Plan-Bench: Embodied Task-level Planning Benchmark Towards Spatial-Temporal Cognition with Foundation Models
-
原文链接:https://arxiv.org/pdf/2410.14682
主要贡献
-
论文提出了具身任务规划基准测试平台ET-Plan-Bench,用于评估使用基础模型进行具身任务规划的能力。
-
开发了自动化的具身任务生成和评估流程,能够生成具有不同空间和时间约束的多样化任务。
-
在基准测试中评估了多种开源和闭源的基础模型,展示了这些模型在处理需要深入理解空间、时间和因果关系的任务时的表现。
-
通过使用监督微调(SFT)技术,展示了如何利用生成的基准数据来增强小型基础模型的能力。
研究背景
研究问题
论文主要解决的问题是如何利用大型语言模型(LLMs)进行具身任务规划,特别是针对高层次的任务规划和任务分解。
研究难点
该问题的研究难点包括:
-
如何评估LLMs在具身任务理解中的空间和时间理解能力,
-
如何生成具有不同难度和复杂性的具身任务,
-
以及如何提供一个大规模、自动化、细粒度的诊断框架来评估现有基础模型的性能。
相关工作
-
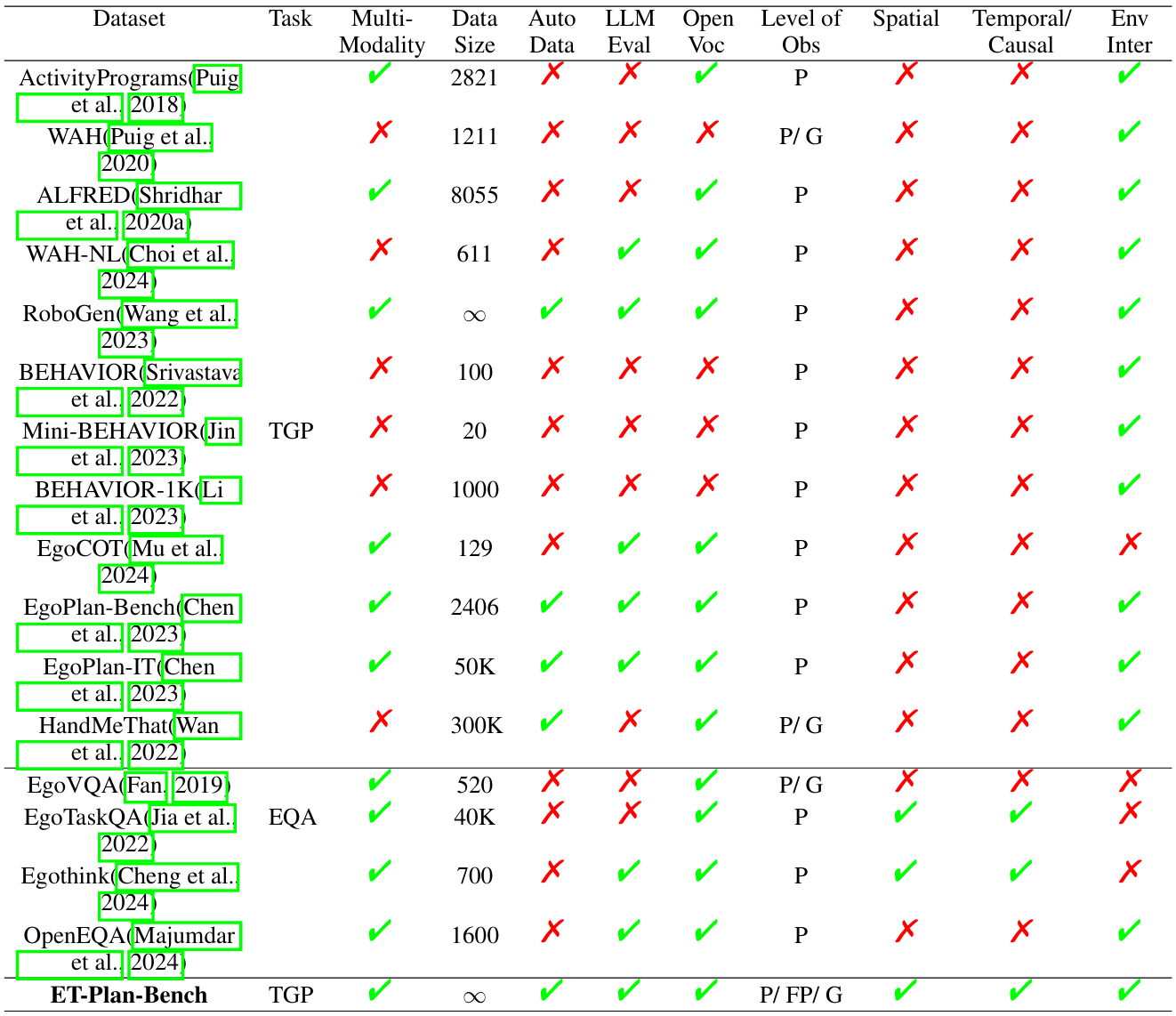
该问题的相关工作包括对家用具身任务规划的基准测试,如ActivityPrograms、WAH、ALFRED等。
-
这些基准测试通常依赖于手工注释,缺乏自动化的数据生成和多模态交互能力。
-
相比之下,ET-Plan-Bench通过使用多源模拟器作为后端模拟器,提供了即时的环境反馈,使LLMs能够动态地与环境互动并重新规划。
基准描述
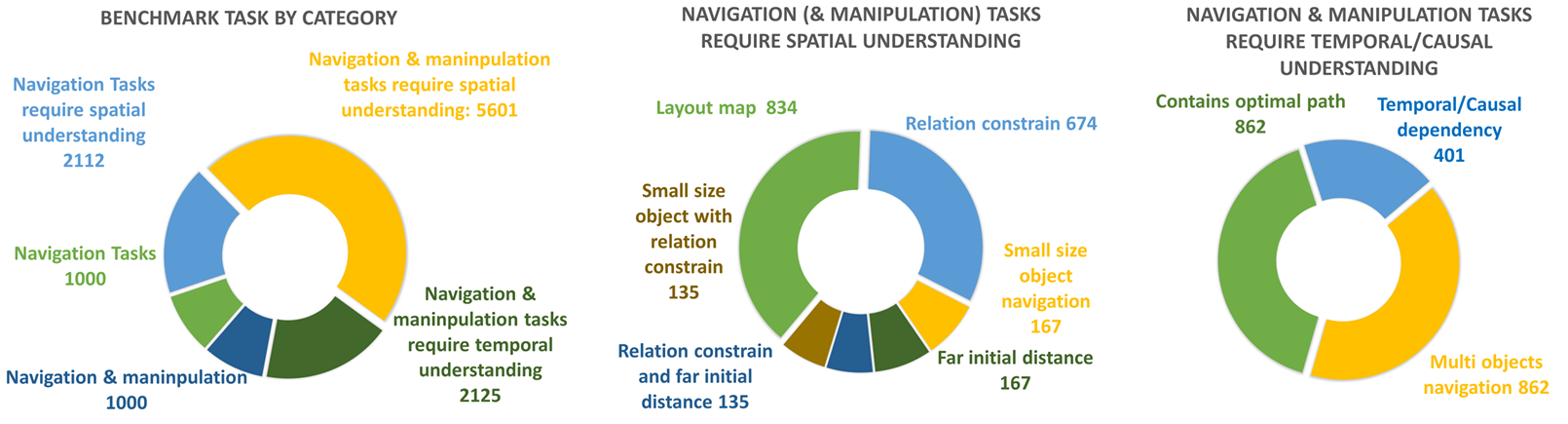
任务类别及其子类别
-
导航任务:
-
这是最常见的家庭场景任务之一,要求智能体在未知环境中导航到特定对象类别的实例。例如,找到一个苹果。
-
-
带有布局图的导航:
-
在现实世界中,机器人通常拥有某些环境先验知识,如布局图,其中包含大型家具(如沙发和冰箱)的位置。
-
这些信息可以帮助机器人更高效地执行导航任务。
-
-
带有空间关系约束的导航:
-
要求机器人识别满足给定标准的具体目标对象,例如在墙上找到一个盒子。
-
这种空间关系约束可以评估智能体对物体之间相对位置的理解能力。
-
-
由于小物体尺寸引起的遮挡:
-
指的是大物体或障碍物遮挡视线中的目标物品,挑战智能体提供策略以揭示或到达这些隐藏的目标物体。
-
这种情况在小物体导航中很常见,因为目标物体不会直接可见。
-
-
由于初始位置距离远引起的遮挡:
-
设计任务以针对位于机器人初始位置远处的目标对象。
-
这种设置对智能体来说更具挑战性,因为它需要在房间内导航,目标物体更可能被大型家具遮挡。
-
-
导航与操作任务:
-
通常涉及移动和组织物品,例如拿起一个物体并将其重新定位到指定区域。
-
其他子类别包括带有空间约束或遮挡的操作任务。
-
-
具有时间约束的导航与操作任务:
-
涉及必须按严格顺序执行的动作,例如准备一顿饭。
-
智能体需要理解动作之间的因果关系,并在正确的顺序中执行它们。
-
-
多物体导航与操作:
-
涉及同时处理多个物体,例如准备各种物品以实现特定目标。
-
Virtual Home支持使用双臂进行此类任务,允许机器人同时使用两只手臂完成任务。
-
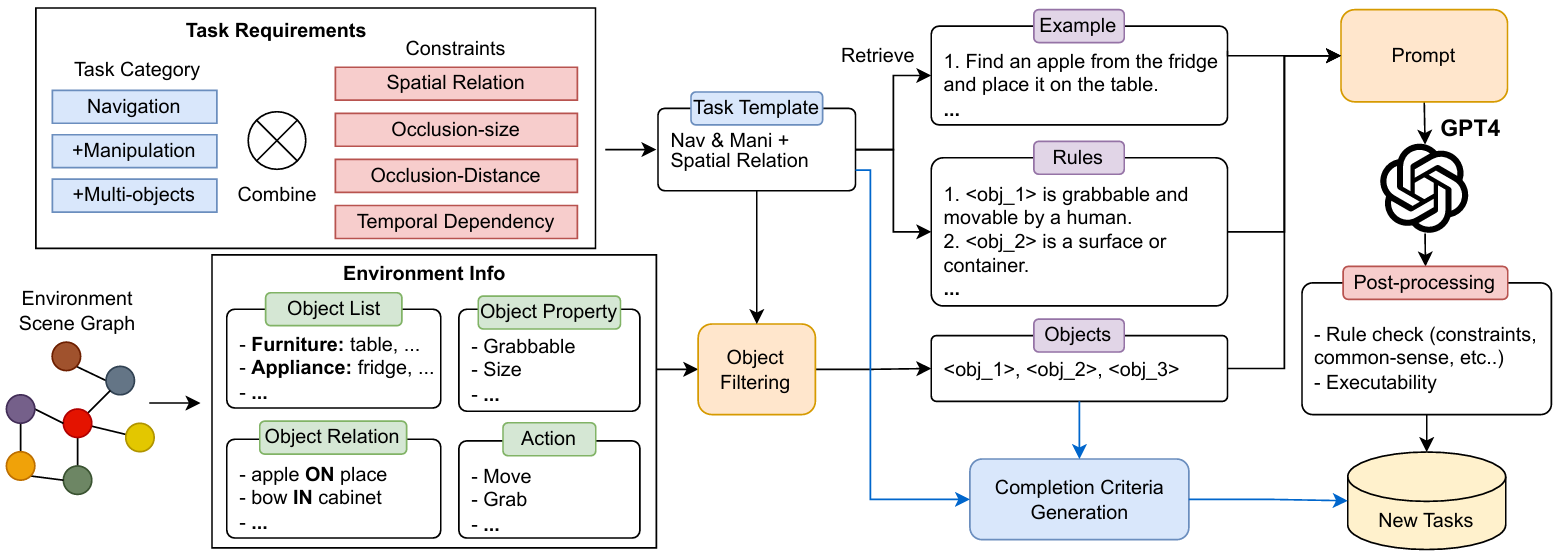
基于大模型的任务生成
-
任务模板生成:
-
首先生成特定类型任务的任务模板。每个模板包括任务描述和完成标准。
-
描述中包含了涉及的物体数量、它们的属性以及任何额外的空间或时间约束。
-
这些信息被整合为占位符,用于生成任务的不同表述。
-
-
从模拟器获取环境信息:
-
给定特定的任务模板,从模拟器的场景图中收集相关信息。
-
通过场景图,选择所有满足任务模板中要求的约束的可能对象候选者。
-
-
LLMs辅助任务生成:
-
在从环境中检索相关信息后,筛选出所有符合任务要求的项目组合。
-
然后,使用LLMs生成符合逻辑常识且多样化描述的任务。
-
LLMs接收环境和任务模板作为提示的一部分,并包括规则和示例,以确保生成的任务是真实的。
-
-
基于可执行性的后过滤:
-
生成的LLM任务在模拟器中进行测试,以检查其可执行性。
-
任何违反模拟器中编码的物理规则的任务都会被丢弃,只保留可执行的任务。
-
-
生成真实规划标签:
-
使用每个布局的场景图生成真实规划序列。
-
找到机器人与目标物品之间的最短路径,并生成详细的真实动作序列。
-
基准测试
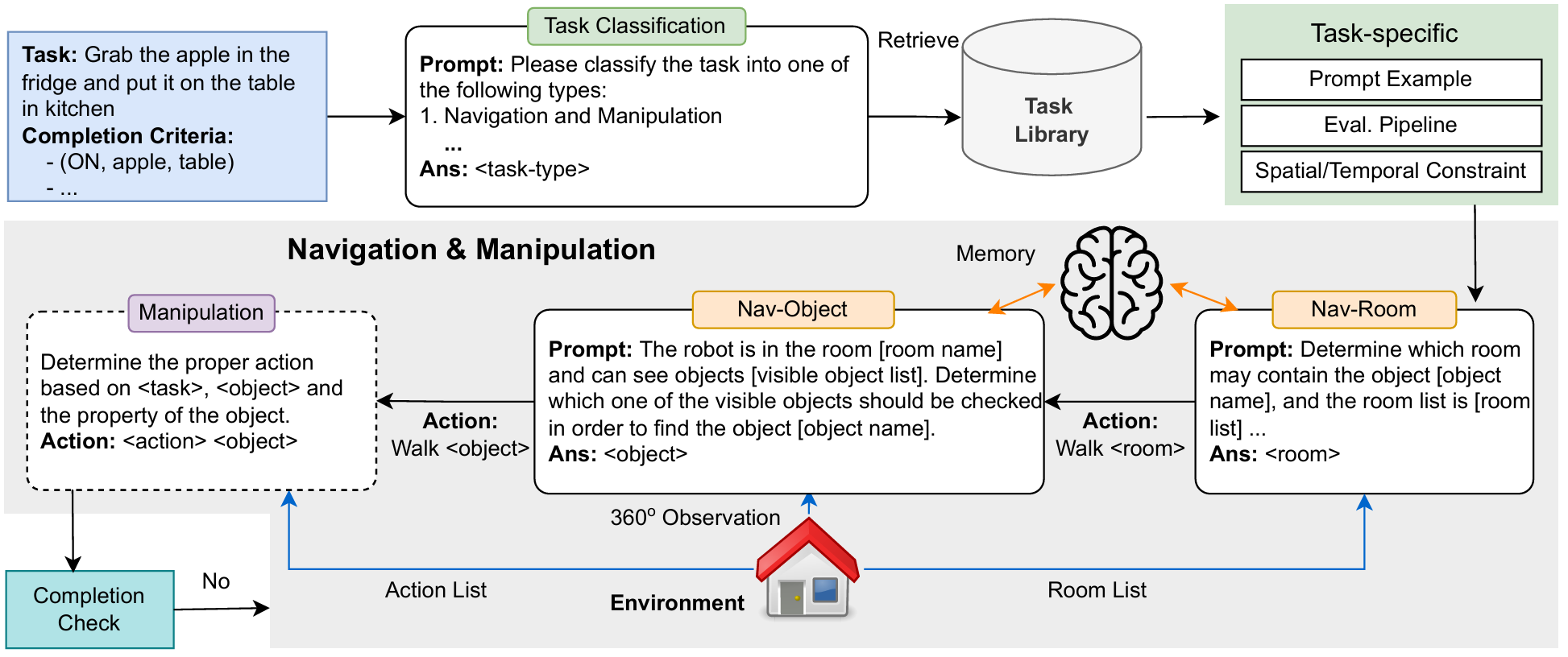
整体评估流程
-
任务分类:
-
LLM智能体首先根据任务描述确定任务的类型。任务类型包括导航任务、导航与操作任务等。
-
智能体会根据识别的任务类型从库中检索相应的工具和提示示例,以便在后续过程中使用。
-
-
导航-房间:
-
对于导航任务,智能体采用自顶向下的层次方法来确定目标对象可能所在的房间。
-
智能体根据任务描述和环境中的房间列表来决定搜索房间的顺序。
-
对于涉及空间关系约束的任务,智能体会优先搜索包含目标对象和锚定对象的房间。
-
-
导航-对象:
-
一旦智能体到达指定房间,它会进行360度扫描,识别视野内的物体。
-
如果目标对象不在视野内,智能体会主动选择最相关的可见物体进行进一步的探索。
-
智能体会将观察到的物体及其位置存储在内存中,以便在需要时协助定位后续物体。
-
-
操作:
-
对于涉及操作目标对象的任务,智能体会执行特定的操作动作,如打开(OPEN)、关闭(CLOSE)、抓取(GRAB)、放置(PUT)和放入(PUTIN)。
-
智能体会根据任务要求使用这些操作技能与虚拟环境中的目标对象进行交互。
-
-
完成检查和迭代:
-
在每次导航或操作步骤后,智能体会评估是否达到了完成标准。
-
如果没有达到标准,智能体会进行额外的导航和操作。
-
如果达到最大动作步骤数而任务仍未完成,则任务被视为失败。
-
-
复杂任务:
-
复杂任务可以被分解为更小的子任务,每个子任务涉及导航和操作单个对象。
-
每个子任务都可以独立地使用LLM智能体的评估管道来处理。智能体会根据任务描述和当前的环境状态来执行导航和操作动作。
-
在处理复杂任务时,智能体可能会考虑路径优化,以减少总的移动距离和操作步骤。
-
通过将复杂任务分解为更简单的子任务,智能体可以更有效地处理涉及多个对象的操作,从而提高任务完成的成功率和效率。
-
实验与结果
- 实验设置:
-
实验在8个NVIDIA Tesla V100 32G GPU和Intel Xeon Gold 6140 CPU上进行。
-
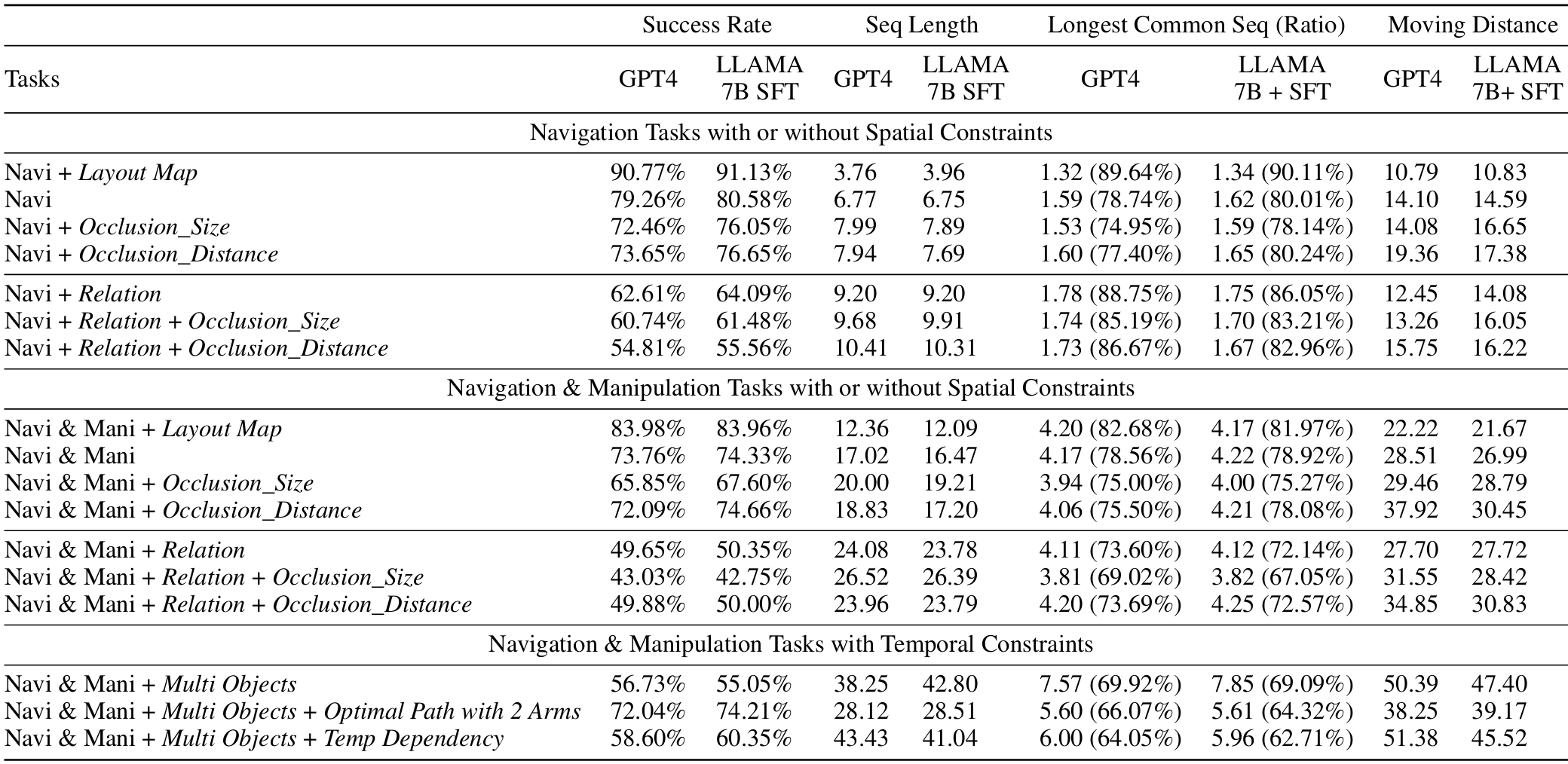
论文使用了五种评估指标来衡量智能体在任务中的表现,包括成功率、动作序列长度、最长公共子序列(LCS)长度、LCS比率以及执行任务的移动距离。
-
-
Virtual Home环境的结果:
-
在Virtual Home环境中,论文分析了不同类型任务的表现。结果显示,添加空间约束显著影响了成功率。例如,由于小物体尺寸或距离引起的遮挡,成功率下降了7%到6%,表明这些因素增加了任务的难度。
-
布局图的使用显著提高了导航和导航-操作任务的成功率,因为智能体可以利用全局知识更高效地定位目标对象。
-
-
多对象任务的结果:
-
在处理多个对象的任务时,成功率有所下降,这表明随着任务序列长度的增加,机器人犯错和失败的机会更多。
-
此外,当机器人选择最优路径来操作多个对象时,平均移动距离显着减少,成功率也有所提高。
-
-
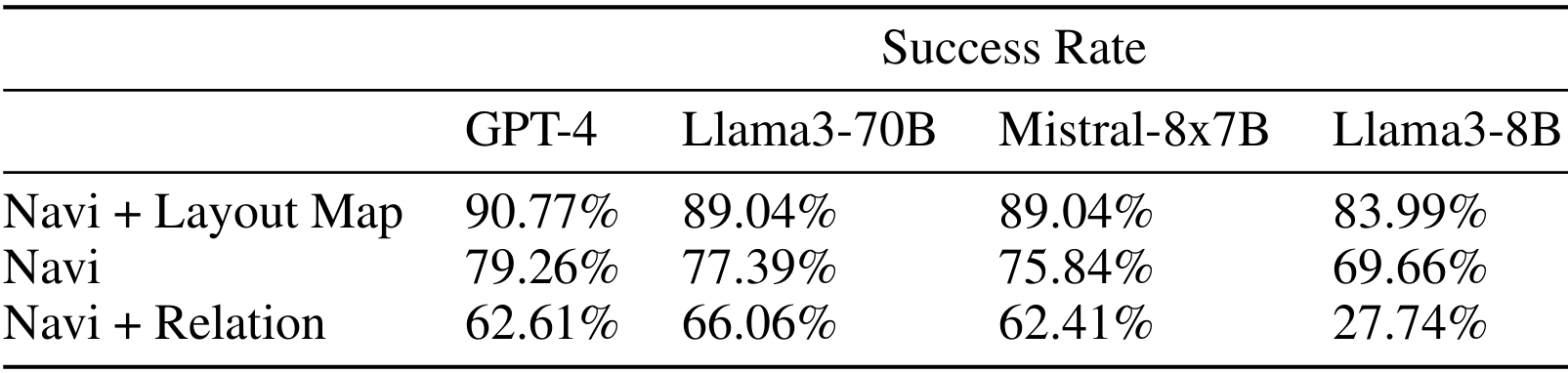
与其他LLM模型的比较:
-
论文还评估了其他开源和闭源的LLM模型,如GPT-4、Llama3-70B、Mistral-8x7B和Llama3-8B。
-
结果显示,尽管其他强大的开源模型(如Llama3-70B和Mixtral-8x7B)与GPT-4表现相似,但较小的模型Llama3-8B在导航任务中表现较差。
-
-
监督微调的结果:
-
论文通过使用生成的数据进行监督微调,评估了较小模型(如LLAMA-7B)的能力。
-
结果表明,微调后的模型在理解和遵循指令方面表现出色,甚至在某些情况下可以与GPT-4相媲美。
-


案例分析

-
论文展示了成功的任务执行案例,以说明智能体在处理复杂任务时的能力。这些案例通常涉及智能体在虚拟环境中执行导航和操作任务,并成功地完成了任务。
-
例如,一个案例中,智能体在探索不同的房间后找到了一个带有关系约束的目标对象。在这个案例中,智能体需要找到一个与电视相关的盒子,并在多个房间中搜索以找到它。
-
论文还展示了失败的案例,以分析任务失败的原因。这些案例通常涉及智能体在任务执行过程中遇到的困难,如感知模块的缺陷或目标物体的遮挡。
总结
论文提出了一个新的具身任务规划基准ET-Plan-Bench,并展示了现有基础模型在具身任务规划中的挑战和潜力。
通过引入空间和时间约束,显著增加了任务的难度,发现SOTA的LLMs在处理这些复杂任务时表现不佳。
通过监督微调,较小的模型也可以达到与SOTA模型相当的水平。该基准为未来的具身任务规划研究提供了一个大规模、自动化、细粒度的诊断框架。


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 14
14 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)