5步打造 GraphRAG 智能体,让 Neo4j 和 AI 完美协作!
我们将讨论以下内容:• 构建我们自己的自定义 AI 工具供智能体使用• 创建智能体并为其提供我们构建的自定义工具• 构建一个工具,用于使用 Neo4j 向量索引进行向量搜索• 构建另一个工具,将自然语言转换为 Cypher 查询代码
准备好将您的 RAG(检索增强生成)应用提升到新高度了吗?欢迎来到本系列的最新章节,我们将探索图数据库与大语言模型(Large Language Model, LLM)强大结合的奥秘。在上一期中,我们讨论了如何通过智能体 AI(Agentic AI)将自然语言转换为 Cypher 查询代码。
今天,我们将更进一步,通过构建智能 AI 智能体(AI Agent),充分利用 Neo4j 的图数据库能力和 LangChain 工具,为用户查询提供更加精准、上下文相关的答案。
我们将讨论以下内容:
-
• 构建我们自己的自定义 AI 工具供智能体使用
-
• 创建智能体并为其提供我们构建的自定义工具
-
• 构建一个工具,用于使用 Neo4j 向量索引进行向量搜索
-
• 构建另一个工具,将自然语言转换为 Cypher 查询代码

图片来源:Code With Prince
什么是 AI 智能体?
可以将 AI 智能体想象成一个配备了精心设计工具箱的数字助手。通过为 AI 系统配备特定工具与外部世界交互,它从被动的语言模型转变为动态问题解决者,能够主动采取行动。
创建 Neo4j GraphRAG 智能体
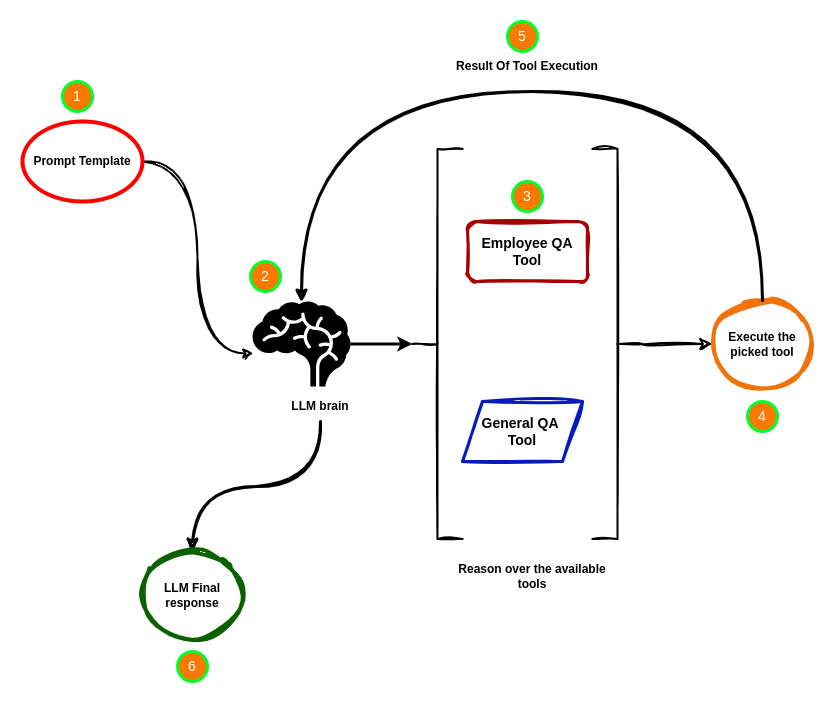
如今,您可能已经注意到,生成式 AI(Generative AI, GenAI)的发展正朝着智能体化方向迈进,至少在撰写本文时是这样。因此,理解什么是智能体非常重要,我们在 LangChain 的入门部分已经介绍过。在本节中,我们将更专注于构建用于聊天机器人的智能体。您还记得这张图吗?
您还记得这张图吗?
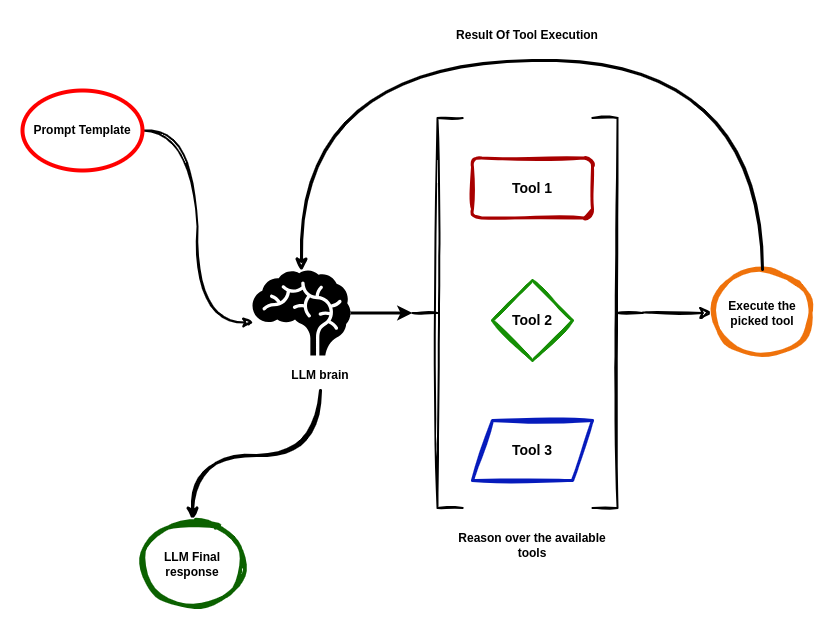
让我们稍微修改一下这张图,以反映智能体可以访问的工具。
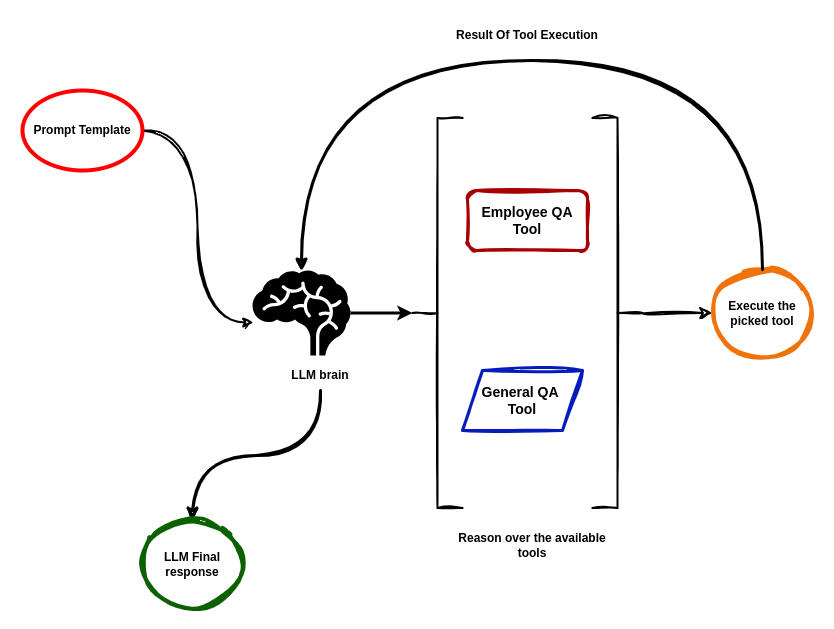
图片来源:Code With Prince
向 AI 智能体提问时,它会选择“员工问答工具”(Employee QA Tool)或“通用问答工具”(General QA Tool)。根据所选工具,AI 智能体将执行相应工具并生成最终答案。
我将使用一个 Python 函数来创建 employee_qa_tool。如果您愿意,也可以使用类。以下是创建该工具的代码,与我们之前讨论的内容差不多:
employee_details_chat_template_str = """
你的任务是使用提供的员工数据回答
关于他们在公司中的角色、绩效和经历的问题。
使用以下上下文来回答问题。
尽可能详细,但不要编造上下文中没有的信息。
如果你不知道答案,就说不知道。
{context}
"""
@tool("employee-qa-tool", return_direct=True)
def employee_qa_tool(query: str) -> str:
"""回答公司员工相关问题的工具。"""
employee_details_chat_system_prompt = SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=["context"],
template=employee_details_chat_template_str
)
)
human_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=["question"],
template="你能提供以下问题的详细信息吗:{question}?"
)
)
messages = [employee_details_chat_system_prompt, human_prompt]
qa_prompt = ChatPromptTemplate(
messages=messages,
input_variables=["context", "question"]
)
llm = ChatOpenAI(model="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=neo4j_graph_vector_index.as_retriever(),
chain_type="stuff",
)
qa_chain.combine_documents_chain.llm_chain.prompt = qa_prompt
response = qa_chain.invoke(query)
return response.get("result")
我们可以这样使用该工具:
employee_qa_tool.invoke("Andrew 的地址是什么?")
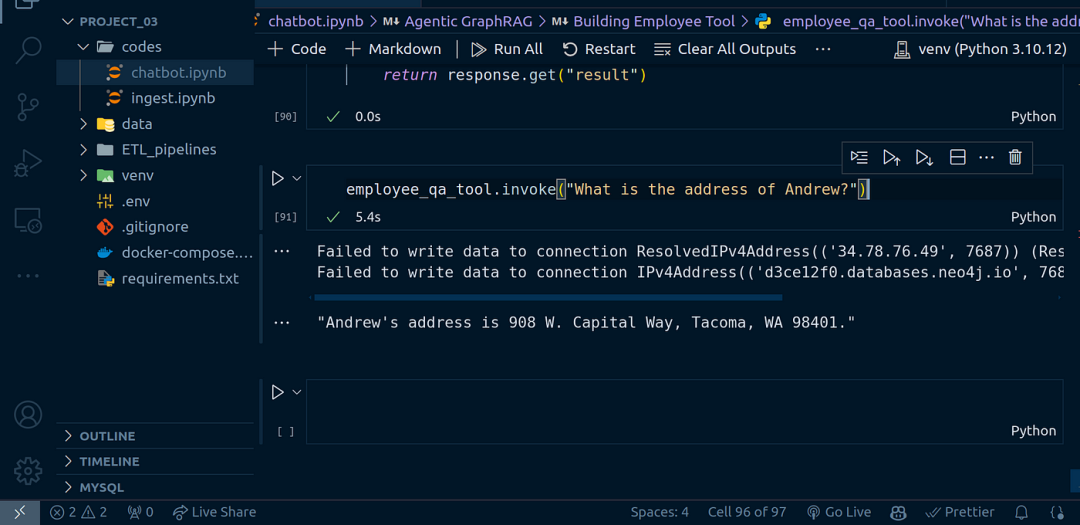
图片来源:Code With Prince
“Andrew 的地址是 908 W. Capital Way, Tacoma, WA 98401。”
现在让我们继续构建 general_qa_tool。它将用于回答与员工无关的其他问题。您可以随意构建任意数量的工具,但请记住,工具越多,大语言模型在选择相关工具时可能越容易感到困惑。
@tool("general-qa-tool", return_direct=True)
def general_qa_tool(query: str) -> str:
"""回答订单、订单详情、托运人、客户和产品相关问题的工具。"""
response = cypher_chain.invoke(query)
return response.get("result")
您可以如下调用该工具:
general_qa_tool.invoke("数据库中最贵的产品是什么?")
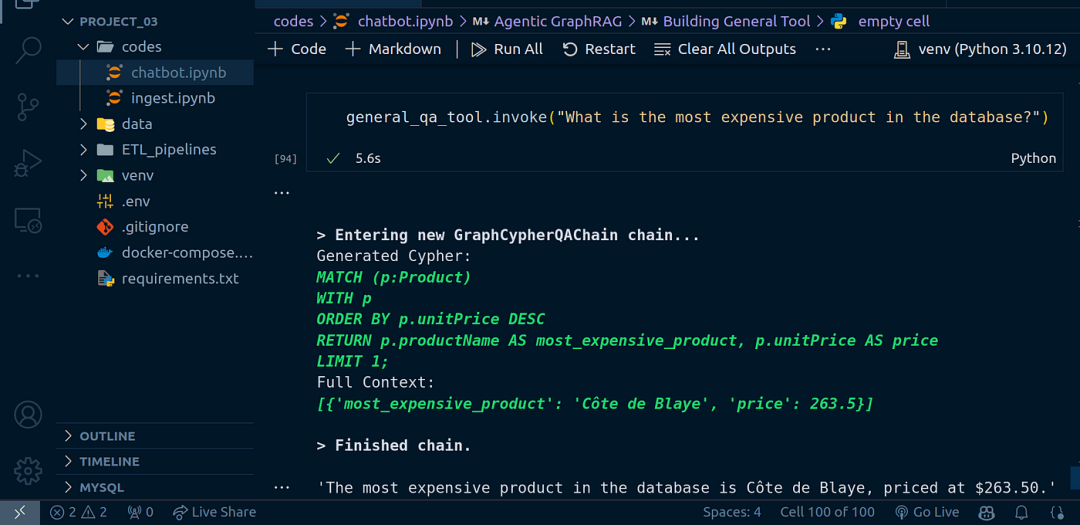
图片来源:Code With Prince
“数据库中最贵的产品是 Côte de Blaye,价格为 $263.50。”
使用 Neo4j 实现 GraphRAG 智能体
现在我们可以如下实现 GraphRAG 智能体。
首先引入我们需要使用的基础库:
from langchain import hub
from langchain.agents import (
AgentExecutor,
create_tool_calling_agent
)
接下来,从 LangChain Hub 加载智能体提示:
agent_prompt = hub.pull("hwchase17/openai-functions-agent")
创建工具列表,我们的例子中只有两个工具:
tools = [employee_qa_tool, general_qa_tool]
最后创建智能体!
llm = ChatOpenAI(model="gpt-3.5-turbo")
agent = create_tool_calling_agent(llm, tools, agent_prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
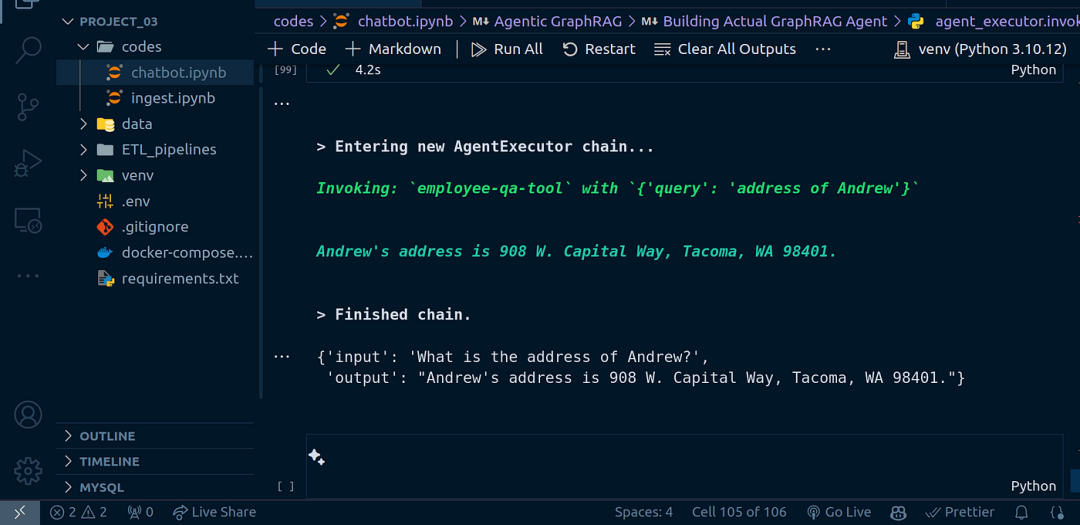
让我们测试一下,首先我想看看智能体是否选择了正确的工具。在这种情况下,我希望它使用 employee-qa-tool,让我们看看结果。
agent_executor.invoke(
{
"input": "Andrew 的地址是什么?"
}
)
图片来源:Code With Prince
是的,它确实选择了正确的工具并提供了正确的答案。
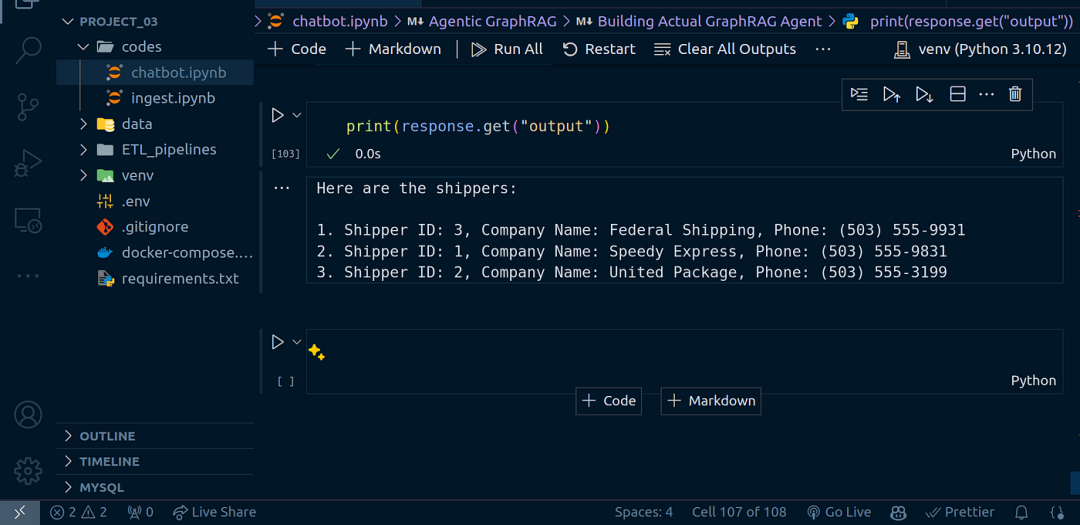
测试 2!这次我想问一个更常规的问题:
response = agent_executor.invoke(
{
"input": "提供每个托运人的详细信息以及他们运送了多少订单。"
}
)
print(response.get("output"))
生成的响应:
以下是托运人的信息:
1. 托运人 ID: 3,公司名称:Federal Shipping,电话:(503) 555–9931
2. 托运人 ID: 1,公司名称:Speedy Express,电话:(503) 555–9831
3. 托运人 ID: 2,公司名称:United Package,电话:(503) 555–3199
图片来源:Code With Prince
它并没有完全回答“每个托运人运送了多少订单”。无论如何,这就是智能体,它能够选择正确的工具。
图片来源:Code With Prince
这就是我们构建 AI 智能体所需的一切。
结论
恭喜您达成这一里程碑!您现在已经掌握了构建智能 GraphRAG 应用的基础知识,将图数据库的结构化能力与智能 AI 智能体结合起来。但这仅仅是我们旅程的开始。在下一期精彩内容中,我们将把这些概念带到生产环境中,通过以下方式:
-
• 使用 FastAPI 构建强大的后端 API 服务
-
• 使用 Docker 对解决方案进行容器化,实现无缝部署
-
• 创建干净且文档齐全的端点,允许其他应用程序利用我们的 GraphRAG 系统
-
• 实现可扩展性和安全性的最佳实践
准备好将您的实验代码转变为可以支持真实应用的生产级服务吧!无论您是构建内部工具还是面向客户的解决方案,您都将拥有一个专业级的 GraphRAG 系统,随时准备投入使用。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)