机器学习中的数据详解:数据类型、划分、属性等
机器学习中的数据详解:数据类型、划分、属性等
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
数据是机器学习领域的一个重要组成部分。它是指可用于训练机器学习模型的一组观察结果或测量结果。可用于训练和测试的数据的质量和数量在确定机器学习模型的性能方面起着重要作用。数据可以采用各种形式,例如数值、分类或时间序列数据,并且可以来自各种来源,例如数据库、电子表格或 API。机器学习算法使用数据来学习输入变量和目标输出之间的模式和关系,然后可用于预测或分类任务。
数据分类
数据通常分为两种类型:
- 标记数据
- 未标记的数据
标记数据包括模型试图预测的标签或目标变量,而未标记数据不包括标签或目标变量。机器学习中使用的数据通常是数值或分类数据。数值数据包括可以排序和测量的值,例如年龄或收入。分类数据包括代表类别的值,例如性别或水果类型。
数据可以分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的性能。确保数据以随机且具有代表性的方式分割非常重要。
数据预处理是机器学习流程中的重要步骤。此步骤可以包括清理和规范化数据、处理缺失值以及特征选择或工程。
数据:它可以是任何未经处理的事实、值、文本、声音或图片,未经解释和分析。数据是所有数据分析、机器学习和人工智能中最重要的部分。没有数据,我们就无法训练任何模型,所有现代研究和自动化都将徒劳无功。大企业正在花费大量资金只是为了收集尽可能多的特定数据。
例子: Facebook为何要花190亿美元的巨额代价收购WhatsApp?
答案非常简单且合乎逻辑——获取 Facebook 可能没有但 WhatsApp 拥有的用户信息。这些有关用户的信息对 Facebook 至关重要,因为它将有助于改进其服务。
**信息:**已经过解释和处理,并且对用户具有一些有意义的推论的数据。
**知识:**推断信息、经验、学习和见解的结合。可帮助个人或组织提高认识或构建概念。

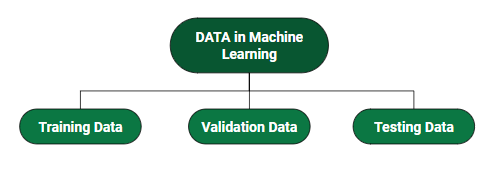
我们如何在机器学习中划分数据集?
- 训练数据:我们用来训练模型的数据部分。这是模型实际看到的数据(输入和输出)并从中学习。
- 验证数据:用于对模型进行频繁评估、拟合训练数据集以及改进相关超参数(模型开始学习之前最初设置的参数)的部分数据。这些数据在模型实际训练时发挥作用。
- 测试数据:一旦我们的模型训练完成,测试数据就会提供公正的评估。当我们输入测试数据时,我们的模型将预测一些值(无需查看实际输出)。预测之后,我们通过将其与测试数据中存在的实际输出进行比较来评估我们的模型。这就是我们评估和查看我们的模型从训练时设置的训练数据中输入的经验中学到了多少的方法。
考虑一个例子:
有一位购物中心老板进行了一项调查,他列出了一份长长的询问顾客的问题和答案清单,这份问题和答案清单就是数据。现在,每当他想要推断任何事情时,他无法从数千名顾客的每个问题中找出相关的东西,因为这样既费时又无益。为了减少这种开销和时间浪费,并使工作更轻松,他会根据自己的方便通过软件、计算、图表等方式对数据进行处理,从处理后的数据中得出的推断就是信息。所以,数据是信息的必需品。现在,知识在区分两个拥有相同信息的人方面发挥着作用。知识实际上不是技术内容,而是与人类的思维过程有关。
不同形式的数据
-
数字数据:如果特征表示以数字衡量的特性,则该特征称为数字特征。
-
分类数据:分类特征是一种属性,它基于某些定性特性,可以采用有限且通常固定数量的可能值之一。分类特征也称为名义特征。
-
序数数据:这表示一个名义变量,其类别按顺序排列。例如,服装尺码(如小号、中号和大号)或客户满意度的测量范围(从“一点也不满意”到“非常满意”)。
数据属性
- 数据量:数据的规模。随着世界人口和技术的不断增长,每毫秒都会产生大量数据。
- 多样性:不同形式的数据——医疗保健、图像、视频、音频剪辑。
- 速度:数据流和生成的速率。
- 价值:数据的意义,即研究人员可以从中推断出的信息。
- 真实性:我们正在处理的数据的确定性和正确性。
- 可行性:数据被使用并集成到不同系统和流程的能力。
- 安全性:为保护数据免遭未经授权的访问或操纵而采取的措施。
- 可访问性:获取和利用数据进行决策的便利性。
- 完整性:数据在整个生命周期内的准确性和完整性。
- 可用性:最终用户对数据的易用性和可解释性。
关于数据的一些事实:
- 与2005年相比,到2020年将产生300倍的数据,即40ZB(1ZB=10^21字节)。
- 到 2011 年,医疗保健行业的数据量达到 1610 亿千兆字节
- 每天约有 2 亿活跃用户发送 4 亿条推文
- 用户每月的视频流播放时间超过 40 亿小时。
- 用户每月分享300亿种不同类型的内容。
- 据报道,大约27%的数据是不准确的,因此三分之一的商业理想主义者或领导者不相信他们做出决策的信息。
上述事实只是实际存在的庞大数据统计的冰山一角。当我们谈论现实世界的情况时,当前存在和每时每刻产生的数据量超出了我们的思维范围,无法想象。
例子:
假设你在一家汽车制造公司工作,你想要建立一个模型,根据汽车重量和发动机尺寸预测汽车的燃油效率。在这种情况下,目标变量(或标签)是燃油效率,特征(或输入变量)是重量和发动机尺寸。你将收集不同车型的数据,以及相应的重量、发动机尺寸和燃油效率。这些数据都已标记,每辆车的格式为(重量、发动机尺寸、燃油效率)。准备好数据后,你将把它分成两组:训练集和测试集,训练集将用于训练模型,测试集将用于评估模型的性能。例如,可能需要进行预处理,以填充缺失值或处理可能影响模型准确性的异常值。
代码:
示例:1
# Example input data
from sklearn.linear_model import LogisticRegression
X = [[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]]
y = [0, 0, 1, 1, 1]
# Train a model
model = LogisticRegression()
model.fit(X, y)
# Make a prediction
prediction = model.predict([[6, 7]])[0]
print(prediction)
输出:
0,1
如果你运行我提供的代码,输出将是模型做出的预测。在这种情况下,预测将是 0 或 1,具体取决于模型在训练期间学习到的具体参数。
例如,如果模型了解到具有较高第二个元素的输入数据更有可能具有标签 1,则 [6, 7] 的预测将为 1。
优点或缺点
在机器学习中使用数据的优点
- 提高准确性:利用大量数据,机器学习算法可以学习输入和输出之间更复杂的关系,从而提高预测和分类的准确性。
- 自动化:机器学习模型可以自动化决策过程,并且可以比人类更高效、更准确地执行重复任务。
- 个性化:通过使用数据,机器学习算法可以为个人用户提供个性化体验,从而提高用户满意度。
- 节省成本:通过机器学习实现的自动化可以减少对人工的需求并提高效率,从而为企业节省成本。
在机器学习中使用数据的缺点
- 偏见:用于训练机器学习模型的数据可能会存在偏见,从而导致预测和分类出现偏见。
- 隐私:机器学习数据的收集和存储可能会引发隐私问题,如果数据没有得到妥善保护,则可能导致安全风险。
- 数据质量:用于训练机器学习模型的数据质量对于模型的性能至关重要。质量差的数据可能导致预测和分类不准确。
- 缺乏可解释性:一些机器学习模型可能很复杂且难以解释,因此很难理解它们如何做出决策。
机器学习的用途
机器学习是一种功能强大的工具,可用于广泛的应用。以下是机器学习的一些最常见用途:
- **预测模型:**机器学习可用于构建预测模型,该模型可以根据历史数据预测未来结果。这可用于许多应用,例如股票市场预测、欺诈检测、天气预报和客户行为预测。
- **图像识别:**机器学习可用于训练能够识别图像中的物体、面部和其他图案的模型。这用于许多应用,例如自动驾驶汽车、面部识别系统和医学图像分析。
- **自然语言处理:**机器学习可用于分析和理解自然语言,自然语言用于许多应用,例如聊天机器人、语音助手和情感分析。
- **推荐系统:**机器学习可用于构建推荐系统,根据用户过去的行为或偏好向用户推荐产品、服务或内容。
- **数据分析:**机器学习可用于分析大型数据集并识别人类难以或无法检测到的模式和见解。
- **机器人技术:**机器学习可用于训练机器人自主执行任务,例如在空间中导航或操纵物体。
机器学习中使用数据的问题:
- **数据质量:**在机器学习中使用数据的最大问题之一是确保数据准确、完整且能够代表问题领域。低质量的数据可能导致模型不准确或有偏差。
- **数据量:**在某些情况下,可能没有足够的数据来训练准确的机器学习模型。对于需要大量数据来准确捕捉所有相关模式和关系的复杂问题尤其如此。
- **偏见与公平:**如果训练数据存在偏见或不具代表性,机器学习模型有时会延续偏见和歧视。这可能会导致某些群体(如少数群体或女性)的不公平结果。
- **过度拟合和欠拟合:**当模型过于复杂,与训练数据的拟合过于紧密时,就会发生过度拟合,导致对新数据的泛化能力较差。当模型过于简单,无法捕捉数据中的所有相关模式时,就会发生欠拟合。
- **隐私和安全:**机器学习模型有时可用于推断个人或组织的敏感信息,从而引发对隐私和安全的担忧。
- **可解释性:**某些机器学习模型(例如深度神经网络)可能难以解释和理解,因此很难解释其预测和决策背后的原因。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 30
30 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)