【毕业设计】基于机器学习的水下海洋生物识别系统 深度学习 目标检测 Python
毕业设计:水下海洋生物识别数据集涵盖了多种水下生物的类别,包括鳗鱼、鱼类、海蜇、狮子鱼和龙虾。图像经过精细标注,确保每种生物的边界框和类别信息准确无误。系统能够在实际应用中有效应对复杂的水下场景。通过精心准备和划分数据集,并对模型进行详细配置和训练,我们能够有效地提升其识别能力。在训练完成后,系统通过评估指标(如平均精度均值、精确率和召回率)验证模型的泛化能力,并在推理阶段实现实时识别和可视化展示
一、背景意义
随着全球海洋生态环境的日益恶化和水下生物多样性的减少,保护海洋生态系统成为了全球关注的重要议题。水下生物识别系统的开发,能够帮助科学家和保护组织实时监测海洋生物的种类和数量,从而为海洋保护提供科学依据。传统的水下生物监测方法往往依赖于人工观察和记录,不仅耗时耗力,而且容易受到观察者主观因素的影响。显著提高水下生物监测的效率,减少人工观察的时间和成本,使科学研究和生态保护工作更为高效和精准。其次,通过建立包含多种水下生物的分类数据集(如鳗鱼、海蜇、狮子鱼、龙虾等),该系统不仅可以为海洋生物多样性研究提供数据支持,还可以帮助识别和监测入侵物种,从而为生态恢复和管理提供科学依据。
二、数据集
2.1数据采集
首先,需要大量的水下海洋生物图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示水下海洋生物特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在使用LabelImg标注水下海洋生物识别数据集的过程中,标注者面临着显著的复杂性和工作量。数据集包含多种生物类型,如鳗鱼、鱼类、海蜇、狮子鱼和龙虾,且图像中存在不同的光照和背景条件,增加了识别的难度。每张图像的标注不仅要求标注者具备专业知识,还需仔细观察以确保准确框选目标,这使得标注过程显得尤为繁琐。
标注完成后,反复验证与修正是必不可少的步骤,以确保每个框的准确性和一致性。这一过程不仅耗时,还对标注者的耐心和专注力提出了高要求。标注者需要在多样化的生物类别中保持分类的一致性,进一步提高了工作难度。整体来看,标注水下生物数据集是一项复杂且劳动密集的任务,需要投入大量的时间和精力以保证数据集的高质量。

包含419张观赏鱼图片,数据集中包含以下几种类别
- 鳗鱼:身体细长,属于一类水生动物。
- 鱼:水中生物,通常有鳞片和鳍,呼吸通过鳃进行。
- 水母:海洋生物,透明或半透明的浮游生物。
- 狮子鱼:身上有美丽纹饰的海洋鱼类。
- 龙虾:甲壳类水生动物,有钳子和长触须。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
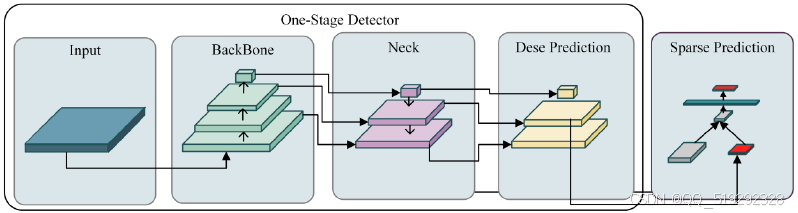
在选择水下海洋生物识别的目标检测模型时,首先需要综合考虑模型的三个主要组成部分:骨干网络、颈部模块和检测头。
- 骨干网络:推荐使用基于CNN的模型,如ResNet或MobileNet,它们在特征提取方面性能卓越且已在大型数据集上进行了预训练,能够有效减少训练时间并提高检测精度。由于水下生物可能在不同光照和背景条件下出现,选择一个具有强大特征提取能力的骨干网络至关重要,以确保系统能够准确识别鳗鱼、海蜇、狮子鱼、龙虾等目标。
- 颈部模块:需选用能够增强不同尺度目标感知的模块,如空间金字塔网络(SPPNet)或感受野模块(RFB)。这些模块能够有效处理水下环境中目标的尺度变化和遮挡问题,提升模型的定位与识别能力。
- 检测头:考虑采用稀疏预测类型的检测头,如Faster R-CNN,这种模型适合需要精细分类和位置调整的任务。通过非极大值抑制(NMS)操作,该检测头能够高效去除冗余的候选框,确保最终输出准确地反映水下生物的真实位置和类别。
在水下海洋生物识别系统中,采用注意力机制的主要原因在于其能够显著提升模型对关键特征的关注能力。水下环境通常具有复杂的背景和多变的光照条件,这使得生物的外观可能与周围环境产生融合。注意力机制通过动态调整模型对输入特征的关注程度,使其能够更有效地识别出鳗鱼、海蜇、狮子鱼和龙虾等目标。这种技术能够帮助模型在处理图像时自动聚焦于重要区域,从而提高检测的准确性和鲁棒性。
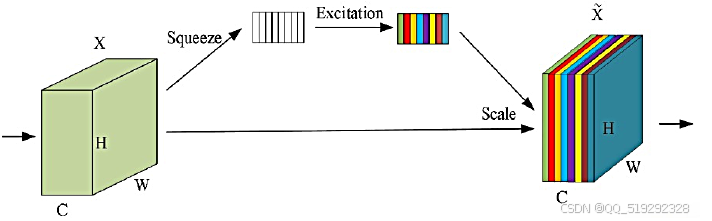
注意力机制还可以增强模型的上下文理解能力,帮助其在面对遮挡或局部信息不足的情况下做出更准确的判断。在水下生物识别中,生物可能由于水流、光线变化或其他生物的遮挡而部分显现。通过引入注意力机制,模型能够在不同的上下文环境中合理推测目标的存在与特征,从而提高生物识别的整体性能。
3.2模型训练
1. 模型配置
在水下海洋生物识别系统的开发过程中,模型配置是至关重要的一步,涉及多个方面以确保目标检测模型的有效运行。首先,数据集配置需要明确训练集和验证集的路径、类别数量以及类别名称,这为模型提供了必要的上下文信息,帮助其准确识别目标生物。其次,选择合适的YOLO版本(如YOLOv5)和相应的模型架构是关键,这将直接影响模型的速度和准确性。此外,训练超参数的设置,包括批处理大小、学习率和训练轮次,需根据数据集的特征进行调整,以优化训练效果。同时,其他配置选项如数据增强、损失函数和优化器的选择也至关重要,这些设置可以提高模型在复杂水下环境中的鲁棒性和准确性。
# yolo_config.yaml
# YOLOv5配置文件示例
train: ../data/train/images # 训练图像路径
val: ../data/val/images # 验证图像路径
nc: 5 # 类别数
names: ['eel', 'fish', 'jellyfish', 'lionfish', 'lobster'] # 类别名称
# 模型配置
model:
architecture: 'yolov5s' # 使用的YOLO模型版本
input_size: 640 # 输入图像尺寸
batch_size: 16 # 批处理大小
learning_rate: 0.001 # 学习率2. 模型训练
使用YOLO提供的训练脚本,通过指定配置文件、数据集路径和其他参数来启动训练。训练脚本通常会包含如图像尺寸、批处理大小、学习率和训练轮次等超参数的设置。合理的超参数选择能够显著提高模型的收敛速度和最终性能。训练期间,可以使用TensorBoard等工具实时监控训练过程中的损失变化和精度提升。这一过程可以帮助开发者及时调整超参数,避免过拟合或欠拟合的情况。
import torch
# 设置训练参数
data_config = 'yolo_config.yaml'
model_config = 'yolov5s.yaml' # YOLO模型配置文件
weights_path = 'yolov5s.pt' # 预训练权重路径
# 训练YOLO模型
!python train.py --img 640 --batch 16 --epochs 50 --data {data_config} --cfg {model_config} --weights {weights_path}3. 模型评估
模型评估流程包括对训练好的YOLO模型在未见数据上的性能检验,主要通过计算平均精度均值(mAP)、精确率和召回率等指标来评估模型的泛化能力。首先,使用验证集或测试集进行评估,记录模型在不同类别上的检测效果。评估结果可以帮助开发者识别模型的优缺点,针对性地进行优化,如调整训练数据、改进数据增强策略或优化网络参数。
# 导入所需库
import cv2
import numpy as np
# 加载YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
# 读取测试图像
img = cv2.imread('test_image.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 推理
results = model(img)
# 解析结果
results.print() # 打印检测结果
results.show() # 显示检测结果
results.save('output/') # 保存结果到文件四、总结
水下海洋生物识别系统旨在利用YOLO目标检测模型,准确识别和分类鳗鱼、鱼类、海蜇、狮子鱼和龙虾等水下生物,以促进生态保护和科学研究。通过精心准备和划分数据集,并对模型进行详细配置和训练,我们能够有效地提升其识别能力。在训练完成后,系统通过评估指标(如平均精度均值、精确率和召回率)验证模型的泛化能力,并在推理阶段实现实时识别和可视化展示。整体而言,该系统不仅展现了强大的实用性,也为海洋生态监测提供了重要工具,未来有望在保护海洋生态方面发挥更大作用。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 40
40 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)