基于YOLOv5+OpenPose的行人摔倒检测系统
💗博主介绍:✨全网粉丝10W+,CSDN特邀作者、博客专家、CSDN新星计划导师,专注于Java/Python/小程序app/深度学习等计算机设计,主要对象是咱们计算机相关专业的大学生,希望您们都能前途无量!✨💗👇🏻 精彩专栏 推荐订阅👇🏻计算机毕业设计设计精品实战案例✅🎈1.项目内容基于YOLOv5和OpenPose的行人摔倒检测系统是一种结合了目标检测与人体姿态估计技术的智能化解
收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
💗博主介绍:✨全网粉丝10W+,CSDN特邀作者、博客专家、CSDN新星计划导师,专注于Java/Python/小程序app/深度学习等计算机设计,主要对象是咱们计算机相关专业的大学生,希望您们都能前途无量!✨💗
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计设计精品实战案例✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
程序资料获取
🌟文末获取资料🌟
一、项目技术
环境:Python3.9、torch2.0.1、OpenCV4.8、Pycharm
二、项目内容和功能介绍
🎈1.项目内容
基于YOLOv5和OpenPose的行人摔倒检测系统是一种结合了目标检测与人体姿态估计技术的智能化解决方案。以下是对该系统的详细介绍:
技术背景
YOLOv5:这是一种实时目标检测模型,以其高精度和快速检测速度而闻名。它能够在复杂背景中准确识别出行人,为后续的姿态分析提供基础。
OpenPose:这是一个先进的实时人体关键点检测和全身姿态估计的深度学习框架。它能够同时识别并定位人体的25个关键点,包括面部、手部、脚部等,从而准确捕捉人体的姿态变化。
🎈2.功能介绍
模型:YOLOv5、OpenPose(YOLOv5检测目标,OpenPose识别体态)
1、需要熟悉并使用深度学习框架,如PyTorch或TensorFlow,以实现YOLOv5和OpenPose模型,进而了解YOLOv5、OpenPose模型的结构、工作原理和训练过程。
2、搜集数据集,这其中尽可能覆盖到各种场景、不同人员等。将收集到的数据集采取图像/视频的缩放、裁剪、归一化等操作,以及数据增强技术,如随机旋转、翻转、亮度调整等,以准备训练数据并提高模型的性能。
3、非常关键的一点是将YOLOv5和OpenPose模型集成到同一个系统中,并设计合适的数据流和处理流程。
4、由于行人摔倒检测通常需要实时性能,所以需要优化模型和算法以确保其在实时场景下的运行速度和准确性。
5、设计评估指标和方法来评估模型的性能,包括准确率、召回率、精确度等指标,以及使用验证和测试数据集进行性能评估。
6、使用Flask轻量级框架,开发出一个行人摔倒检测系统。方便用户直接在该系统实时监控判断行人是否处于安全站姿/摔倒的状态。
三、核心代码
部分代码:
from __future__ import division, print_function, absolute_import
import sys
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5 import QtWidgets
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
import numpy as np # 数据处理的库 numpy
import imutils
import cv2
from PIL import Image, ImageDraw, ImageFont
import time
import argparse
import torch
import cv2
import numpy as np
from torch import from_numpy, jit
from modules.keypoints import extract_keypoints, group_keypoints
from modules.pose import Pose
from action_detect.detect import action_detect
import os
from math import ceil, floor
import time
device = torch.device('cpu')
os.environ["PYTORCH_JIT"] = "0"
###========全局变量 定义开始=======###
# 打开的是摄像头还是本地视频
camera_or_local_flag = 0
# 识别进行中还是暂停识别中,1为摄像头,2位本地摄像头
Start_or_pause_flag = 0
dis_last = [0]*64 #list(range(64))
fcw = [0]*1
fps = 0.0
result_image = ...
writeVideo_flag = True
DISPLAY_W=1400 # 显示的宽度
DISPLAY_H=900 # 显示的高度
DISPLAY_RIGHT_W=200 # 右边按钮显示的宽度
SAVE_OUTPUT=1 #保存图像
one_enter=1
out=...
class ImageReader(object):
def __init__(self, file_names):
self.file_names = file_names
self.max_idx = len(file_names)
def __iter__(self):
self.idx = 0
return self
def __next__(self):
if self.idx == self.max_idx:
raise StopIteration
img = cv2.imread(self.file_names[self.idx], cv2.IMREAD_COLOR)
if img.size == 0:
raise IOError('Image {} cannot be read'.format(self.file_names[self.idx]))
self.idx = self.idx + 1
return img
class VideoReader(object):
def __init__(self, file_name,code_name):
self.file_name = file_name
self.code_name = str(code_name)
try: # OpenCV needs int to read from webcam
self.file_name = int(file_name)
except ValueError:
pass
def __iter__(self):
self.cap = cv2.VideoCapture(self.file_name)
if not self.cap.isOpened():
raise IOError('Video {} cannot be opened'.format(self.file_name))
return self
def __next__(self):
was_read, img = self.cap.read()
if not was_read:
raise StopIteration
# print(self.cap.get(7),self.cap.get(5))
cv2.putText(img,self.code_name, (5,35),
cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 255))
return img
def normalize(img, img_mean, img_scale):
img = np.array(img, dtype=np.float32)
img = (img - img_mean) * img_scale
return img
def pad_width(img, stride, pad_value, min_dims):
h, w, _ = img.shape
h = min(min_dims[0], h)
min_dims[0] = ceil(min_dims[0] / float(stride)) * stride
min_dims[1] = max(min_dims[1], w)
min_dims[1] = ceil(min_dims[1] / float(stride)) * stride
pad = []
pad.append(int(floor((min_dims[0] - h) / 2.0)))
pad.append(int(floor((min_dims[1] - w) / 2.0)))
pad.append(int(min_dims[0] - h - pad[0]))
pad.append(int(min_dims[1] - w - pad[1]))
padded_img = cv2.copyMakeBorder(img, pad[0], pad[2], pad[1], pad[3],
cv2.BORDER_CONSTANT, value=pad_value)
return padded_img, pad
def infer_fast(net, img, net_input_height_size, stride, upsample_ratio, cpu,
pad_value=(0, 0, 0), img_mean=(128, 128, 128), img_scale=1/256):
height, width, _ = img.shape
scale = net_input_height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [net_input_height_size, max(scaled_img.shape[1], net_input_height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float().to(device)
if not cpu:
#tensor_img = tensor_img.cuda().to(device)
tensor_img = tensor_img.to(device)
stages_output = net(tensor_img)
# print(stages_output)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
四、效果图
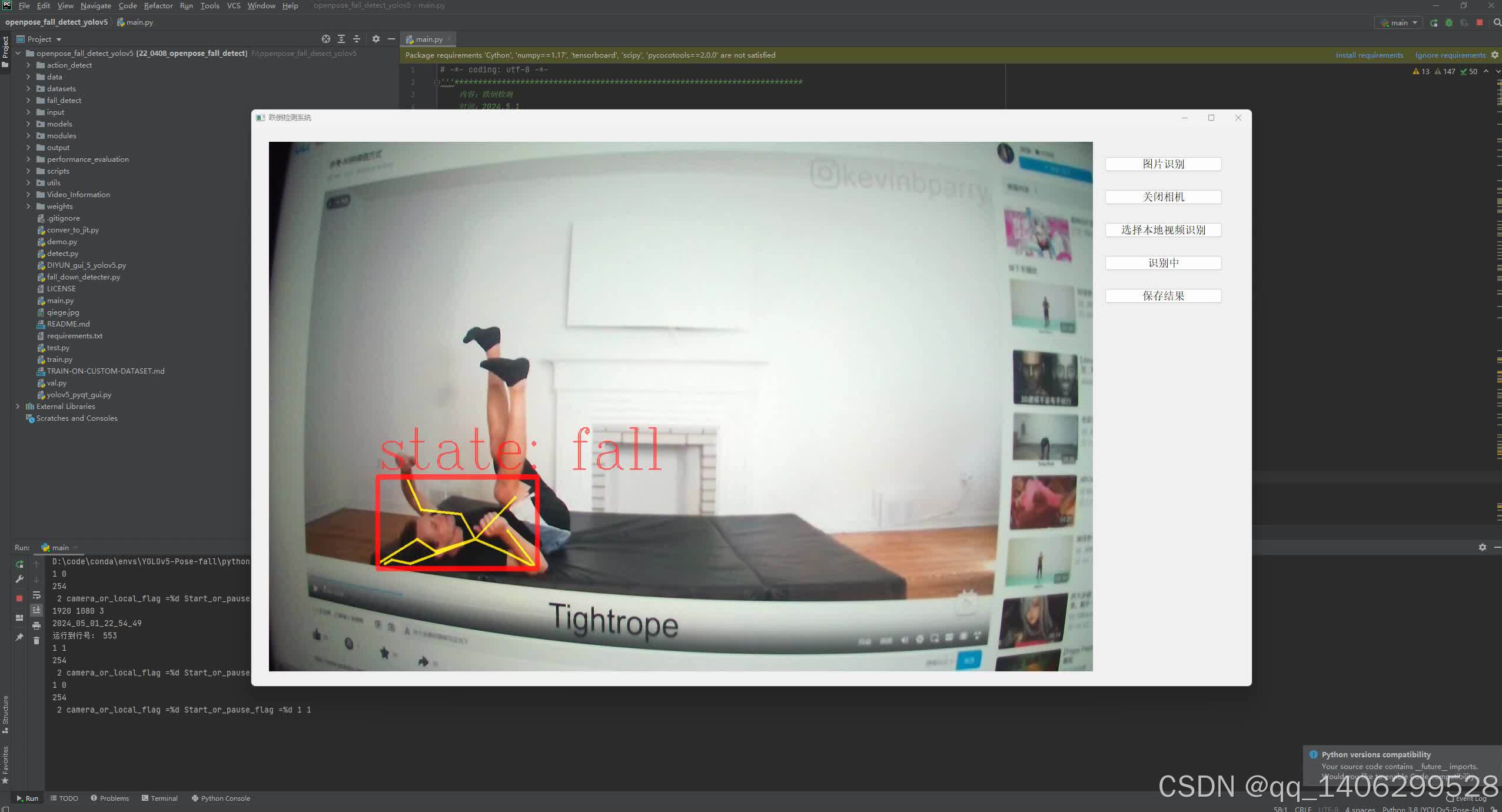
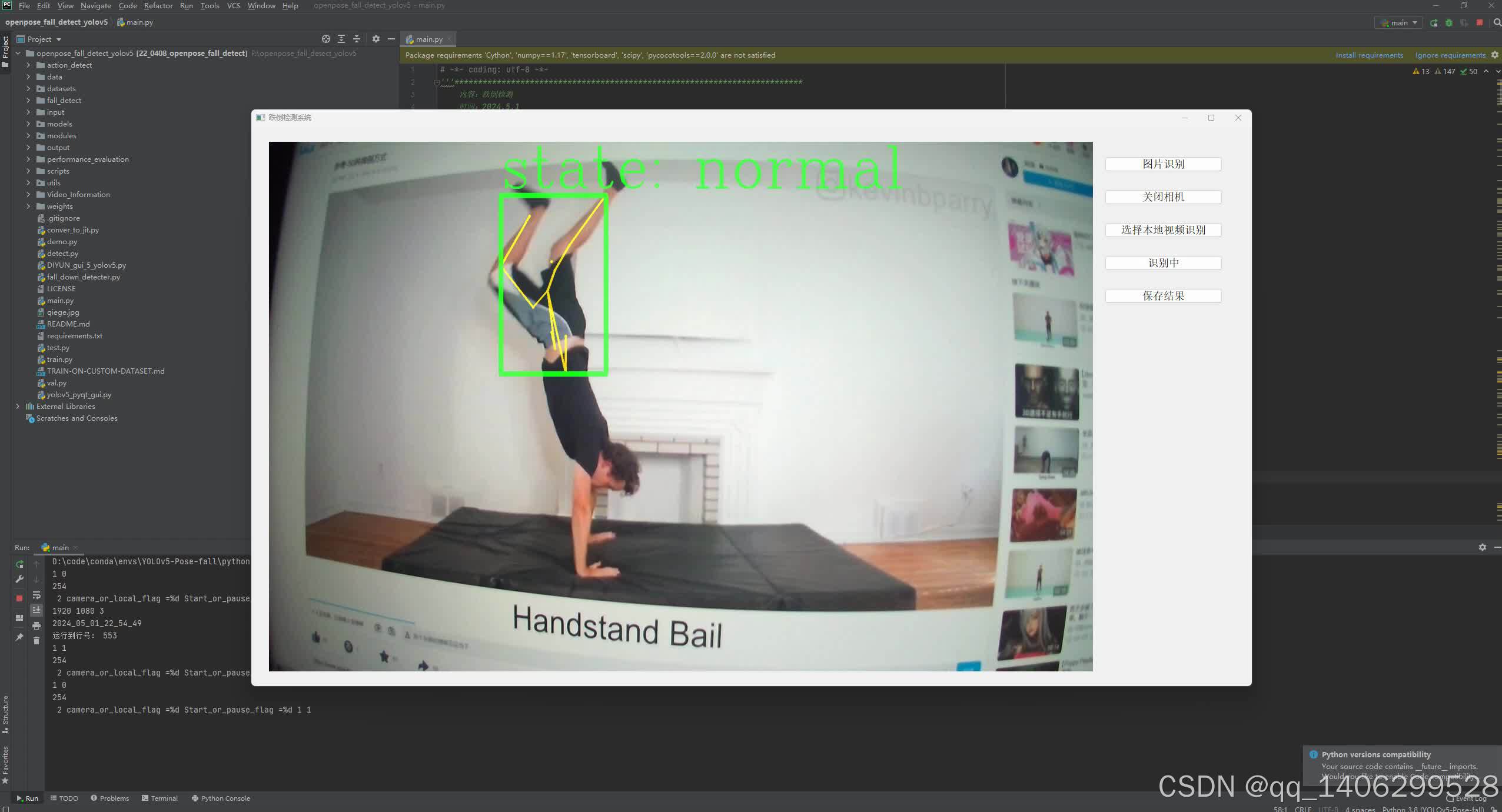
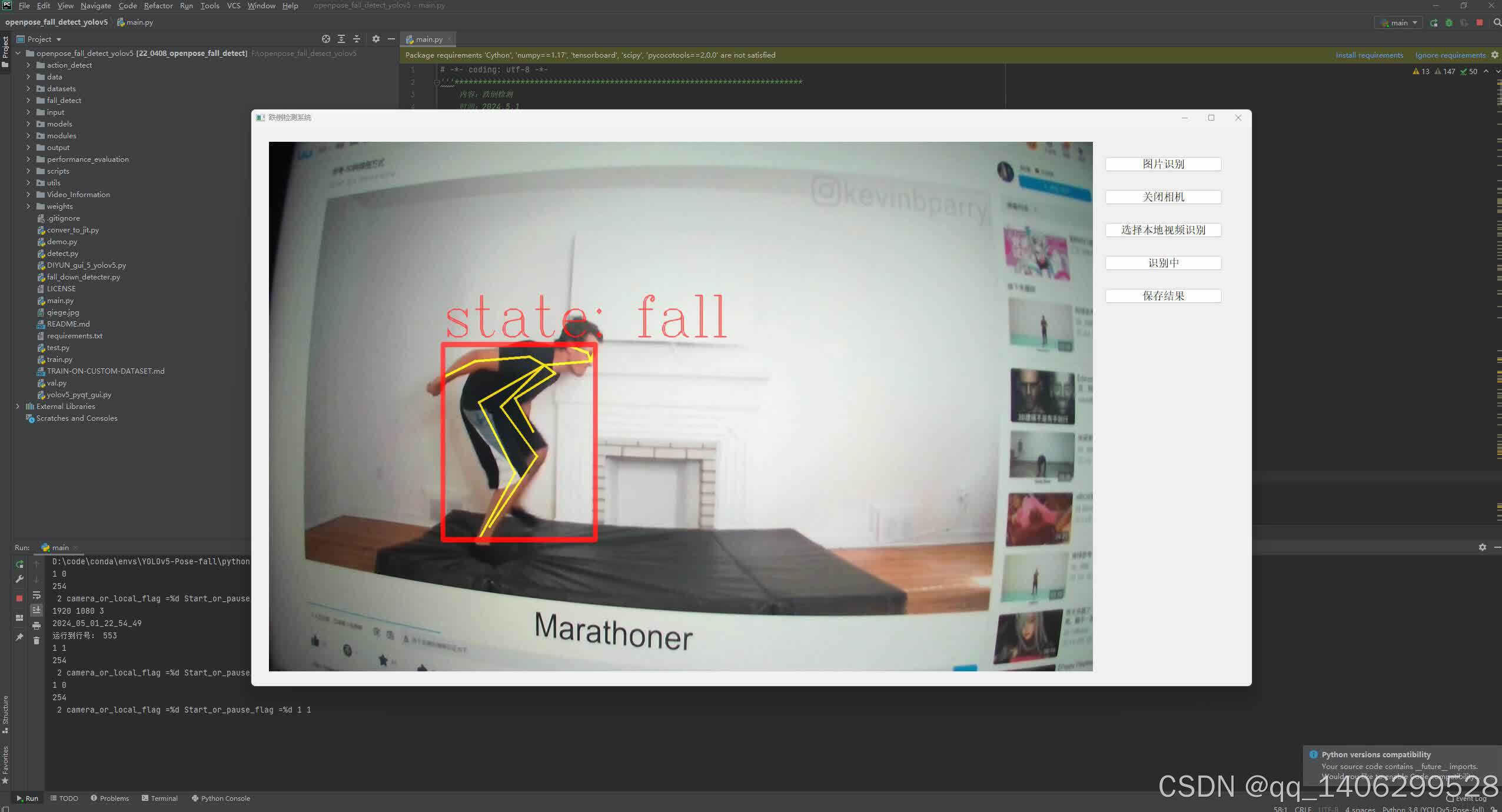
五 、资料获取
文章下方名片联系我即可~
精彩专栏推荐订阅:在下方专栏👇🏻
毕业设计精品实战案例
收藏关注不迷路!!
🌟文末获取设计🌟

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 22
22 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)