[NeurIPS]Exploitation of a Latent Mechanism in Graph Contrastive Learning: Representation Scattering
计算机-人工智能-图对比学习表征散射

论文代码:https://github.com/hedongxiao-tju/SGRL
目录
2.4. Representation Scattering in GCL
2.5.1. Representation Scattering Mechanism (RSM)
2.5.2. Topology-based Constraint Mechanism(TCM)
1. 心得
(1)额~不太是我的方向
2. 论文逐段精读
2.1. Abstract
①They proposed Scattering Graph Representation Learning (SGRL)
2.2. Introduction
①Representation scattering is the same crutial factor in node discrimination, group discrimination, bootstrapping schemes
②Existing works do not fully utilize the mechanism of representation scattering, some of them just employ batch norm
2.3. Preliminary
①Graph setting: , where
is node set,
is edge set
②Feature matrix: ,
denotes the number of nodes,
is the feature dimension
③Adjacency matrix: binarized
④Degree matrix: , each element
⑤Degree normalized adjacency matrix:
2.4. Representation Scattering in GCL
①Definition of representation scattering: in a -dimensional embedding space
comprising
vectors organized into a matrix
, consider a subspace
of
and a scatter center
. there are 2 constraint:
| Center-Away Constraint: Node representations are encouraged to be distant from the scattered center |
| Uniformity Constraint: Node representations are uniformly distributed over the subspace |
2.4.1. DGI-like methods
①DGI-like methods employ mutual information discriminator to maximizes the mutual information between nodes and their source graphs to train the model
②Assumption: a) for normalized propagation matrix where
, b) DGI generates the corrupted graph by randomly shuffling the entities in the feature matrix
and keeping adjacency matrix
unchanged, c) the orginal data are class-balanced (the numbers are SAME)
③Theorem: At the node level, minimizing the DGI loss is equivalent to maximizing the Jensen Shannon (JS) divergence between the local semantic distribution in the original graph and its average distribution (corrupted grpah
), i.e.
④Single layer GNN:
where ,
with
is activation function,
is first order neighbors of node
⑤Mean of aggregated representation :
⑥Variance of aggregated representation :
⑦The mean and variance of representation 's distribution:
/
,
⑧Randomly extract feature vectors from original graph
with distribution
,
⑨Corollary: the mean of original graph as center , original representation space as subspace
⑩t-SNE embedding of DGI on Co.CS dataset:

where blue and red points are negative and positive samples
Corollary n. 推论;必然的结果
2.4.2. InfoNCE-based methods
①Theorem: define ,
be the cosine similarity function. For node
, the lower bound of InfoNCE loss is:
however, it's inefficient due to calculating of every representation pair
2.4.3. BGRL-like methods
①Batch normalization for a feature vector :
where and
are mean and variance,
and
are learnable scale and shift parameters,
is a small constant
②The impact of Batch Normalization in BGRL:
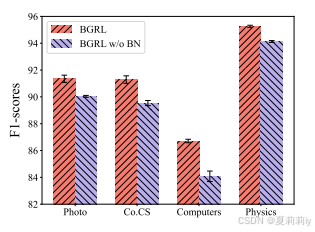
2.5. Methodology
①The overall framework of SGRL:
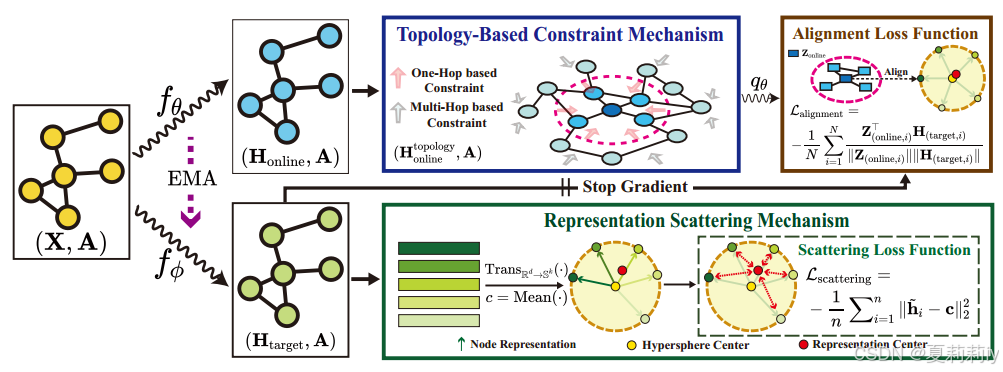
2.5.1. Representation Scattering Mechanism (RSM)
①Apply to transform
to
with L2 norm each row:
where generated by target encoder,
,
is a small vale to avoid division by zero
②Scattering center:
2.5.2. Topology-based Constraint Mechanism(TCM)
①For connected , there is a threshold
, and
②Topology connection:
③Topology-based Constraint Mechanism (TCM)
where denotes the order of neighbors
④Prediction:
⑤Aim: align with
⑥Alignment loss:
⑦Employ Exponential Moving Average at the end of each training epoch:
where is target decay rate
2.6. Experiment
①5 datasets: AmazonPhoto (Photo) and Amazon-Computers (Computers), WikiCS, Coauthor-CS (Co.CS), Coauthor-Physics (Co.Physics)
②⭐Data split: 10% for training and 90% for testing
③Running times: 20
2.6.1. Performance Analysis
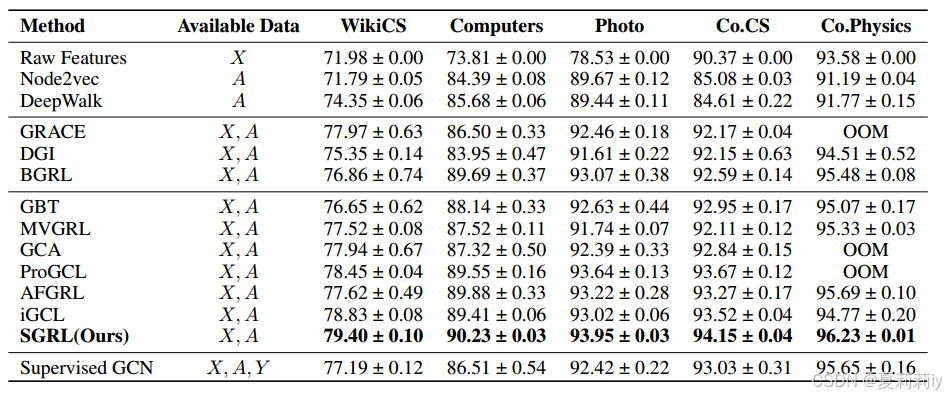
①Node classification performance table:
②t-SNE visualization on CS dataset:

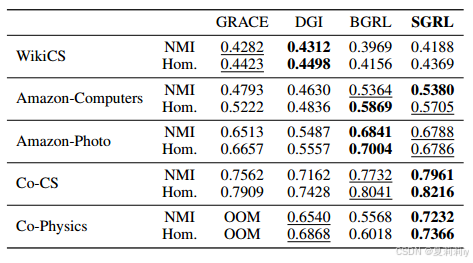
③Performance on Clustering in terms of NMI and homogeneity. Optimal results are shown in bold and suboptimal results are underlined:
2.6.2. Model Analysis
①The ablation of :
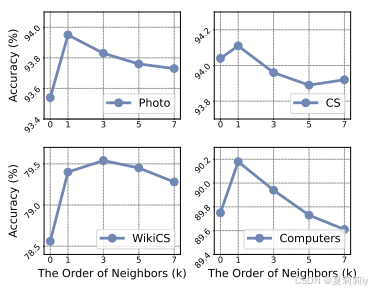
②Module ablation:

2.7. Conclusion
~
3. Reference
He, D. et al. (2024) 'Exploitation of a Latent Mechanism in Graph Contrastive Learning: Representation Scattering', NeurIPS.

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 19
19 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)