【毕业设计】基于机器学习的白细胞识别分类 人工智能 深度学习 计算机视觉 数据集 YOLO
毕业设计:白细胞检测数据集专为显微镜下白细胞识别与分类而设计,涵盖了多种类型的白细胞图像,包括淋巴细胞、单核细胞和嗜酸性粒细胞。每张图像经过精确标注,确保数据的高质量和多样性,为深度学习模型提供了坚实的训练基础。数据集主要分为训练集和验证集,便于模型在训练过程中进行效果评估。通过高效的目标检测框架(如YOLOv5),模型能够快速识别不同类型的白细胞,从而支持临床医生的诊断决策。
一、背景意义
白细胞是人体免疫系统的重要组成部分,负责抵御感染和疾病。白细胞计数及分类是临床常规检查的重要项目,能够帮助医生诊断各种疾病,包括感染、炎症、免疫系统疾病及血液疾病等。然而,传统的白细胞检测方法通常依赖于显微镜下的人工观察,这一过程既耗时又容易受到主观因素的影响,导致结果的不准确性。随着深度学习和计算机视觉技术的快速发展,自动化的白细胞检测系统逐渐成为可能。利用深度学习模型对血液图像中的白细胞进行自动识别和分类,可以提高检测效率和准确性,减轻医生的工作负担。
二、数据集
2.1数据采集
首先,需要大量的白细胞类图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示白细胞类特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在使用LabelImg标注白细胞数据集的过程中,标注任务的复杂性和工作量非常庞大。首先,用户需要处理大量显微镜下的白细胞图像,这些图像可能存在不同的光照条件、背景杂音和细胞形态,增加了标注的难度。使用LabelImg时,用户必须逐张仔细观察,准确绘制出白细胞的边界框,并确保标签的一致性和准确性。此外,由于数据集中只有白细胞这一类别,用户需要在细致的分析中保持高度集中,任何小的判断失误都可能影响后续模型的训练效果。整个标注过程不仅耗时且繁琐,可能需要数天甚至数周才能完成,完成后还需进行严格的质量检查,以确保每个标签的有效性和可靠性。
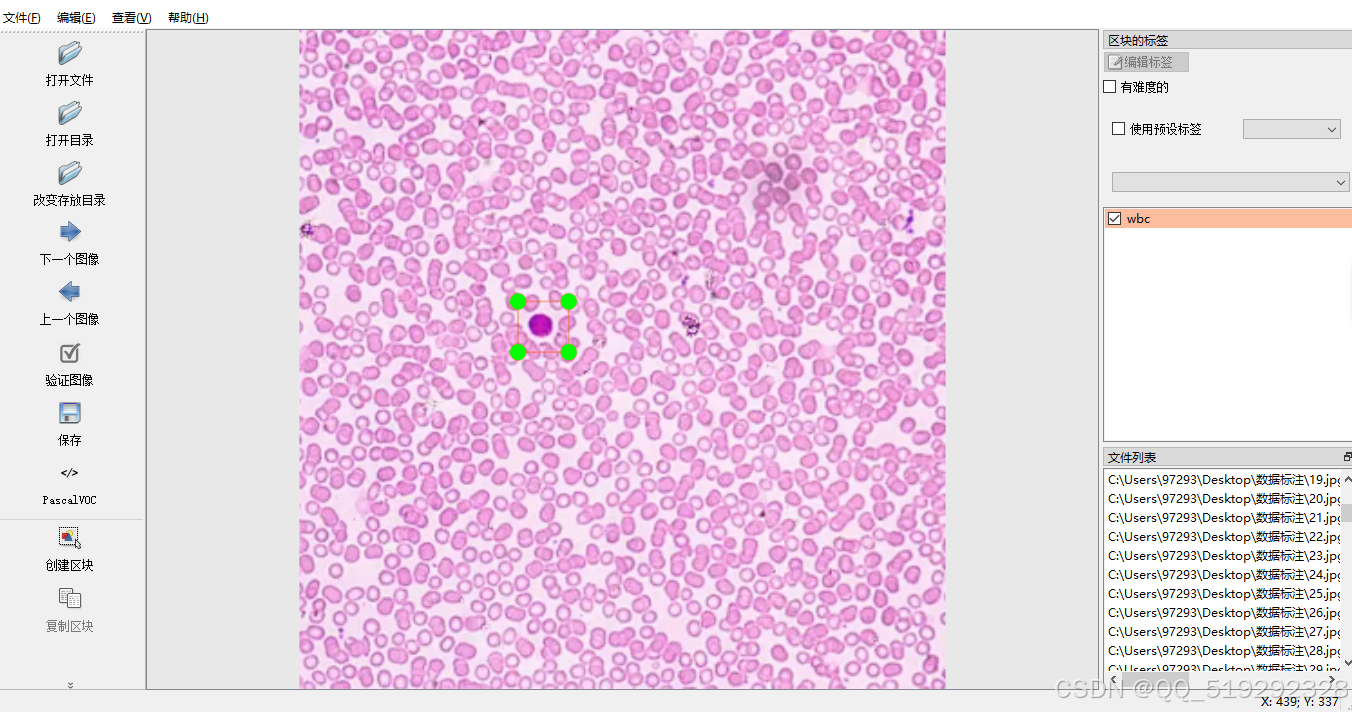
包含2386张白细胞图片,数据集中包含以下几种类别
- 白细胞:表示检测到的免疫系统细胞,其功能是抵御感染和疾病。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是基于生物过程的结构设计,仿照动物视觉皮层的组织方式。CNN的结构灵感来源于视觉感知,其中生物神经元与人工神经元相对应,神经元之间的连接方式模拟了生物神经网络的特性。CNN的内核响应多种特征,通过修改输入信号来改变输出,从而实现控制目的。激活函数在此过程中起到关键作用,模拟了只有当神经电信号超过某一阈值时,信息才会传递给下一神经元的特性。此外,损失函数和优化器是人为设计的工具,用于调整CNN系统,以便研究和优化预期的输出结果。与传统特征提取方法不同,CNN能够自动从数据中提取重要特征,无需人工干预,作为一种前馈神经网络和多层感知器,CNN通过卷积结构有效地提取和学习数据特征,从而在图像识别和其他任务中表现出色。
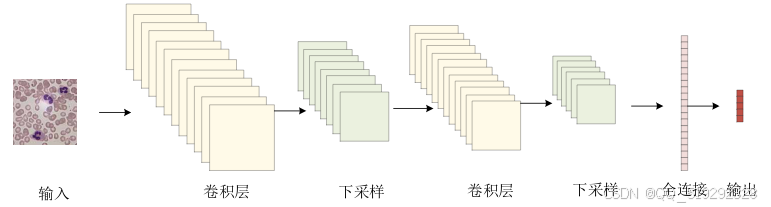
卷积神经网络(CNN)在白细胞识别中具有显著优势,主要体现在自动特征提取、高效处理复杂数据和对平移不变性的适应能力。CNN能够自动从图像中捕捉白细胞的形态、大小和颜色等特征,无需人工干预,从而提高识别的准确性和效率。其多层结构使其能够有效处理复杂背景,并实现多尺度特征分析,增强对不同尺寸白细胞的识别能力。此外,CNN在大量标注数据的支持下,能够通过深度学习算法持续优化,达到高识别准确率,减少误诊风险。随着计算能力的发展,现代CNN还具备实时处理能力,适应多样化的临床需求,并能够针对特定白细胞类型进行专门训练,进一步优化识别效果。
3.2模型训练
白细胞检测系统旨在通过深度学习技术,准确识别并分类显微镜下的白细胞类型。首先,环境配置是基础,确保系统能够顺利运行YOLOv5模型。通过以下步骤,可以快速设置好开发环境。首先,克隆YOLOv5代码库并安装所需依赖项,确保计算机具备GPU支持以加速训练过程。
# 克隆YOLOv5代码库
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
# 安装所需的依赖项
pip install -r requirements.txt
# 验证CUDA支持(可选)
python -c "import torch; print(torch.cuda.is_available())"
接下来,准备高质量的数据集是关键。数据集应包含多种类型的白细胞图像,如淋巴细胞、单核细胞和嗜酸性粒细胞,并经过精确标注。为了提高模型的泛化能力,数据集需划分为训练集和验证集,确保每个图像都有对应的标签文件。数据集的目录结构应如下所示:
/data
/train
/images
/labels
/val
/images
/labels
在完成数据准备后,选择合适的YOLO模型并创建自定义配置文件,定义白细胞的类别。然后,通过命令行启动模型训练,监控训练损失和准确率。训练过程中的命令如下所示:
# 开始训练
python train.py --img 640 --batch 16 --epochs 50 --data custom_wbc.yaml --weights yolov5s.pt --name wbc_detection
训练完成后,使用验证集对模型进行评估,以检查其性能。评估过程中,可以使用以下命令获取模型的精确度和召回率等指标:
# 评估模型性能
python val.py --weights runs/train/wbc_detection/weights/best.pt --data custom_wbc.yaml --img 640
最后,训练好的模型可以用于实时推理,识别新图像中的白细胞。以下示例代码展示了如何加载模型并对待检测的图像进行推理:
import torch
import cv2
from pathlib import Path
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/wbc_detection/weights/best.pt')
# 读取待检测的图像
img_path = 'path/to/test/image.jpg'
img = cv2.imread(img_path)
# 推理
results = model(img)
# 可视化结果
results.show() # 显示推理结果
results.save(Path('results')) # 保存推理结果四、总结
白细胞检测系统利用深度学习技术,旨在实现显微镜下白细胞的自动识别与分类。该系统主要针对不同类型的白细胞,如淋巴细胞、单核细胞和嗜酸性粒细胞进行分析,为临床医学提供重要的支持。这项技术的核心在于通过高质量的数据集进行模型训练,以确保检测的准确性和可靠性。数据集的准备是系统开发的首要步骤,包含多种类型的白细胞图像,并经过精确标注。数据集主要分为训练集和验证集,为模型的训练和评估提供基础。通过使用YOLOv5等先进的目标检测框架,系统能够在多样的环境中快速识别白细胞,从而为医生提供及时的诊断信息。随着技术的不断进步,白细胞检测系统将发挥越来越重要的作用,助力于疾病的早期发现和治疗。该系统不仅提高了白细胞检测的效率,也为医学研究提供了新的数据支持,推动了临床诊断的科学化与自动化进程。通过整合深度学习与医学影像分析,白细胞检测系统将在未来的医疗健康管理中发挥重要作用。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)