Post-Training---ChatGPT4o作答+Hung-yi Lee:【生成式AI時代下的機器學習(2025)】第六講:生成式人工智慧的後訓練(Post-Training)與遺忘問題

后训练(Post-training)是指在机器学习模型训练完成后,进行一系列优化、调优、分析或应用的步骤。这些步骤通常包括模型评估、误差分析、参数调整、模型精简、以及应用模型的过程。后训练的目的是进一步提升模型的性能,确保其适应实际应用场景,并在部署阶段保持高效与稳定。
后训练的关键步骤
-
模型评估
训练完模型后,首先要评估模型在测试集上的表现。常用的评估指标包括:- 准确率 (Accuracy):预测正确的样本所占的比例。
- 精度 (Precision)、召回率 (Recall)、F1-score:特别适用于不平衡分类问题。
- AUC-ROC 曲线 (Area Under ROC Curve):用于二分类问题的评估。
- 均方误差 (MSE)、均方根误差 (RMSE):适用于回归问题。
评估的目的是了解模型是否泛化良好,是否过拟合或欠拟合,以及是否能够满足实际需求。
-
误差分析
对于模型在测试集上的误差进行深入分析是后训练的一个重要部分。通过分析误差,可以找出模型的弱点并进行改进:- 误分类分析:查看哪些样本被错误分类,是否存在某些类别的样本经常被误判。
- 误差可视化:通过图形化手段(如混淆矩阵、错误分类样本的分布图)进行分析。
- 关注边界案例:分析离决策边界较近的样本,看看它们为何被错误分类。
-
模型调优与超参数优化
训练完成后,模型可能依然存在优化空间,特别是超参数的选择对模型性能有着重要影响。后训练的调优包括:- 超参数调整:调整模型的超参数(例如,学习率、正则化强度、树的深度等)来提高模型性能。
- 网格搜索(Grid Search)或随机搜索(Random Search):对超参数空间进行穷举或随机搜索,找到最优超参数。
- 贝叶斯优化(Bayesian Optimization):使用贝叶斯优化方法在较小的样本空间内智能地找到最优的超参数。
-
模型精简与优化
在某些应用场景中,模型的计算效率非常重要,后训练的一部分内容就是对模型进行精简,使其更高效:- 剪枝(Pruning):对决策树、神经网络等模型进行剪枝,以减少模型的复杂性和计算成本。
- 量化(Quantization):通过减少模型中数值的精度来减少内存占用。
- 知识蒸馏(Knowledge Distillation):将一个复杂模型(教师模型)训练为一个较小的模型(学生模型)来提高推理速度。
- 低秩分解与特征选择:减少模型输入特征的维度,降低计算复杂度。
-
模型集成
通过将多个模型结合起来,后训练可以进一步提升模型的稳定性和泛化能力:- 集成方法(Ensemble Methods):如随机森林、梯度提升树(XGBoost),通过组合多个模型的预测来提高整体性能。
- 模型加权平均:通过加权平均不同模型的预测结果,改善模型的鲁棒性。
-
迁移学习与微调
迁移学习是将一个在大数据集上预训练的模型应用到一个相关任务的过程。后训练时,常常使用迁移学习对模型进行微调:- 冻结某些层:在深度学习中,常常冻结部分层,只训练最后几层,以适应新任务。
- 使用预训练模型:例如,使用预训练的VGG、ResNet等网络,在目标任务上进行微调,从而提高性能。
-
模型部署与监控
完成后训练后,模型需要被部署到生产环境中。这一过程包括:- 部署模型:将训练好的模型导出,并通过API或其他接口进行部署,使其能够在实际环境中接收实时数据并进行预测。
- 在线学习:有些应用要求模型能够不断接收新的数据并更新参数(增量学习)。
- 监控模型表现:部署后的模型需要不断监控其表现。如果发现模型在新数据上的效果下降(如性能退化或漂移),可能需要重新训练或调优。
-
解释性与可解释性
在许多应用场景中,尤其是在医疗、金融等领域,模型的可解释性是至关重要的。在后训练阶段,可以通过以下方式提升模型的透明度:- 特征重要性:通过算法(如决策树的特征重要性,LIME、SHAP等)来解释模型做出决策时各特征的作用。
- 可视化:使用热图、决策边界等可视化工具,帮助用户理解模型的工作原理。
后训练的重要性
后训练是机器学习过程中的一个重要环节,以下是一些理由,说明为什么后训练对模型的性能和实际应用至关重要:
- 优化与精简:通过后训练过程,能够使得模型的性能更好,计算效率更高,特别是在大规模数据和高维度问题中。
- 泛化能力提升:通过模型调优、集成和误差分析,可以有效提升模型在未知数据上的泛化能力。
- 解决过拟合/欠拟合:通过误差分析和超参数调整,可以减轻过拟合和欠拟合现象,使模型更具鲁棒性。
- 满足应用需求:后训练还可以根据实际需求对模型进行定制和优化,确保模型在具体任务中的适用性和效率。
后训练的常见挑战
- 数据质量问题:有时数据本身可能包含噪声或偏差,这会影响后训练过程。
- 计算资源:一些后训练操作(如超参数调优、模型集成)可能非常耗时,尤其是在深度学习中,需要大量计算资源。
- 过拟合问题:即使经过优化,某些模型仍然容易在训练数据上过拟合,影响其在实际数据中的表现。
- 模型更新与维护:随着时间推移,模型的性能可能下降,需要定期更新和重新训练。
总结
后训练是一个优化和调整机器学习模型的过程,包括模型评估、超参数调优、精简、部署等步骤,目的是确保模型在实际应用中的高效性、稳定性和可用性。通过有效的后训练策略,可以提升模型的泛化能力,减少计算开销,并更好地满足实际业务需求。
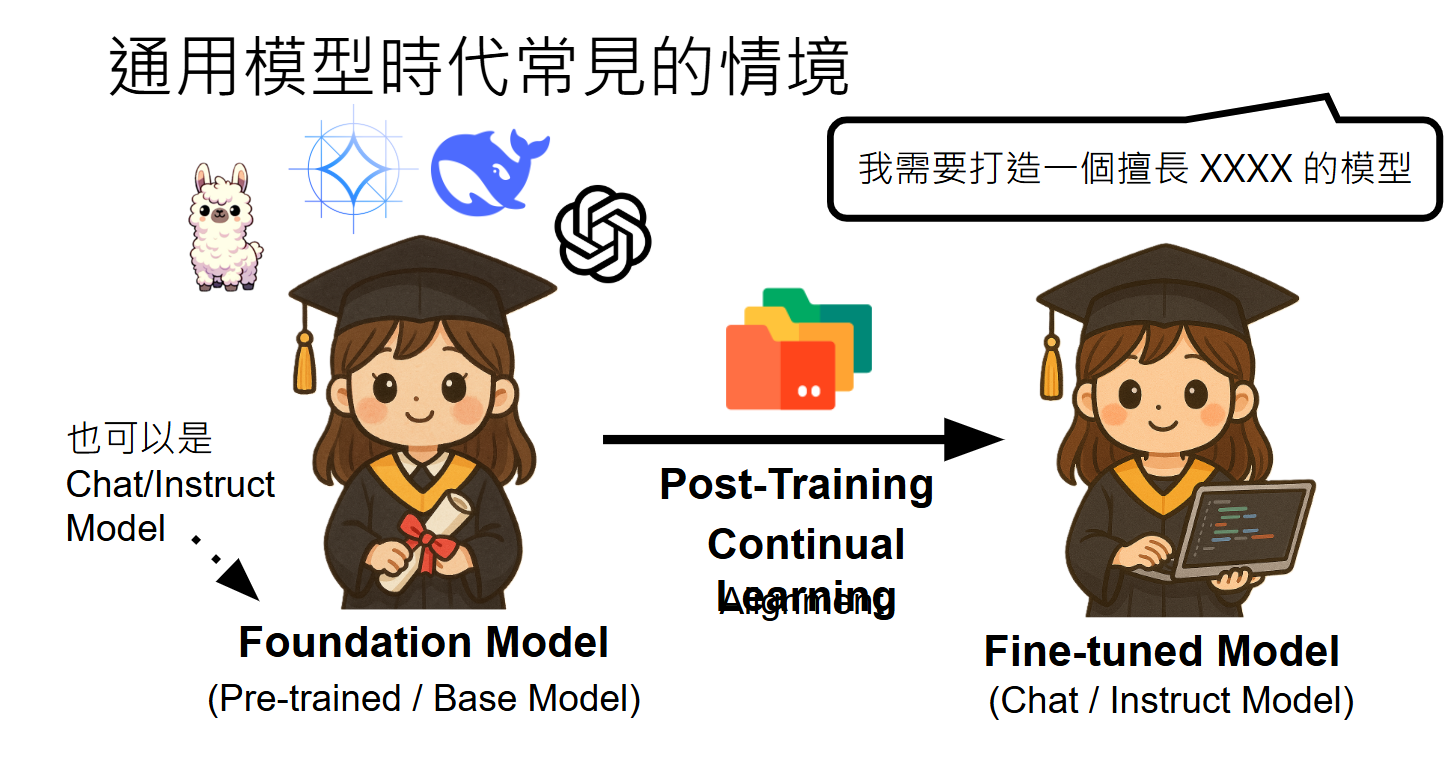
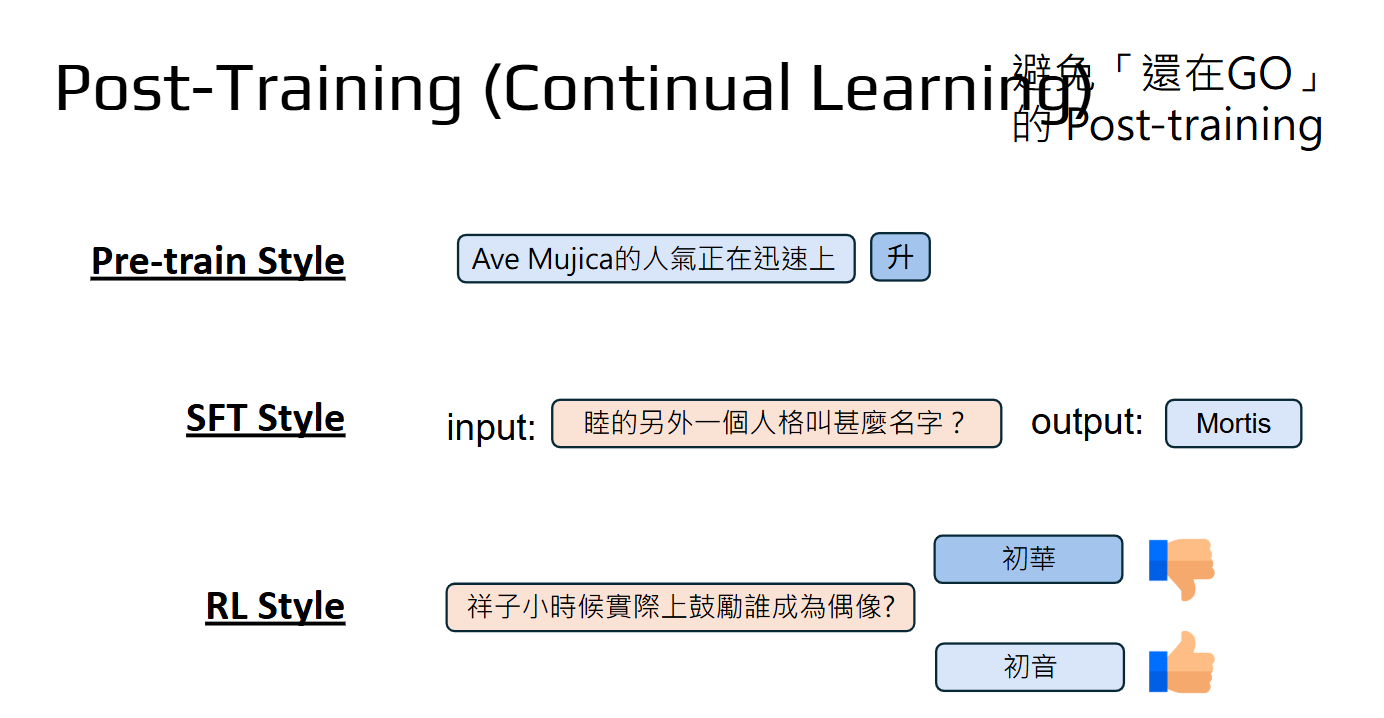
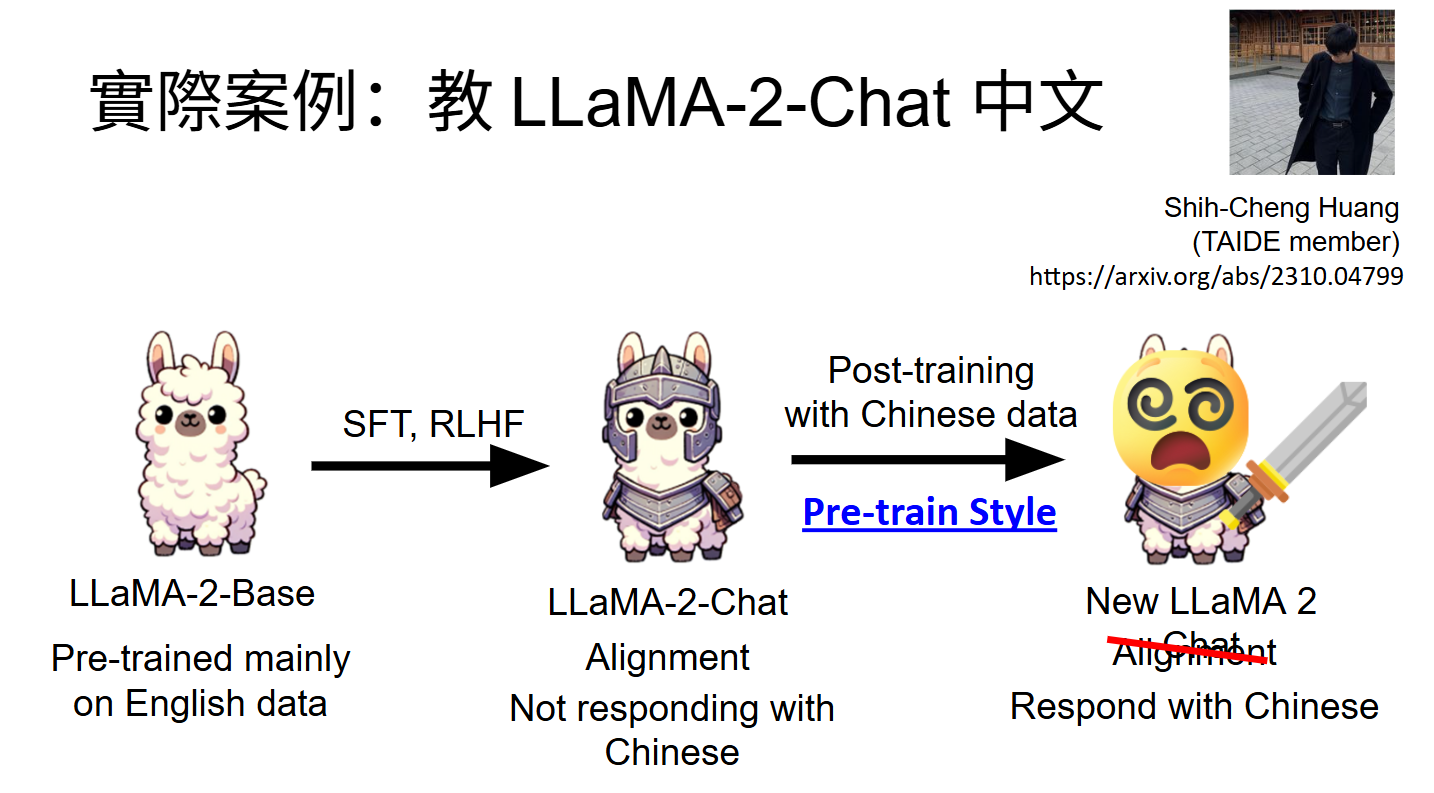
灾难性遗忘(Catastrophic Forgetting)是指在训练神经网络模型时,当模型学习新任务或新数据时,可能会忘记其在之前任务或数据上学到的知识。这是一个在增量学习、终身学习、迁移学习等任务中非常常见的问题,尤其是在神经网络和深度学习的应用中,灾难性遗忘是限制模型有效学习新信息的重要障碍。
灾难性遗忘的背景
在传统的机器学习中,通常假设数据是独立且同分布的(i.i.d.),每次训练的任务和数据都是独立的。训练一个模型时,它通常不会丢失之前学到的任何信息。然而,灾难性遗忘通常发生在以下情况:
- 增量学习(Incremental Learning):模型逐步接触到新任务或新数据,并在不访问旧数据的情况下进行训练。
- 终身学习(Lifelong Learning):模型需要在不断接触新任务的过程中保留先前学到的知识。
- 迁移学习(Transfer Learning):模型在一个任务上学习后,迁移到另一个任务上学习,但这可能导致它遗忘之前的任务。
灾难性遗忘的发生,主要是因为传统神经网络在学习新任务时,通常会更新所有参数,从而对旧任务的知识产生负面影响。这意味着,新的学习过程会覆盖或干扰原本已经学会的内容,导致模型表现出遗忘。
灾难性遗忘的表现
在面对新任务时,模型可能出现以下表现:
- 在新任务上的学习效果较好,但在旧任务上表现变差。
- 模型对旧任务的分类准确率显著下降,而对新任务的准确率则得到了提高。
- 性能剧烈波动:如果在没有任何对旧任务知识保留机制的情况下训练,模型会逐渐失去在旧任务上积累的知识。
这种现象尤其在连续学习、增量学习等任务中非常突出,导致模型在不断接触新信息时,逐渐遗忘之前的信息,从而无法维持之前的任务能力。
为什么会发生灾难性遗忘?
灾难性遗忘的根本原因与神经网络的训练机制密切相关。神经网络的参数是通过梯度下降法优化的,在训练过程中,网络通过反向传播算法调整权重。然而,这个过程会导致以下问题:
-
权重共享问题:神经网络中的参数(例如权重)是共享的,网络的每一层会同时对多个任务进行建模。当学习新任务时,梯度下降法会根据新任务的数据更新网络的权重,这种更新会影响到网络的所有任务,导致遗忘。
-
任务间干扰:不同任务的特征可能有所不同,这些任务在训练时没有相互隔离,容易发生干扰。在没有特定机制的情况下,网络无法有效区分各个任务的特征,导致知识被覆盖。
-
梯度冲突:在多任务学习或增量学习中,新的任务的梯度更新可能会与旧任务的梯度方向相冲突,导致参数更新时偏离原来任务的最优解,从而产生遗忘。
解决灾难性遗忘的策略
为了减轻或消除灾难性遗忘,研究人员提出了几种不同的策略和方法。以下是一些常见的应对策略:
1. 弹性权重保持(Elastic Weight Consolidation,EWC)
- 原理:EWC 通过对神经网络的权重进行正则化,来防止在学习新任务时过度修改已学到的知识。具体来说,它在损失函数中添加一个额外的正则化项,惩罚那些改变太大的权重。通过这种方式,EWC 可以保护那些对旧任务重要的参数,减少遗忘。
- 实现方法:EWC 计算每个参数对旧任务的贡献,给重要的参数加大惩罚,以避免它们在新任务训练时发生剧烈变化。
2. 对抗性训练(Adversarial Training)
- 原理:对抗性训练通过引入对抗性样本来增强模型对已学任务的鲁棒性。在增量学习中,对抗性训练有助于模型保留已学任务的知识,从而避免灾难性遗忘。
- 实现方法:通过训练一个生成对抗网络(GAN)或对抗性样本生成器,来生成对当前任务有干扰的样本,并将这些样本输入模型,从而保持模型对原任务的记忆。
3. 知识蒸馏(Knowledge Distillation)
- 原理:知识蒸馏通过将一个已经训练好的大模型(教师模型)所学到的知识转移到一个较小的模型(学生模型)中来,减少灾难性遗忘。在增量学习过程中,教师模型保存旧任务的知识,学生模型则学习新任务,同时保持对旧任务的记忆。
- 实现方法:训练一个新的模型时,通过使用旧模型的预测作为目标,并将新任务的标签和旧模型的输出一起作为训练目标,从而引导新模型保留旧任务的知识。
4. 经验回放(Experience Replay)
- 原理:经验回放方法通过在训练新任务时,保留一部分旧任务的数据并与新任务的数据一起进行训练,从而防止灾难性遗忘。这种方法通过混合训练样本,使得模型可以同时记住多个任务的信息。
- 实现方法:在训练过程中,定期将过去任务的样本存储到经验回放缓冲区(Replay Buffer)中,并在新任务训练时,从中采样一定比例的旧任务数据,来保持对旧任务的记忆。
5. 梯度信息保持(Gradient Episodic Memory,GEM)
- 原理:GEM 方法通过动态地选择和保持对每个任务重要的梯度信息,来解决灾难性遗忘。它通过保存一部分梯度信息,来确保新任务的学习不会对旧任务造成过大的干扰。
- 实现方法:每次学习新任务时,GEM 会记住上一任务的梯度信息并进行比较,确保新的学习过程中不会改变原任务的梯度方向。
6. 多任务学习(Multi-task Learning)
- 原理:多任务学习通过同时训练多个任务来增加模型的泛化能力。通过共享网络的部分结构,模型能够从多个任务中学习,保持对旧任务的记忆。
- 实现方法:在网络中加入多任务损失函数,使得每个任务在训练过程中共享部分权重,减少各个任务之间的相互干扰。
灾难性遗忘的挑战与前景
尽管有多种方法可以减轻灾难性遗忘,但它仍然是一个挑战,尤其是在深度学习中。以下是灾难性遗忘的一些挑战:
- 资源消耗:某些方法,如经验回放和知识蒸馏,需要大量的存储和计算资源,这在大规模问题中可能不可行。
- 任务间干扰:不同任务之间的相似性可能影响不同方法的效果。如何设计适应不同任务的策略,仍然是研究的热点。
- 持续学习的稳定性:如何在没有完整历史数据的情况下,保持任务间的稳定性和一致性,仍然是一个开放问题。
未来的研究可能会集中在以下几个方面:
- 更高效的增量学习和迁移学习方法,能够在更少的资源下减轻灾难性遗忘。
- 更强的模型可解释性,帮助我们理解哪些因素导致灾难性遗忘,并找到更精确的解决方法。
- 更好的在线学习技术,使得模型在不断接收新信息的同时,能够稳定地保持对历史任务的记忆。
总结
灾难性遗忘是神经网络在增量学习和终身学习中的一个重大挑战。通过多种方法,如弹性权重保持、经验回放、知识蒸馏等,研究人员不断探索如何有效减少灾难性遗忘,提高模型在多任务学习和动态环境中的稳定性。尽管有一定的解决方案,但在实际应用中仍然存在许多挑战,需要不断优化和创新。
获取人工智能训练资料(包括数据集、教材、课程、研究论文等)是学习和发展AI模型的关键步骤。下面我将详细介绍如何从不同来源获取人工智能训练资料:
1. 公开数据集
数据集是训练人工智能模型的核心组成部分。许多组织和研究机构公开了大规模的数据集,用于不同类型的任务,如图像分类、语音识别、自然语言处理等。
主要来源:
- Kaggle:Kaggle 提供了大量的公开数据集,涵盖分类、回归、图像识别等多个领域。Kaggle 还提供了竞赛,供用户参与并使用数据集进行建模和优化。
- UCI Machine Learning Repository:UCI Repository 是一个经典的机器学习数据集来源,提供了很多常用的数据集,适用于分类、回归、聚类等任务。
- Google Dataset Search:Google Dataset Search 是一个专门的搜索引擎,帮助用户找到可用于机器学习和数据分析的数据集。
- OpenML:OpenML 是一个开放的机器学习平台,提供数以千计的数据集和实验,便于研究和实验比较。
- AWS Open Datasets:AWS Open Datasets 提供了来自多个领域的大型开放数据集,适合用于训练大规模的AI模型。
特定任务的数据集:
- 图像数据集:如 ImageNet、CIFAR、COCO。
- 语音数据集:如 LibriSpeech、VoxCeleb、CommonVoice。
- 文本数据集:如 GLUE Benchmark、SQuAD、IMDb Reviews、OpenSubtitles.
2. 人工智能开源项目
除了公开的数据集,开源的AI框架、工具和预训练模型也可以作为学习资源,帮助你快速开始并训练自己的模型。
主要开源框架和库:
- TensorFlow:TensorFlow 是由Google开发的机器学习框架,提供了强大的工具和API,支持深度学习和神经网络的创建与训练。
- PyTorch:PyTorch 是由Facebook开发的深度学习框架,广泛用于学术界和工业界,特别适用于研究性工作。
- Keras:Keras 是一个高级神经网络API,基于Python开发,支持多种深度学习框架(如TensorFlow和Theano)。
- Scikit-learn:Scikit-learn 是一个用于传统机器学习任务(如回归、分类、聚类)的Python库,非常适合初学者和快速原型开发。
- Hugging Face:Hugging Face 提供了大量预训练的Transformer模型,专注于自然语言处理(NLP)任务,支持文本生成、情感分析、问答系统等。
其他有用的工具:
- OpenAI Gym:Gym 是一个用于开发和比较强化学习算法的开源平台,适合那些有兴趣进行强化学习研究的人。
- FastAI:FastAI 提供了深度学习的高效工具和课程,特别是通过其开源库,使得即使是初学者也能快速上手。
3. 学习课程和教程
AI的学习不仅依赖于数据,还需要系统的理论知识。以下是一些广受欢迎的在线课程和学习资料,适合不同水平的学习者。
免费课程:
- Coursera:Coursera 提供了许多免费的AI课程,特别是与斯坦福大学、加州大学伯克利分校等知名学术机构合作的课程。著名的课程包括《机器学习》by Andrew Ng 和《深度学习专项课程》by Andrew Ng。
- edX:edX 是一个提供许多大学级别免费在线课程的平台,涵盖人工智能、机器学习、深度学习等主题。
- MIT OpenCourseWare:MIT OCW 提供了麻省理工学院的人工智能和机器学习课程的完整内容,包括视频讲座、讲义和习题。
- FastAI:FastAI课程 提供免费的深度学习课程,重点讲解如何利用深度学习库(如PyTorch)解决实际问题。
- Google AI:Google AI 提供了从入门到进阶的人工智能课程,适合想要从基础开始的学习者。
书籍:
- 《人工智能:一种现代方法》(Artificial Intelligence: A Modern Approach):Stuart Russell 和 Peter Norvig 所著,是AI领域的经典教材,适合理论学习。
- 《深度学习》(Deep Learning):Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 的著作,是深度学习领域的权威教材。
- 《模式识别与机器学习》(Pattern Recognition and Machine Learning):Christopher M. Bishop 的书,适合学习机器学习理论和应用。
4. 研究论文与文献
对于AI领域的最新进展和技术,阅读研究论文是一个不可或缺的部分。许多顶级的研究论文都可以通过以下途径获取:
- arXiv:arXiv 是一个开放的学术论文库,涵盖了计算机科学、人工智能、机器学习、深度学习等领域的最新研究。
- Google Scholar:Google Scholar 是一个广泛的学术搜索引擎,可以帮助你找到人工智能相关的研究论文。
- IEEE Xplore:IEEE Xplore 提供了大量计算机科学和工程方面的研究论文,特别是在AI、机器学习和数据科学领域。
5. 在线社区与论坛
加入人工智能的在线社区和论坛,可以让你与其他学习者、研究人员和工程师交流,获取最新的学习资料和研究动态。
- Stack Overflow:Stack Overflow 是开发者讨论技术问题的平台,你可以在这里找到关于人工智能、机器学习、深度学习的各种问题和答案。
- Reddit:Reddit AI Community 是一个活跃的社区,提供人工智能、机器学习和数据科学的讨论和资源。
- GitHub:GitHub 是开源代码的集中平台,很多AI项目都托管在这里。你可以查找和参与各种人工智能和深度学习的开源项目。
总结
获取人工智能的训练资料,既可以通过公开数据集、开源代码、在线课程和书籍,也可以通过最新的研究论文、论坛和社区。通过综合利用这些资源,你可以深入理解AI的各个方面,并在实际项目中应用所学知识。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 22
22 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)