机器学习:DecisionTreeClassifier决策树模型
基本概念: 决策树通过树状结构来表示决策过程,每个节点代表一个特征(属性),每个分支代表特征的一个可能取值,每个叶子节点则代表一个分类结果。优点:直观易懂,易于可视化和解释。可处理数值型和分类型数据。无需特征缩放(如标准化或归一化)。缺点:容易过拟合,特别是在数据量较小或树深度过大时。对噪声敏感,少量噪声可能导致较大的偏差。`DecisionTreeClassifier` 是一种强大且易于使用的分
`DecisionTreeClassifier` 是 Scikit-learn 库中用于分类任务的决策树模型。决策树是一种树形结构的模型,用于分类和回归任务,通过将数据集分割为不同的子集来进行决策,最终帮助做出预测。以下是 `DecisionTreeClassifier` 的详细介绍,包括其基本概念、使用方法、参数设置和示例。
1. 决策树概述
基本概念: 决策树通过树状结构来表示决策过程,每个节点代表一个特征(属性),每个分支代表特征的一个可能取值,每个叶子节点则代表一个分类结果。
优点:
直观易懂,易于可视化和解释。
可处理数值型和分类型数据。
无需特征缩放(如标准化或归一化)。
缺点:
容易过拟合,特别是在数据量较小或树深度过大时。
对噪声敏感,少量噪声可能导致较大的偏差。
2. 安装 Scikit-learn
如果你尚未安装 Scikit-learn,可以通过以下命令安装:
pip install scikit-learn
3. 使用方法
3.1 导入库
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix3.2 基本用法
下面是使用 `DecisionTreeClassifier` 的基本步骤和示例代码:
# 示例数据集
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器实例
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 评估模型
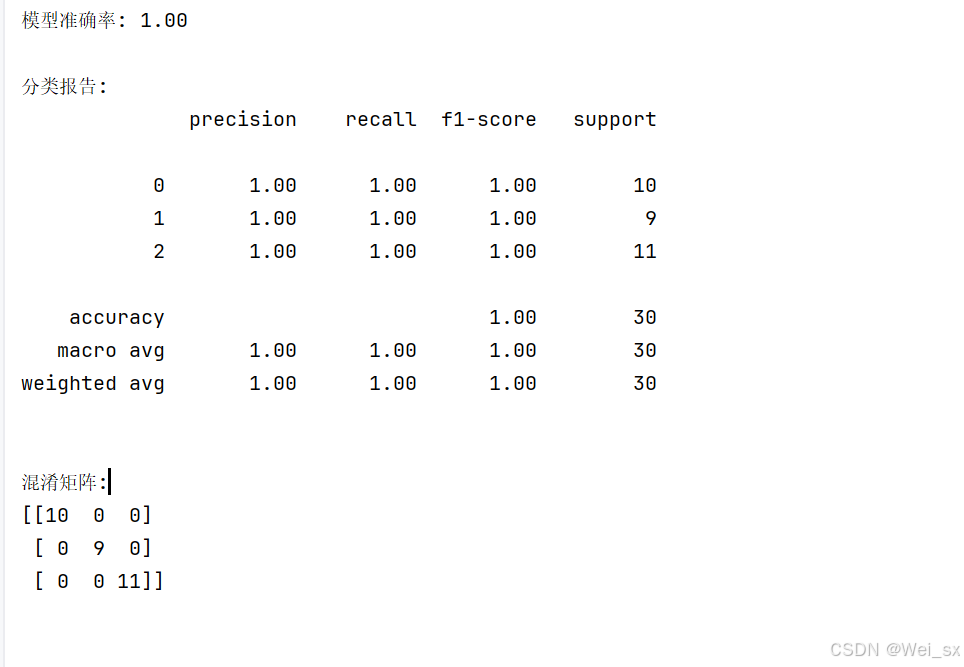
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))4. 输出结果
运行上述代码后,你将得到模型的准确率、分类报告和混淆矩阵的输出结果。输出示例可能如下所示(具体数值可能有所不同):
5. 常见参数
`DecisionTreeClassifier` 具有多种参数,灵活设置可以帮助提高模型性能:
criterion: 用于决定分裂质量的函数。常用的有 `gini`(默认)和 `entropy`。
max_dept: 决策树的最大深度。可以用来限制树的生长,防止过拟合。
min_samples_split: 进行分裂所需的最小样本数,值越大,模型越简单。
min_samples_leaf: 叶子节点上所需的最小样本数,控制树的复杂度。
max_features: 在寻找最佳分裂时考虑的特征数量,可以是整数、浮点数或 "auto"(默认为特征总数)。
random_state: 随机种子,用于确保结果的可重复性。
6. 可视化决策树
可以使用 `plot_tree` 函数可视化决策树,更直观地理解模型的决策过程:
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()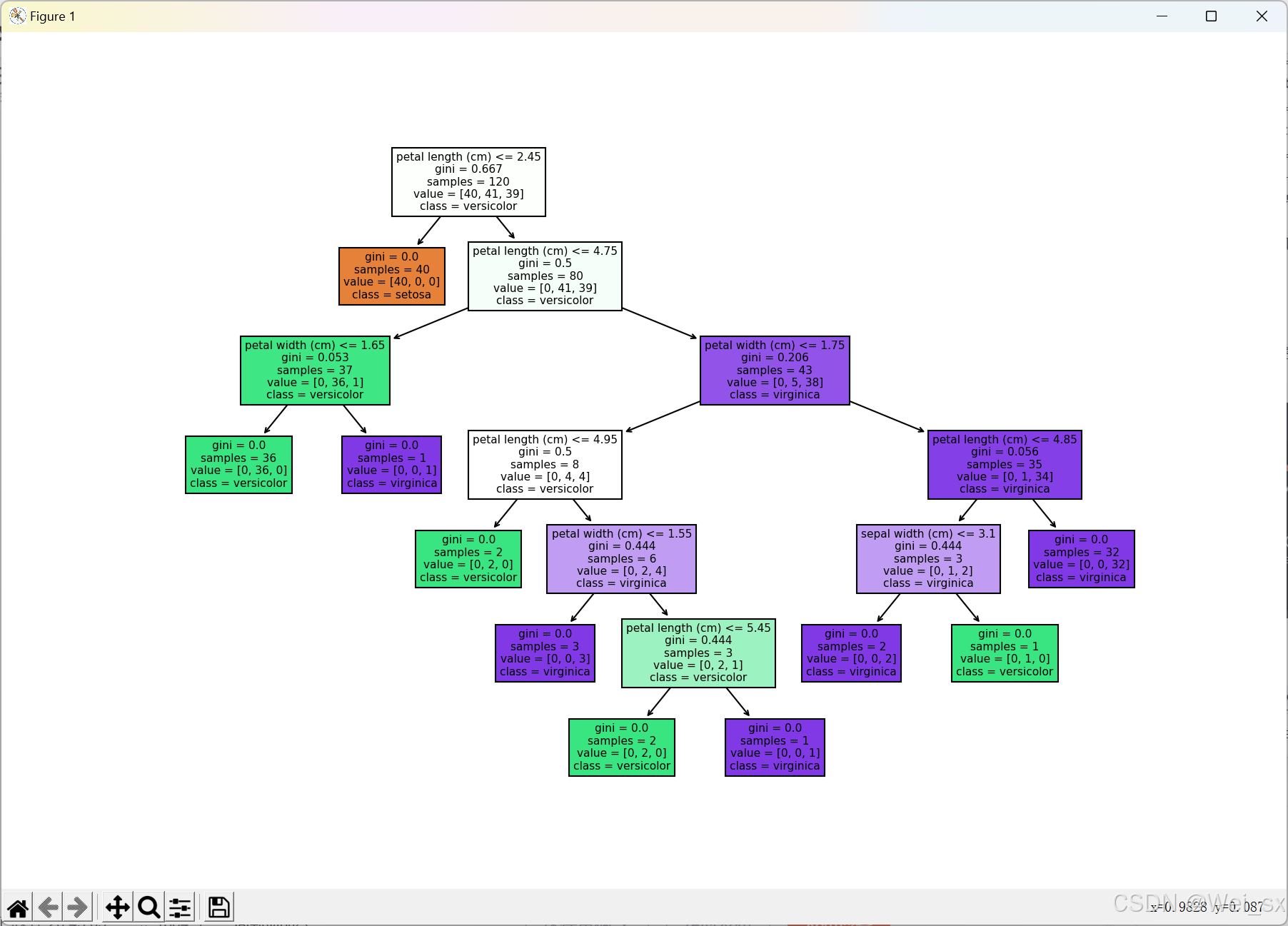
7. 示例实现
泰坦尼克号乘客生存预测:根据提供的数据分析,分析妇女,儿童和上流社会等因素对存活影响,用机器学习工具来预测哪些乘客幸免于悲剧。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 1.获取数据
titan_train = pd.read_csv("./data/titanic/train.csv")
# 2.数据基本处理
# 2.1 确定特征值,目标值
x = titan_train[['Pclass','Sex','Age']]
y = titan_train.Survived
# 2.2 缺失值处理
x.Age.fillna(x.Age.mean(),inplace=True)
# 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程(字典特征抽取)
# 特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
# x.to_dict(orient="records") 需要将数组特征转换成字典数据
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 4.机器学习(决策数)
# 4.1 实例化模型对象
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 4.3 进行预测
y_pred = estimator.predict(x_test)
# 5.评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))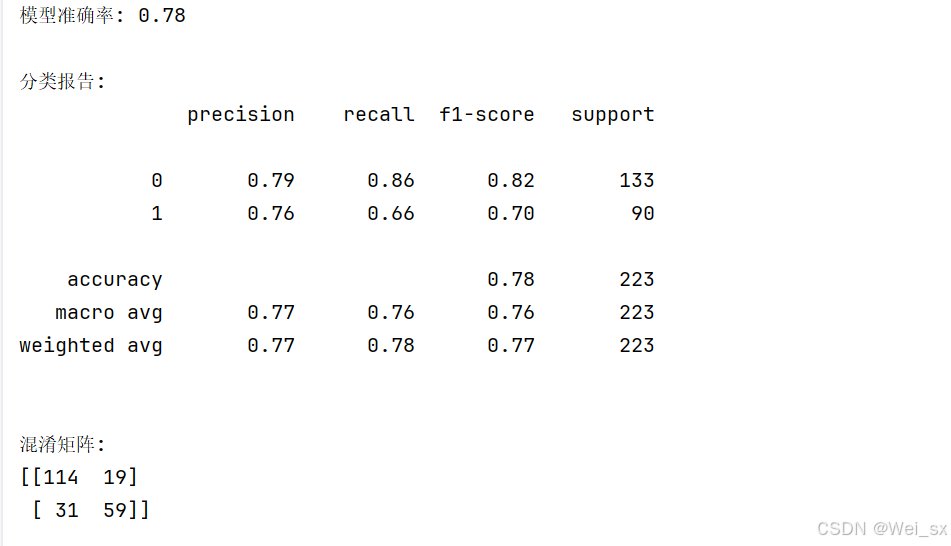
可视化决策树

7. 总结
`DecisionTreeClassifier` 是一种强大且易于使用的分类算法,适用于多种应用场景。通过调整参数,可以有效地控制模型的复杂度,提升预测性能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)