机器学习:EM算法
EM算法是一种强大的迭代方法,对于涉及隐变量和缺失数据的统计模型参数估计特别有效。其简单而有效的理念让它成为许多领域的重要工具。希望这对您有所帮助!XZQQ。
EM算法(Expectation-Maximization Algorithm)是一种重要的统计学习方法,常用于处理存在隐变量的概率模型的参数估计。它由两部分组成:期望步骤(E步)和最大化步骤(M步)。EM算法在许多领域有广泛的应用,包括聚类、图像处理、缺失数据插补、混合模型的参数估计等。
1. 基本概念
EM算法的主要思想是在估计模型参数时,通过反复迭代来寻找逻辑上最优的参数值。EM算法的流程可以用以下几个步骤描述:
隐变量:模型中有未观测到的变量(隐变量),EM算法利用观察到的数据来估计这些隐变量。
参数初始化:对模型参数进行初始化。
2. 算法步骤
EM算法的基本步骤如下:
2.1 初始化
随机初始化模型参数。
2.2 迭代过程
E步(期望步骤):
基于当前参数,计算隐变量的期望值。即通过已知的观测数据来估计隐变量的分布:
其中,是观测数据,
是隐变量,
是数据的联合概率分布,
函数表示给定当前参数
下的对数似然的期望。
M步(最大化步骤):
通过最大化函数,更新参数:
这个步骤的目的是找到能够使期望对数似然增加的参数。
2.3 收敛判断
重复执行E步和M步,直到参数变化很小,或者对数似然函数的变化在某个阈值以下,认为达到了收敛。
3. 收敛性
EM算法的收敛性是有保证的。每次迭代都会使对数似然函数 至少不减少,最终会收敛到局部最优解。然而,EM算法并不一定会收敛到全局最优解,具体取决于初始化参数的选择。
4. 应用实例
EM算法可以应用于多种情境,以下是一些常见的案例:
高斯混合模型(GMM):
在 GMM 中,EM 算法用于估计混合成分的均值、方差和权重。隐变量表示每个数据点属于哪个高斯成分。
缺失数据插补:
EM 算法可用于处理缺失数据的场景。通过模型推断缺失值,并在每次迭代中优化模型参数。
聚类:
在聚类分析中,EM 可以用于软聚类,即允许数据点属于多个簇的概率分配。
5. 举例:高斯混合模型中的EM算法
以下是一个关于高斯混合模型(GMM)的EM算法的简单实现示例。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
# 生成示例数据
np.random.seed(0)
n_samples = 500
C1 = [0, 0]
C2 = [5, 5]
data1 = np.random.randn(n_samples, 2) + C1
data2 = np.random.randn(n_samples, 2) + C2
X = np.vstack((data1, data2))
# 可视化示例数据
plt.scatter(X[:, 0], X[:, 1], color='gray', alpha=0.5)
plt.title("Generated Data")
plt.show()
# 应用EM算法(GMM)
gmm = GaussianMixture(n_components=2, covariance_type='full')
gmm.fit(X)
# 获取参数
means = gmm.means_
covariances = gmm.covariances_
# 可视化聚类结果和高斯分布
plt.scatter(X[:, 0], X[:, 1], color='gray', alpha=0.5)
for mean, cov in zip(means, covariances):
# 画出高斯分布的轮廓
eigenvalues, eigenvectors = np.linalg.eigh(cov)
# 计算标准差
s = np.sqrt(eigenvalues)
# 轴
v = eigenvectors * 2 * s
plt.quiver(mean[0], mean[1], v[0][0], v[0][1], color='red', scale=2)
plt.quiver(mean[0], mean[1], v[1][0], v[1][1], color='red', scale=2)
plt.title("GMM Clustering with EM Algorithm")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()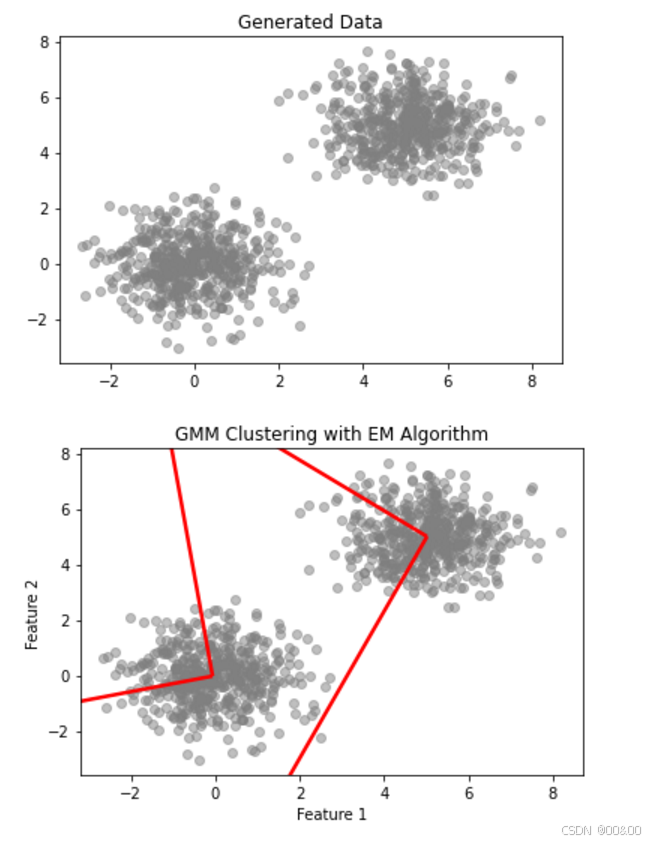
6. EM算法的优缺点
优点:
能够处理缺失数据和隐变量。
通用性强,适用于各种统计模型。
理论基础扎实,具有收敛性。
缺点:
可能收敛到局部最优解,结果依赖于初始化。
对于一些问题,计算复杂度可能较高。
当数据量很大时,E步和M步的计算可能非常耗时。
7.总结
EM算法是一种强大的迭代方法,对于涉及隐变量和缺失数据的统计模型参数估计特别有效。其简单而有效的理念让它成为许多领域的重要工具。希望这对您有所帮助!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)