深度学习基石:卷积神经网络(CNN)详解
卷积神经网络(CNN)是一种专为处理网格状数据(如图像、视频、音频和文本)设计的深度学习模型。其核心在于通过卷积层提取局部特征,利用池化层降低数据维度,并通过全连接层进行分类或回归。CNN通过局部连接和参数共享,显著减少了模型参数,同时具备平移不变性,使其在图像分类、目标检测等计算机视觉任务中表现卓越。典型的CNN架构包括卷积层、激活函数、池化层和全连接层的交替堆叠。通过Keras构建的简单CNN
今天我们将深入探讨一种在计算机视觉领域取得巨大成功的模型架构——卷积神经网络(Convolutional Neural Network, CNN)。
什么是卷积神经网络?
卷积神经网络(CNN)是一种专门设计用于处理具有网格状拓扑结构的数据的深度学习模型。最典型的例子就是图像(2D 网格),此外也适用于处理视频(3D 网格)和序列数据(1D 网格),如音频和文本。
CNN 之所以强大,是因为它能够有效地从原始数据中学习并提取出层级化的特征,从简单的边缘、纹理到复杂的物体部件和整体结构。这使得它在图像分类、目标检测、图像分割等众多计算机视觉任务中表现卓越。
CNN 的核心组成部分
一个典型的 CNN 架构通常包含以下几种主要类型的层:
1. 卷积层 (Convolutional Layer)
作用: 提取输入数据的局部特征。
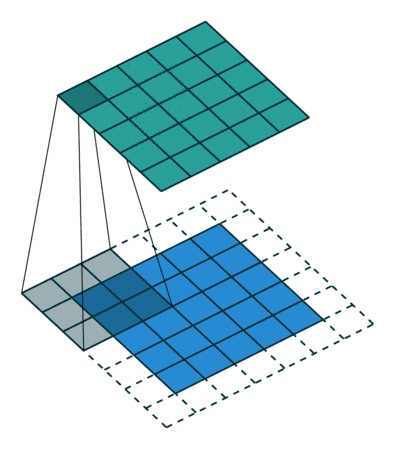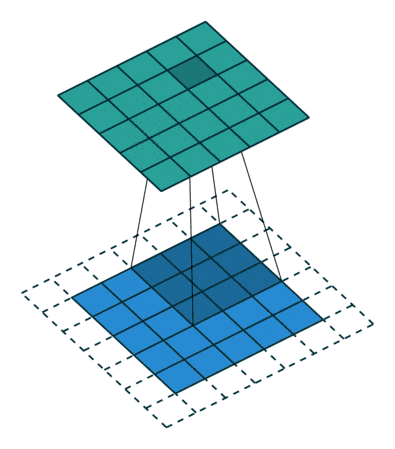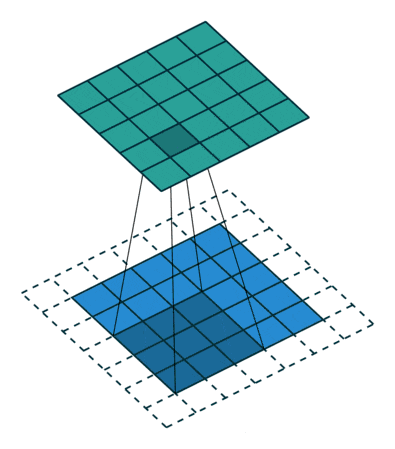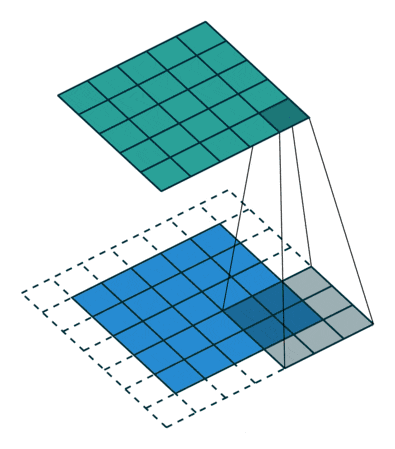
这是 CNN 最核心的层。它通过使用一组可学习的过滤器(Filter),也称为卷积核(Kernel),对输入数据进行卷积操作。每个过滤器都是一个小型的矩阵,它在输入数据的局部区域上滑动,并计算该区域与过滤器之间的点积。
这个点积操作能够检测输入中与过滤器模式相似的特征。例如,一个过滤器可能被训练来检测垂直边缘,另一个检测水平边缘。
当过滤器在整个输入数据上滑动时(从左到右,从上到下),它会生成一个特征图(Feature Map)。特征图上的每个值代表了该过滤器在输入数据对应位置上检测到特定特征的强度。
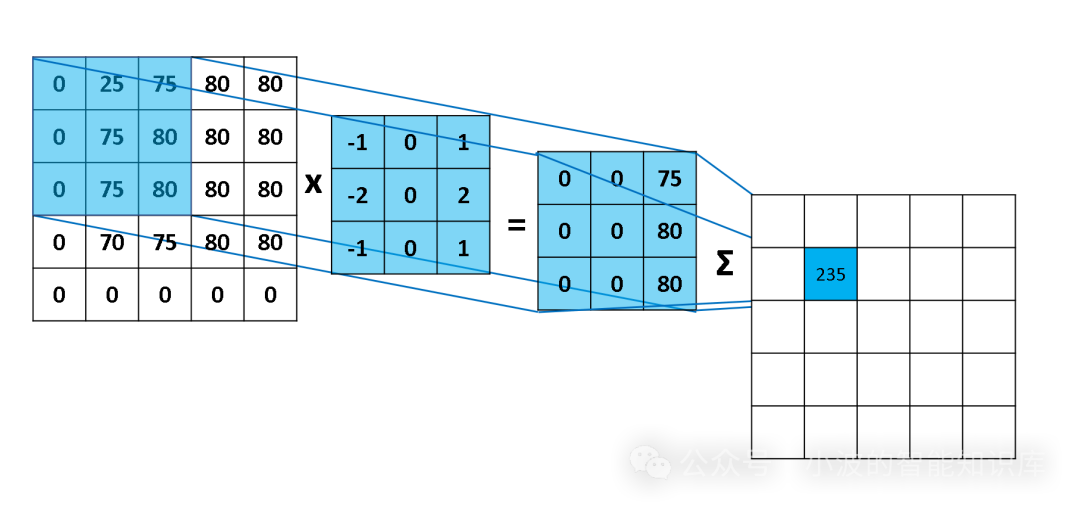
参数共享与局部连接:
-
局部连接 (Local Connectivity): 卷积层中的每个神经元(即特征图中的一个点)只连接到输入数据的局部区域,而不是整个输入。这模仿了生物视觉系统中神经元的感受野(Receptive Field),并且显著减少了模型的参数数量。
-
参数共享 (Parameter Sharing): 同一个特征图中的所有神经元共享同一组权重和偏置(即使用同一个过滤器)。这意味着无论特征出现在图像的哪个位置,都可以被同一个过滤器检测到。这不仅进一步减少了参数数量,也使得 CNN 对特征的位置具有一定的平移不变性。
2. 填充 (Padding) 与 步幅 (Stride)
这两个参数控制着卷积层如何应用过滤器,它们影响着输出特征图的大小。
-
填充 (Padding): 在输入数据的边界周围添加额外的像素(通常填充 0)。
-
目的:
-
防止边界信息丢失:当过滤器在图像边缘进行卷积时,如果不加填充,边缘的像素只会被过滤器触及一次,而中心像素会被触及多次。填充使得边缘信息也能被充分利用。
-
控制输出尺寸:通过增加输入数据的尺寸,可以使输出特征图的尺寸与输入尺寸相同或相近(例如使用 "Same" padding)。
-
-
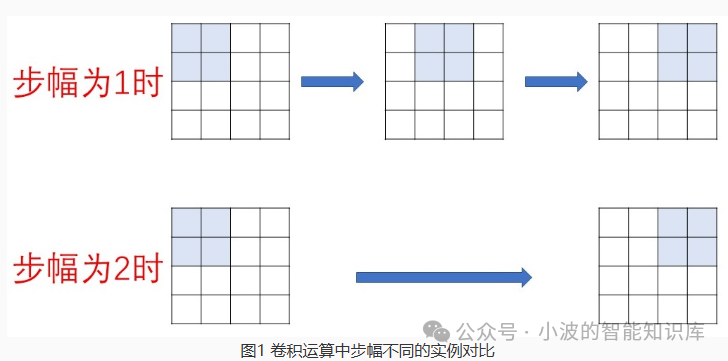
步幅 (Stride): 过滤器在输入数据上滑动的步长。
-
目的: 控制输出尺寸和感受野的移动速度。
-
效果: 默认步幅为 1。如果步幅大于 1(例如步幅为 2),过滤器会跳过一些像素,导致输出特征图的尺寸减小,同时后续层的一个神经元覆盖的输入区域(感受野)也会更大。
-
3. 池化层 (Pooling Layer)
作用: 降低特征图的空间尺寸,减少参数数量和计算复杂度,同时增强模型的鲁棒性。
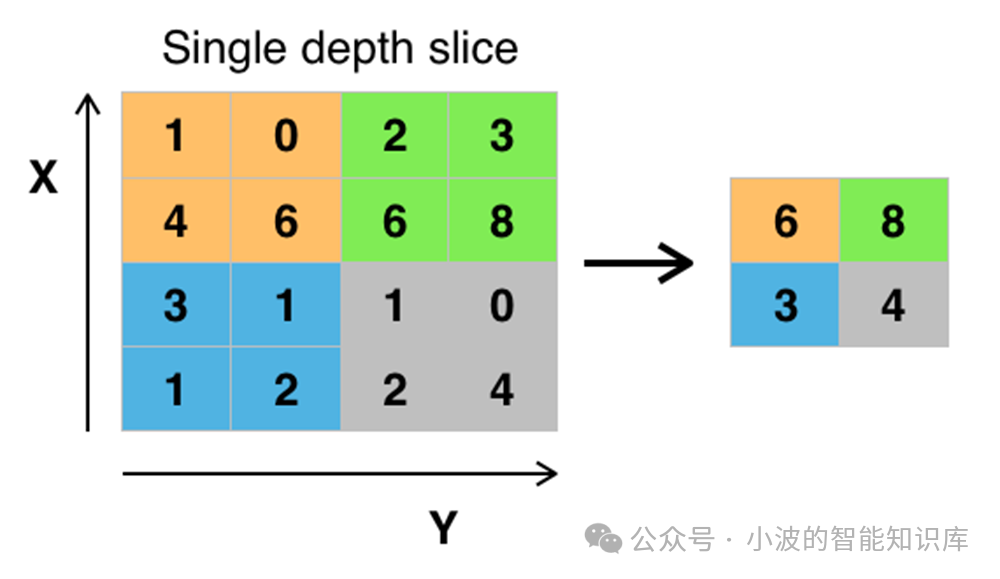
池化层通常跟在卷积层后面。它在特征图的局部区域上执行一个下采样操作,用该区域的某个代表性值替换整个区域。
-
最大池化 (Max Pooling): 取局部区域内的最大值作为输出。这有助于保留特征图中最显著的特征(例如,某处存在一个强烈的边缘)。
-
平均池化 (Average Pooling): 计算局部区域内的平均值作为输出。这种方法能保留更多的背景信息。
池化操作通常不包含可学习参数。它通过固定大小的窗口和步长在特征图上滑动来完成。
池化的好处:
-
降维: 显著减少特征图的尺寸,降低后续层的计算负担。
-
鲁棒性: 使模型对特征的微小位置变化、旋转和尺度变化更加不敏感(即具有一定的平移不变性),提高了模型的泛化能力。
4. 全连接层 (Fully Connected Layer)
作用: 在提取并经过下采样的特征基础上进行分类或回归。
在经过一个或多个卷积层和池化层后,原始输入的局部特征已经被提取并抽象化为更高层级的表示。在将这些特征送入全连接层之前,通常需要将最后的特征图展平(Flatten)成一个一维向量。
全连接层的每个神经元都与前一层(展平后的特征向量)的所有神经元相连,类似于传统的神经网络层。它接收来自卷积和池化层提取的抽象特征,并通过学习权重和偏置,将这些特征组合起来,用于最终的分类(例如,输出属于每个类别的概率)或回归(例如,输出一个预测值)。
CNN 架构概览
一个典型的 CNN 架构通常是卷积层、激活函数(如 ReLU)、池化层交替堆叠,最后接若干个全连接层和输出层。
输入图像 -> [卷积层 -> 激活函数 -> 池化层] x N -> [卷积层 -> 激活函数] x M -> 展平 -> [全连接层 -> 激活函数] x K -> 输出层 (Softmax for classification)
实践案例:使用 Keras 构建一个简单的 CNN 分类器 (MNIST 数据集)
我们使用经典的 MNIST 手写数字识别数据集来演示如何构建和训练一个简单的 CNN。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist # 使用tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D
from tensorflow.keras.utils import to_categorical
# 确保 matplotlib 可以显示图像
# %matplotlib inline # 如果在Jupyter notebook中使用
# 1. 加载MNIST数据集
# 数据集包含60000张训练图像和10000张测试图像
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(f"原始训练图像形状: {train_images.shape}")
print(f"原始测试图像形状: {test_images.shape}")
# 2. 数据预处理
# CNN输入需要通道信息,MNIST是灰度图,通道数为1
# 将图像形状从 (样本数, 高, 宽) 变为 (样本数, 高, 宽, 通道数)
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 将像素值缩放到 [0, 1] 范围
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
# 对标签进行one-hot编码,将整数标签转换为向量形式
# 例如,数字 5 变为 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
train_labels_one_hot = to_categorical(train_labels)
test_labels_one_hot = to_categorical(test_labels)
print(f"处理后训练图像形状: {train_images.shape}")
print(f"处理后训练标签形状: {train_labels_one_hot.shape}")
# 可选:显示一些示例图像
plt.figure(figsize=(10, 4))
for i in range(5):
plt.subplot(1, 5, i + 1)
plt.imshow(train_images[i].reshape(28, 28), cmap='gray')
plt.title(f"Label: {train_labels[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 3. 构建CNN模型
model = Sequential()
# 第一层卷积层
# 32个滤波器,每个滤波器大小3x3
# 使用ReLU激活函数
# 输入形状为 28x28x1 (图片高x宽x通道数)
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
# 第一层最大池化层
# 池化窗口大小2x2,步长默认为池化窗口大小 (2)
model.add(MaxPooling2D((2, 2)))
# 第二层卷积层
# 64个滤波器,每个滤波器大小3x3
model.add(Conv2D(64, (3, 3), activation='relu'))
# 第二层最大池化层
model.add(MaxPooling2D((2, 2)))
# 第三层卷积层 (可选,增加深度)
model.add(Conv2D(64, (3, 3), activation='relu'))
# 展平层:将最后一个池化层的输出特征图展平为一维向量
model.add(Flatten())
# 第一个全连接层
# 64个神经元,使用ReLU激活函数
model.add(Dense(64, activation='relu'))
# 输出层
# 10个神经元,对应10个类别 (0-9)
# 使用Softmax激活函数,输出每个类别的概率
model.add(Dense(10, activation='softmax'))
# 打印模型概况
model.summary()
# 4. 编译模型
# optimizer: 优化器,用于更新模型权重 (adam是常用的选择)
# loss: 损失函数,用于衡量模型预测与真实标签的差距 (多分类用 categorical_crossentropy)
# metrics: 评估指标 (这里用 accuracy)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 5. 训练模型
# epochs: 训练轮数
# batch_size: 每批次训练的样本数量
print("\n开始训练模型...")
history = model.fit(train_images, train_labels_one_hot, epochs=5, batch_size=64, validation_split=0.2) # 使用20%训练数据作为验证集
print("训练完成.")
# 可选:绘制训练过程中的准确率和损失
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 6. 在测试集上评估模型
print("\n评估模型...")
test_loss, test_acc = model.evaluate(test_images, test_labels_one_hot)
print(f'\n测试集损失 (Test loss): {test_loss:.4f}')
print(f'测试集准确率 (Test accuracy): {test_acc:.4f}')
总结
卷积神经网络(CNN)凭借其独特的卷积层和池化层结构,在处理图像等网格状数据方面展现出了强大的能力。通过局部连接、参数共享和层级化的特征提取,CNN 能够有效地学习复杂的视觉模式。理解卷积层、池化层、填充、步幅以及全连接层的作用,是掌握 CNN 的关键。上面的代码示例展示了如何使用 Keras 快速构建一个简单的 CNN 来解决图像分类问题。
CNN 架构的变种非常多,如 LeNet、AlexNet、VGG、GoogLeNet、ResNet 等,它们在层数、连接方式、模块设计上有所不同,但核心思想都建立在卷积和池化等基本构建块之上。
最后
如果你真的想学习人工智能,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
这里也给大家准备了人工智能各个方向的资料,大家可以微信扫码找我领取哈~


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)