LLM+KG+Agent的Text2SPARQL多语言KBQA智能体框架—mKGQAgent
前面笔者介绍了《》及《》,一般的Text2Sparql/Text2SQL技术路线图如下,目标是奖自然语言转话为可查询的SQL语句。目前基于KG+LLM+Agent的KBQA方案,在多语言场景未得到充分探索。下面来看一个智能体框架-mKGQAgent,通过模拟人类推理过程将自然语言问题转化为SPARQL查询。
前面笔者介绍了《【LLM & RAG & text2sql】大模型在知识图谱问答上的核心算法详细思路及实践》及《【开源分享】KBQA核心技术及结合大模型SPARQL查询生成问答实践》,一般的Text2Sparql/Text2SQL技术路线图如下,目标是奖自然语言转话为可查询的SQL语句。
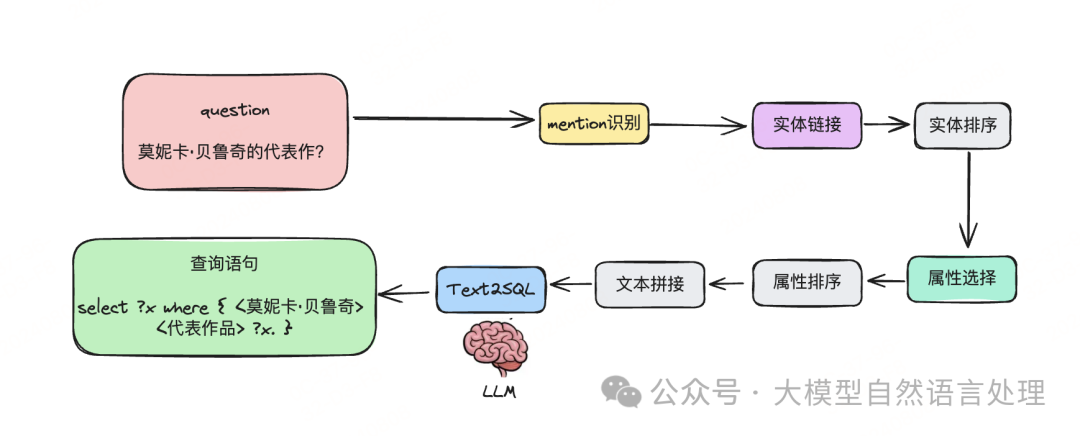
目前基于KG+LLM+Agent的KBQA方案,在多语言场景未得到充分探索。下面来看一个智能体框架-mKGQAgent,通过模拟人类推理过程将自然语言问题转化为SPARQL查询。
mKGQAgent架构
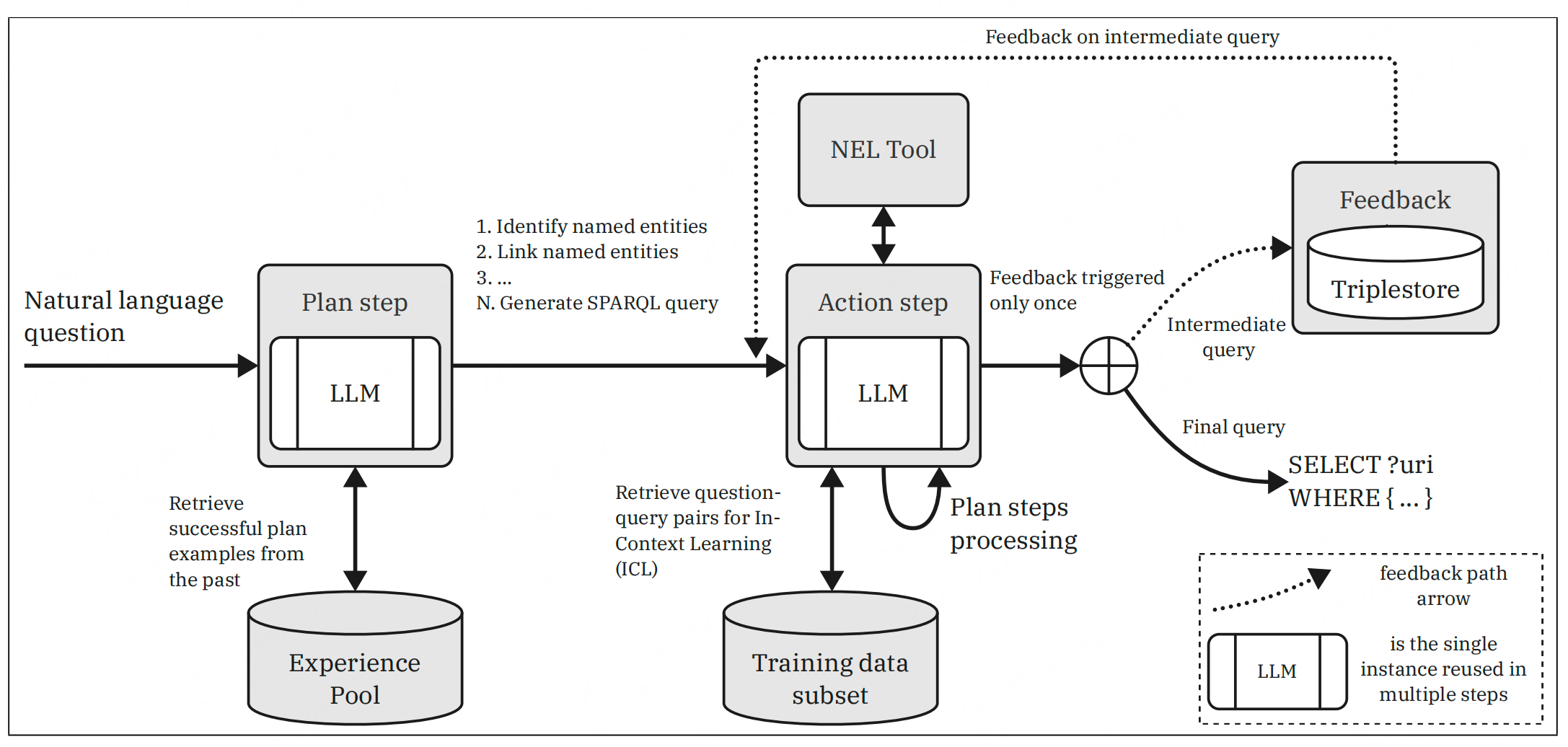
工作流程分为离线阶段和评估(在线)阶段,核心是模块化的子任务分解与协同,结合经验池(Experience Pool)和工具调用提升多语言场景下的性能。
1 离线阶段(Offline Phase)
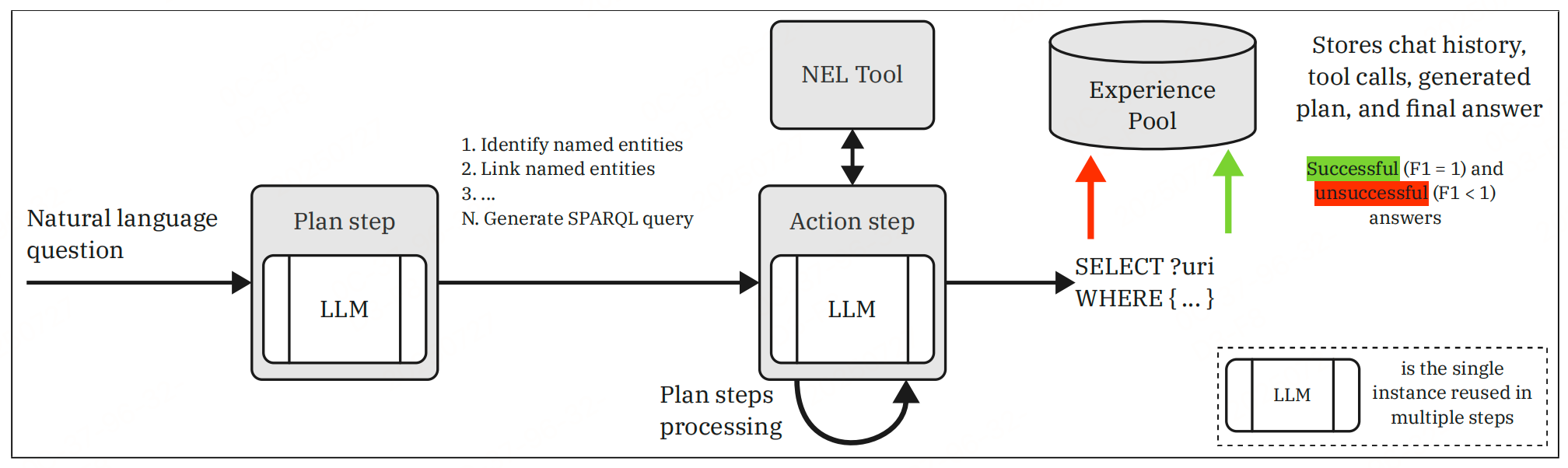
离线阶段的核心是构建经验池(Experience Pool),为在线阶段的推理提供上下文学习的示例。该阶段通过一个简化版代理( S A g e n t \mathcal{SAgent} SAgent)完成,包括以下步骤:
1.1 命名实体链接工具(Named Entity Linking, NEL Tool)
模拟人类查询知识图谱中资源标识符的行为,将自然语言中的实体和关系候选映射到知识图谱中的URI(统一资源标识符)。例如,将“Angela Merkel”链接到Wikidata的URI(Q567)。
复用现有NEL服务(如Wikidata的实体查询接口)和关系链接工具(如Falcon 2.0),而非提出新算法:

- 输入实体候选( E E E)和关系候选( R R R);
- 调用NEL服务获取每个候选的URI;
- 返回链接后的实体和关系字典。
1.2 计划步骤(Plan Step)
将生成SPARQL查询的复杂任务分解为一系列子任务(如实体识别、关系链接、查询优化等),模拟人类分步解决问题的逻辑。
通过LLM生成分步计划:

- 输入自然语言问题( q i q_i qi)和系统提示( S plan S_{\text{plan}} Splan);
- LLM输出子任务列表( p i p_i pi),作为后续行动的指南。
1.3 无经验池的行动步骤(Action Step without Experience Pool)
按计划步骤顺序执行子任务,结合NEL工具完成实体链接,逐步生成SPARQL查询。
- 实现:

- 输入计划( p i p_i pi)、LLM、NEL工具和系统提示( S action S_{\text{action}} Saction);
- 依次执行每个子任务,必要时调用NEL工具;
- 保存对话历史( H i \mathcal{H}_i Hi),最终输出初步SPARQL查询( φ ^ i \hat{\varphi}_i φ^i)。
1.4 经验池构建(Experience Pool Construction)
- 功能:存储 S A g e n t \mathcal{SAgent} SAgent的推理过程和结果(包括成功与失败案例),作为在线阶段的上下文学习示例。
- 实现:
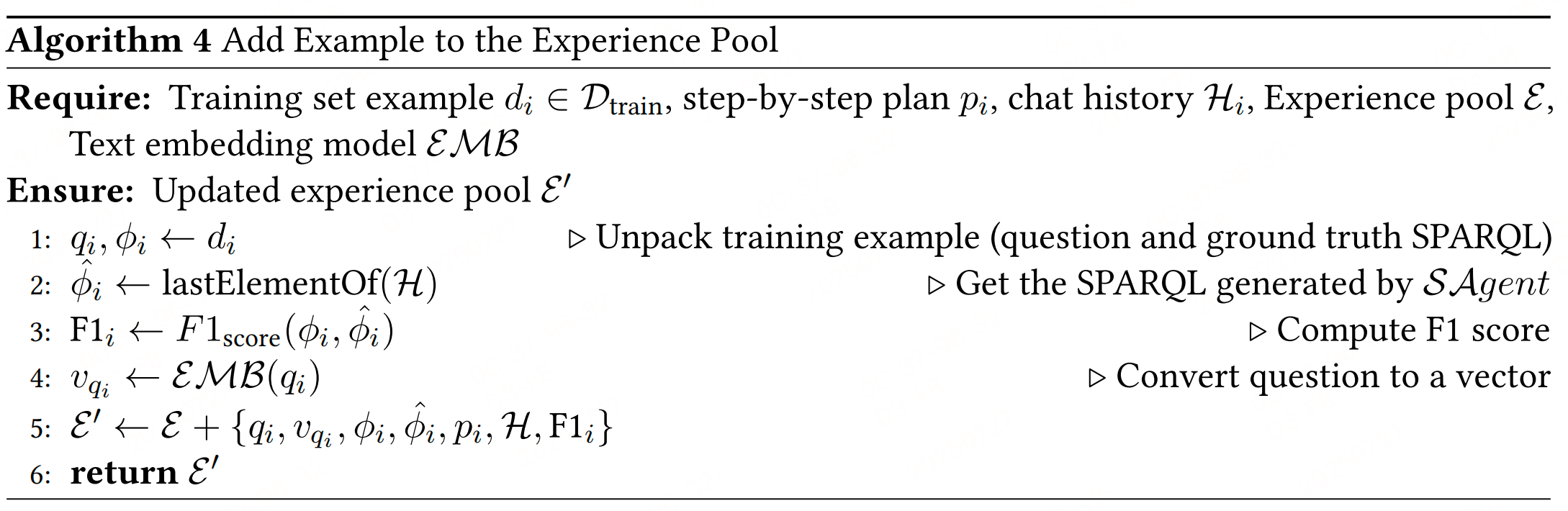
- 对训练集中的问题( q i q_i qi),生成SPARQL查询并与真实查询( φ i \varphi_i φi)对比,计算F1分数;
- 将问题向量、计划、对话历史、F1分数等元数据存入向量数据库;
- 经验池包含成功(F1=1.0)和失败(F1<1.0)的案例,支持后续相似问题的检索。
2 评估阶段(Evaluation Phase)
在线阶段基于离线构建的经验池,通过计划、行动和反馈的协同生成最终SPARQL查询。
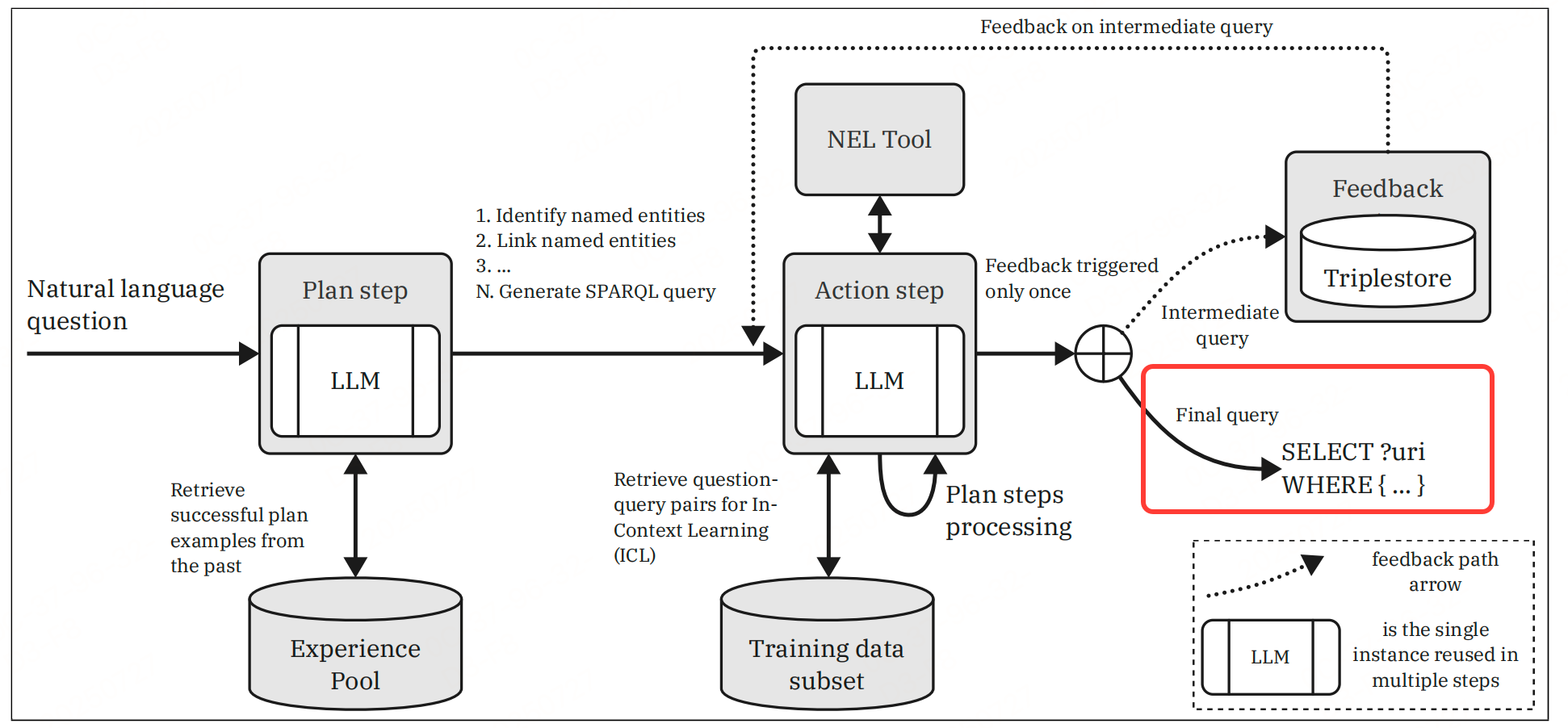
2.1 带经验池的计划步骤(Plan Step with Experience Pool)
利用经验池中相似问题的成功计划优化当前计划,提升子任务分解的准确性。

- 将输入问题( q i q_i qi)转换为向量( v q i v_{q_i} vqi);
- 从经验池中检索Top-N个高F1分数的相似计划;
- 将这些计划融入系统提示( S plan experience S_{\text{plan}}^{\text{experience}} Splanexperience),引导LLM生成更优计划( p i p_i pi)。
2.2 带经验池的行动步骤(Action Step with Experience Pool)
结合经验池中相似问题的SPARQL示例,优化查询生成过程,同时支持反馈步骤的结果整合。

- 检索经验池中Top-N个相似SPARQL查询,融入行动阶段的系统提示( S action experience S_{\text{action}}^{\text{experience}} Sactionexperience);
- 按计划执行子任务,调用NEL工具,并可结合反馈结果调整查询。
3.2.3 反馈步骤(Feedback Step)
通过执行初步查询并分析知识图谱的返回结果,修正查询错误,模拟人类“试错-改进”的推理过程。

- 将初步生成的SPARQL查询( φ \varphi φ)在三元组存储中执行,获取返回结果( A i \mathcal{A}_i Ai);
- 将结果填入反馈提示模板( S feedback ′ S_{\text{feedback}}' Sfeedback′),返回给行动步骤;
- 行动步骤根据反馈优化查询,输出最终结果(仅触发一次,避免无限循环)。
实验性能
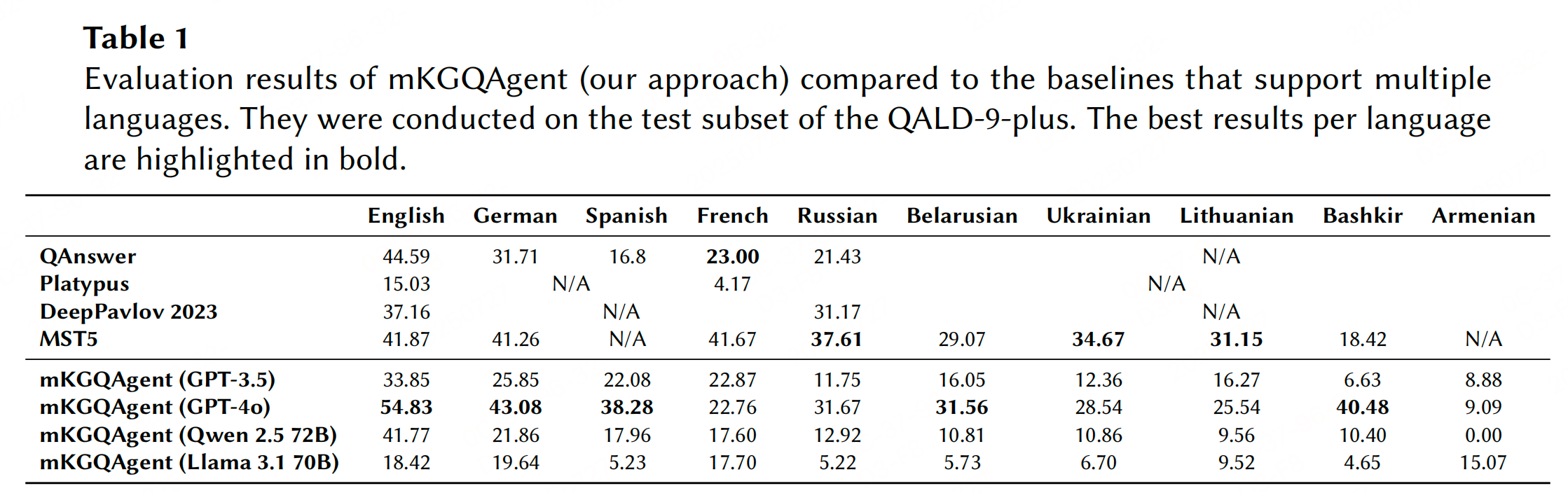
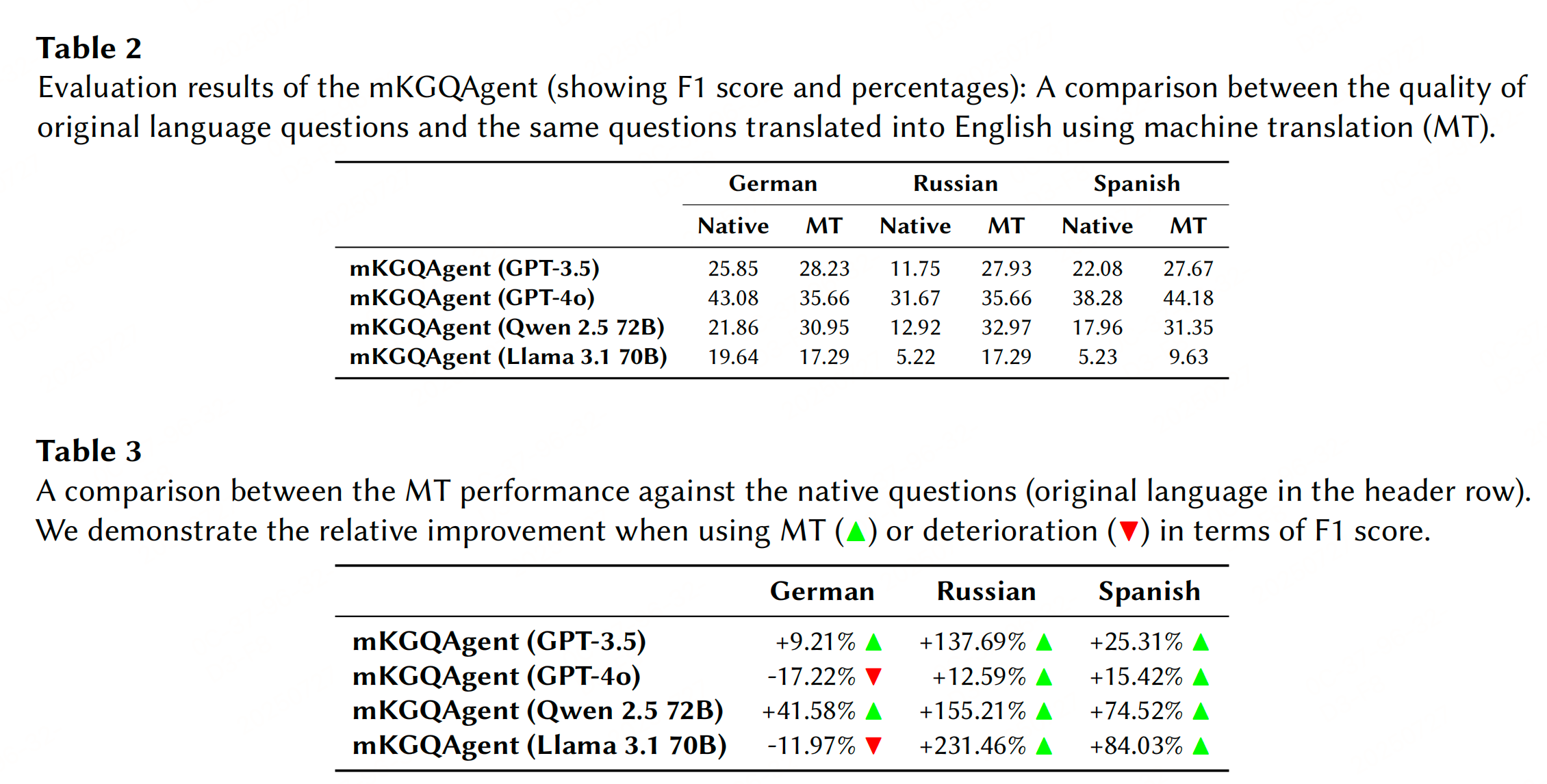
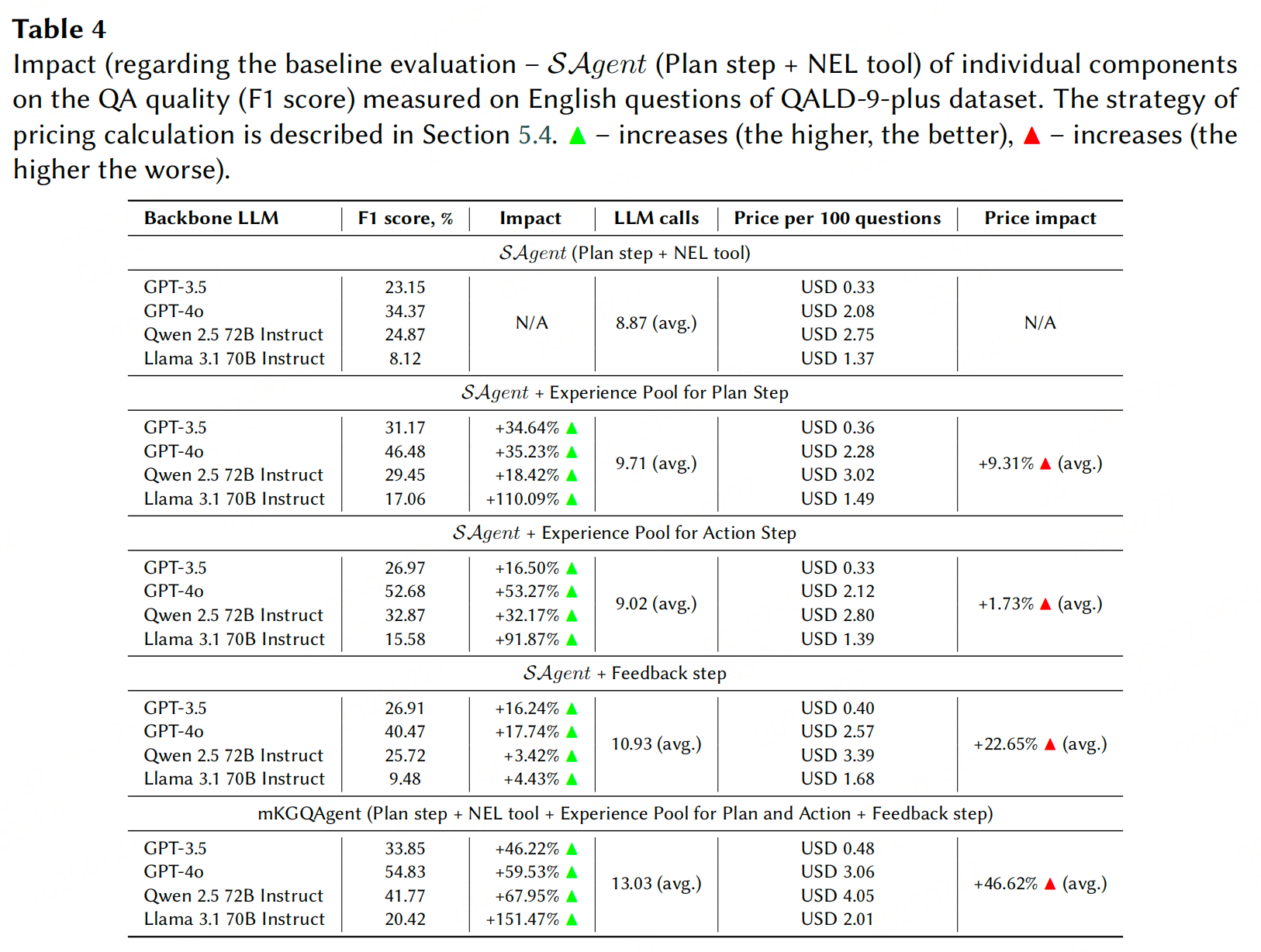
参考文献:Text-to-SPARQL Goes Beyond English: Multilingual Question Answering Over Knowledge Graphs through
Human-Inspired Reasoning,https://arxiv.org/pdf/2507.16971v1

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)