大模型压缩技术
引言
近来,LLM以惊人的推理效果惊艳全世界,这得益于它巨大的参数量与计算任务。以GPT-175B模型为例,它拥有1750亿参数,至少需要320GB(以1024的倍数计算)的半精度(FP16)格式存储空间。此外,为了有效管理操作,部署该模型进行推理至少需要五个A100 GPU,每个GPU配备80GB内存。巨大的存储与计算代价让有效的模型压缩成为一个亟待解决的难题。
一、模型压缩
1.1 什么是模型压缩
模型压缩(Model Compression)是一种通过减少机器学习模型的复杂度、存储占用或计算资源消耗,同时尽量保持其性能的技术,模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署。其核心目标是在资源受限的设备(如移动设备、边缘计算设备)上高效部署模型,或加速模型推理/训练过程。
- 人脸识别、人脸特效的模型集成在手机端,如何将高度依赖硬件的模型部署在算力低的移动端:核心就是模型压缩。
模型压缩的目的是在不牺牲性能的情况下减少机器学习模型的大小。这适用于大型神经网络,因为它们常常过度参数化(即由冗余的计算单元组成)。
模型压缩的主要好处是降低推理成本,这意味着大模型(即在本地笔记本电脑上运行 LLM)的更广泛使用,人工智能与消费产品的低成本集成,以及支持用户隐私和安全的设备上推理。
模型压缩一句话来说就是将深度学习的参数变少或变小。
1.2 模型压缩的分类
模型压缩技术的范围很广,主要有3大类:
- 量化ーー用较低精度的数据类型表示模型
- 修剪ーー从模型中删除不必要的组件
- 知识蒸馏ーー用大模型训练小模型
这些方法是相互独立的。因此,来自多个类别的技术组合在一起可以获得最大的压缩。
二、剪枝
2.1 剪枝介绍
剪枝指移除模型中不必要或多余的组件,比如参数,以使模型更加高效。通过对模型中贡献有限的冗余参数进行剪枝,在保证性能最低下降的同时,可以减小存储需求、提高内存和计算效率。剪枝分为两种主要类型:非结构化剪枝和结构化剪枝。
剪枝(Pruning)是模型压缩中的一种常用技术,旨在减少神经网络的复杂度和参数数量,从而提高模型的效率和减少计算资源的消耗。
2.2 剪枝分类
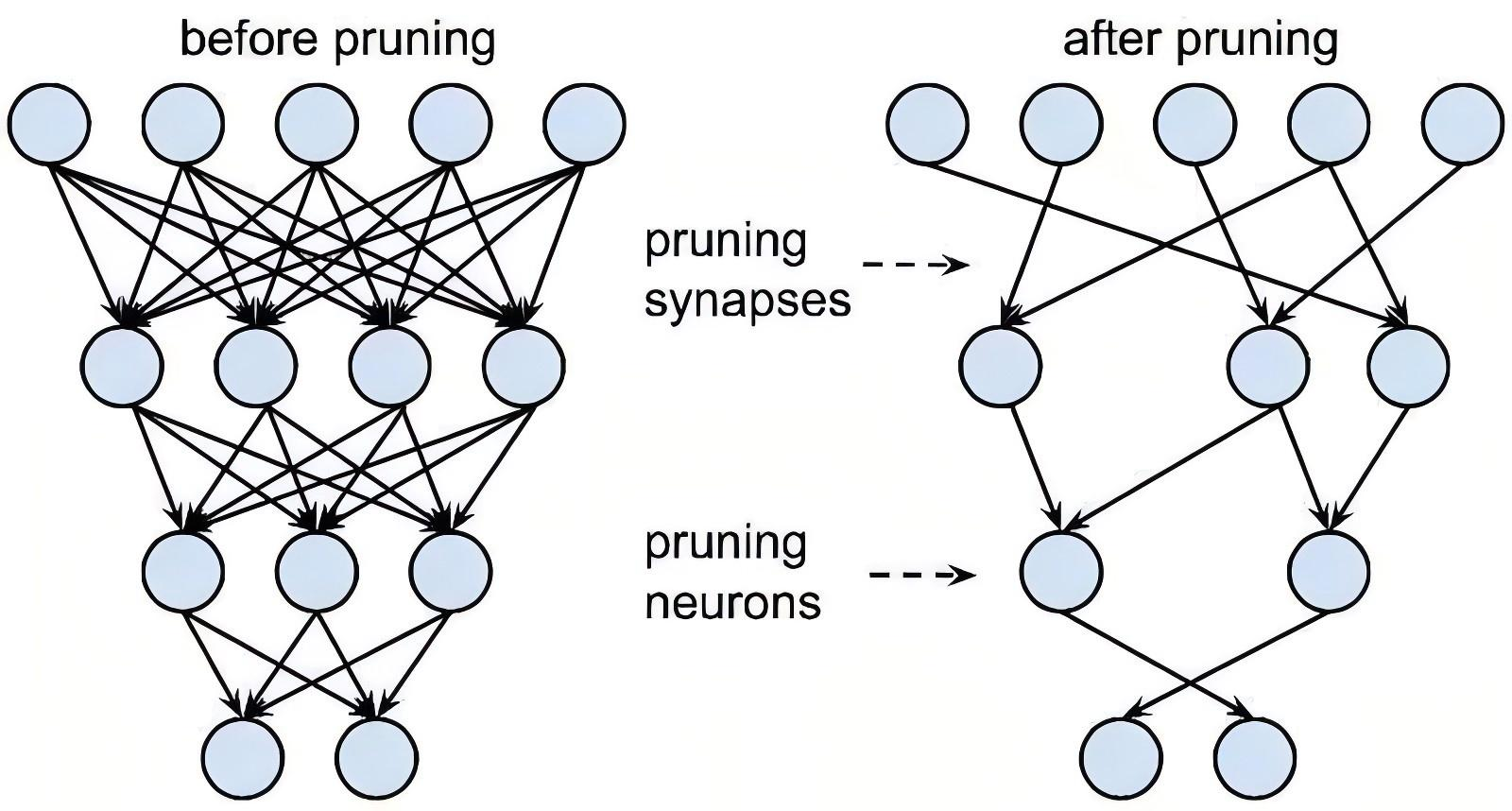
非结构化剪枝(突触修剪):其中一些连接被移除,网络变得更加稀疏。这种剪枝方式没有改变模型的结构,剪之前是4层,剪之后还是4层,他把某些层的一些参数给剪掉了,也就是参数变少了,模型的计算复杂度降低了,模型的存储量也降低了,模型跑的也更快了 , 这种方式剪枝之后他的精度损失较少一些,但是它依赖于特定的算法库或者硬件平台的支持。
这种方式没有什么实用性,因为对于我们而言,AI模型是个黑盒子,并不知道哪些参数对于你的任务来说是核心参数,有可能这种方式剪枝剪掉的就是最核心的参数。
结构化剪枝(神经元修剪):是指移除整个神经元及其所有连接。通常,这种剪枝是基于神经元的重要性进行的,移除那些对模型输出贡献较小的神经元。在图中,非结构化剪枝(突触剪枝)之后,进一步进行了结构化剪枝(神经元)剪枝。可以看到,一些神经元被完全移除,这进一步减少了网络的复杂度和参数数量,这种方式破坏掉了模型原的结构,模型的精度就会降的比较差,结构化剪枝的特点是操作起来比较简单,不受硬件平台或者算法库的这种限制。
任何一个平台,任何一个框架,它都是支持结构化剪枝的,但这种方式也没什么实用性。
总结:剪枝在大模型和小模型上商业价值都不大。
三、量化
3.1 量化介绍
量化(Quantization)是通过降低模型参数的数值精度来减少存储占用、内存消耗和计算开销,同时尽可能保持模型的性能。它在边缘设备(如手机、嵌入式芯片)和高效推理中应用广泛。
常规精度一般使用 FP32(32位浮点,单精度)存储模型权重;低精度则表示 FP16(半精度浮点)、INT8(8位的定点整数)等等数值格式。不过目前大模型中低精度往往指代 INT8。
混合精度(Mixed precision)在模型中使用 FP32 和 FP16 。 FP16 减少了一半的内存大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度。
- 存储模型参数时分为两部分:正在参与计算的参数和没有参与计算的参数,为了节约显存,把没有参与计算的参数以
fp16表示,为了增加计算结果的准确性,将参与计算的参数使用fp32表示。达到的效果:模型是fp16类型,训练过程是fp32类型。 - 以前的大模型数据都是
fp32类型,即Qwen的fp16已经是量化过的;
3.2 量化分类
(1) 按量化阶段分
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 训练后量化 | 直接对训练好的 FP32 模型进行量化,无需重新训练 |
简单快速,适合部署 | 精度损失可能较大 |
| 量化感知训练 | 在训练时模拟量化过程(如加入量化/反量化节点),让模型适应低精度 | 精度损失小,鲁棒性强 | 需重新训练,计算成本高 |
(2) 按量化粒度分
- 逐层量化:整个层的参数共享相同的量化参数(缩放因子和零点)。
- 逐通道量化:每个通道(如卷积核的输出通道)单独量化,精度更高。
(3) 按对称性分
- 对称量化:数值范围对称于零点(如
INT8的[-127, 127]),计算简单。 - 非对称量化:数值范围不对称(如
INT8的[-128, 127]),能更好适应数据分布。
3.3 量化的具体步骤
1、确定量化范围
-
统计张量的最大值(max)(max)(max) 和最小值 (mix)(mix)(mix)
-
对称量化:范围取值 [−a,a][-a, a][−a,a] (如:a=max(∣max∣,∣min∣)a = max(|max|, |min|)a=max(∣max∣,∣min∣))
-
非对称量化:范围取值 [min,max][min, max][min,max]
2、计算缩放因子(Scale)和零点(Zero Point)
-
缩放因子:scale=max−min2n−1scale = \frac{max - min} {2^n - 1}scale=2n−1max−min
-
零点:zero_point = round(0−minscale)round(0- \frac{ min} {scale})round(0−scalemin)
3、量化(Quantization)
- 将浮点数值 (x) 映射到整数:
4、反量化(Dequantization)
3.4 量化原理
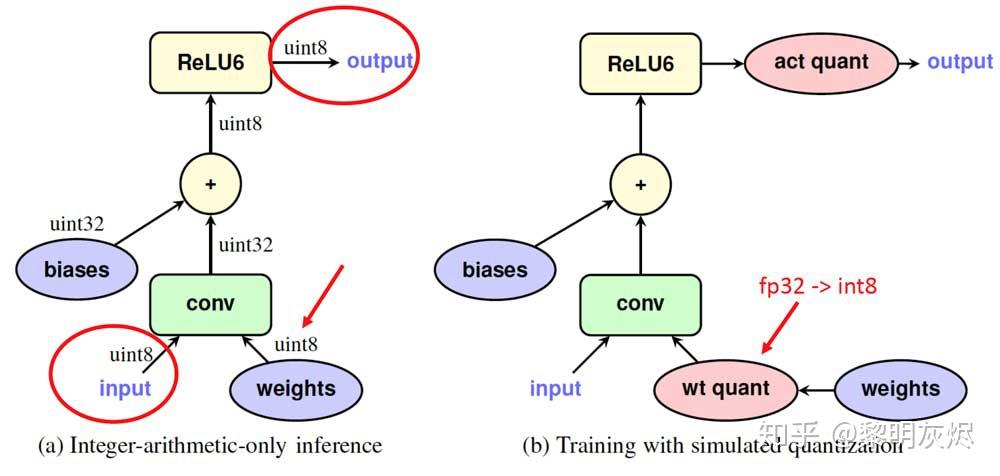
左侧图代表推理过程中的量化:
- 输入(
input):输入数据被量化为8位无符号整数(uint8),我们的输入本来是32位的也要也要量化成8位的。 - 权重(
weights):权重同样被量化为8位无符号整数(uint8)。 - 卷积(
conv):使用量化后的输入和权重进行卷积操作(中间进行反量化,将输入数据和需要计算的权重反量化为32位无符号整数),输出结果为32位无符号整数(uint32)。 - 偏置(
biases):偏置值被量化为32位无符号整数(uint32),并在卷积操作后加到卷积结果上(可以理解为是人为定义的一个参数)。 ReLU6激活函数:应用ReLU6激活函数,将输出结果被量化为8位无符号整数(uint8)。- 输出(
output):最终的输出数据也是8位无符号整数(uint8)。
右侧图代表训练过程中的量化:
• 输入(input):输入数据保持为浮点数(fp32)。
• 权重(weights):权重在训练过程中被全部模拟量化为8位整数(int8),相当于在计算的过程中按照低精度去计算,因为这样算起来很快。
- 虽然这样算起来很快,但是训练的结果也会变差,但是没关系,训练的过程他可以多训练几次,这样做节约了显存和算力。
• 卷积(conv):使用浮点数(fp32)输入和量化后的权重进行卷积操作,输出结果为浮点数(int8)。
• 偏置(biases):偏置值(int8),并在卷积操作后加到卷积结果上。
• ReLU6激活函数:应用 ReLU6 激活函数,输出结果经过激活量化(act quant)处理,模拟量化的效果。
• 激活量化(act quant):模拟量化激活函数的输出,使其看起来像是量化后的输出(fp32)。
这种方式是输入输出都是32位,但是在计算的时候是8位,这是以前的做法;现在的做法是在训练时用到的那些参数仍然会反量化成32位。
3.5 量化的本质
量化的本质就是将一个数据限制到可度量的范围之内。我们数据有两种:
-
第一种是常见的数据集是有范围的,它一定存在最小值和最大值;
-
第二种是有些数据它是无范围的或者是理论上的数据,他可能是一个理想状态或者说我们的集合比较大的情况,他存在一些理论数据。理论数据是无法穷举出来的,这类数据可能表示为连续的或理论上无限的范围;
- 例如浮点数或某些科学计算中的数据。
这两种数据,不管是有范围还是没范围,它都不利于我们进行数据的一个控制。
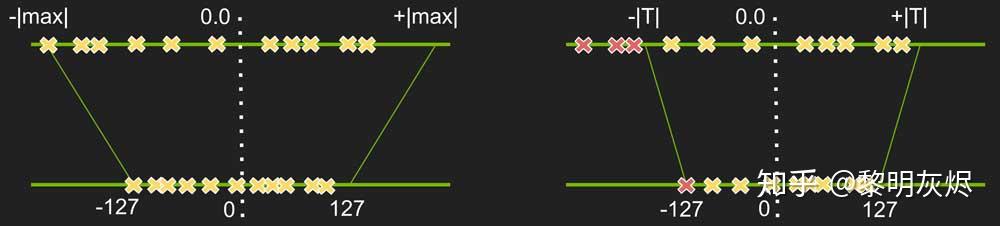
-
左侧代表有范围的数据:将数据压缩到
-127到127之间,方法是:拿每个数据去除max。 -
右侧代表没范围的数据:将数据压缩到
-127到127之间,得用期望和方差去处理。
量化和归一化是一回事儿,本质上来讲归一化是一种特殊的量化,归一化是把数据归到 -1 到 1 之间,但是量化是把数据压缩到一个可控范围内,这可控范围内可以为任意范围。
量化现在在商业应用上比较多,因为量化有极大的的价值:
可控:把32位变成16位,它的权重一定减少了一半,16位再降到8位,它的权重的这个存储又降了一半,这是固定的,虽然权重的位数降低了,对于模型这个精度的影响,但这个影响是非常小的,因为AI求的是个趋势,而不是具体的数值。
为什么说数据做了量化之后,它这个趋势会有一定的偏差呢?
模型的参数本身就存在偏差,那么一旦这个数据的精度调整之后,它一定程度上会放大这个偏差或者误差,因此这个趋势会有一些变化,所以精度上面一定会有变化的,只是说这种变化非常的小。
目前验证出来的结果是这样的:如果说模型精度是 fp32 ,量化到 fp8,这个体积变为原来的1/4,就意味着比如说以前一个模型的权重是400兆,量化到8位后只有100兆了,体积变了原来的4分之1。但这个精度的降低一般是在 0.1% 到 0.3% 之间一个误差。这个误差是非常微弱的,一般不超过 0.3% 的一个误差,它带来的收益是很明显的。
所以这是为什么看我们现在大模型全部用的 16 位的精度来存储。因为AI大模型还看另外一个东西:参数的数量,它带来的收益性要远远的大于精度的影响。
四、知识蒸馏
4.1 什么是知识蒸馏
知识蒸馏(Knowledge Distillation)是一种机器学习中的模型压缩技术,旨在将一个复杂模型(比较大的模型,因为模型越大效果越好,通常称为教师模型,Teacher Model)的知识迁移到一个更简单、更高效的模型(学生模型,Student Model)中,同时尽量保留原模型的性能。这种方法由 Hinton 等人在2015年提出,广泛应用于深度学习领域,尤其在资源受限的场景(如移动设备、边缘计算)中。
4.2 知识蒸馏的原理
先把最开始训练好的大模型,当作做教师模型(teacher network),然后再设计一个更小的模型,这个模型作为是学生模型(student network)。由于设备的显存和算力无法满足教师模型的需求,学生模型的参数规模会更小。从AI理论上来讲,如果模型规模不足,直接在数据集上训练往往无法取得理想效果,无论如何优化,其性能也难以达到教师模型的水平。
通过知识蒸馏让学生模型跟着教师模型学习,就可以达到学生模型输出的效果接近甚至于与教师模型一致。
教师模型不参与训练,把数据集同时给到教师模型和学生模型,在学生模型输入了一个数据之后,就会得到一个输出,根据学生模型的输出和原有的数据的标签去做损失计算,这就得到一个常规的分类损失(硬标签损失):学生输出与真实标签的交叉熵。因为学生模型很小,所以单独拿数据训练它的效果一直都很差,始终都得不到一个很理想的效果。
于是教师模型的作用就发挥出来了,把相同的数据同时给到教师模型时(因为教师已经训练过了,并且它的效果很好),这时就会得到一个输出接近于正确答案的特征。因为教师模型比较大,所以它对数据的理解能力很强,他得到的特征向量的效果非常好,它具有极高的参考意义。
之后把教师模型输出的特征给到学生模型,然后把学生模型(基于教师模型输出的特征)再输出的特征跟教师模型输出的特征再做一个相似度的损失计算,获得蒸馏损失(软标签损失):学生输出与教师输出的相似度,这个损失的目的是让学生模型去学习教师模型输出的特征,这样学生模型接收到数据后,在训练时中它会有两个参考:
-
第一个参考是**常规的分类损失:**他对这个数据本身的特征理解。
-
第二个参考是蒸馏损失: 教师模型给到他一个标准的特征答案。
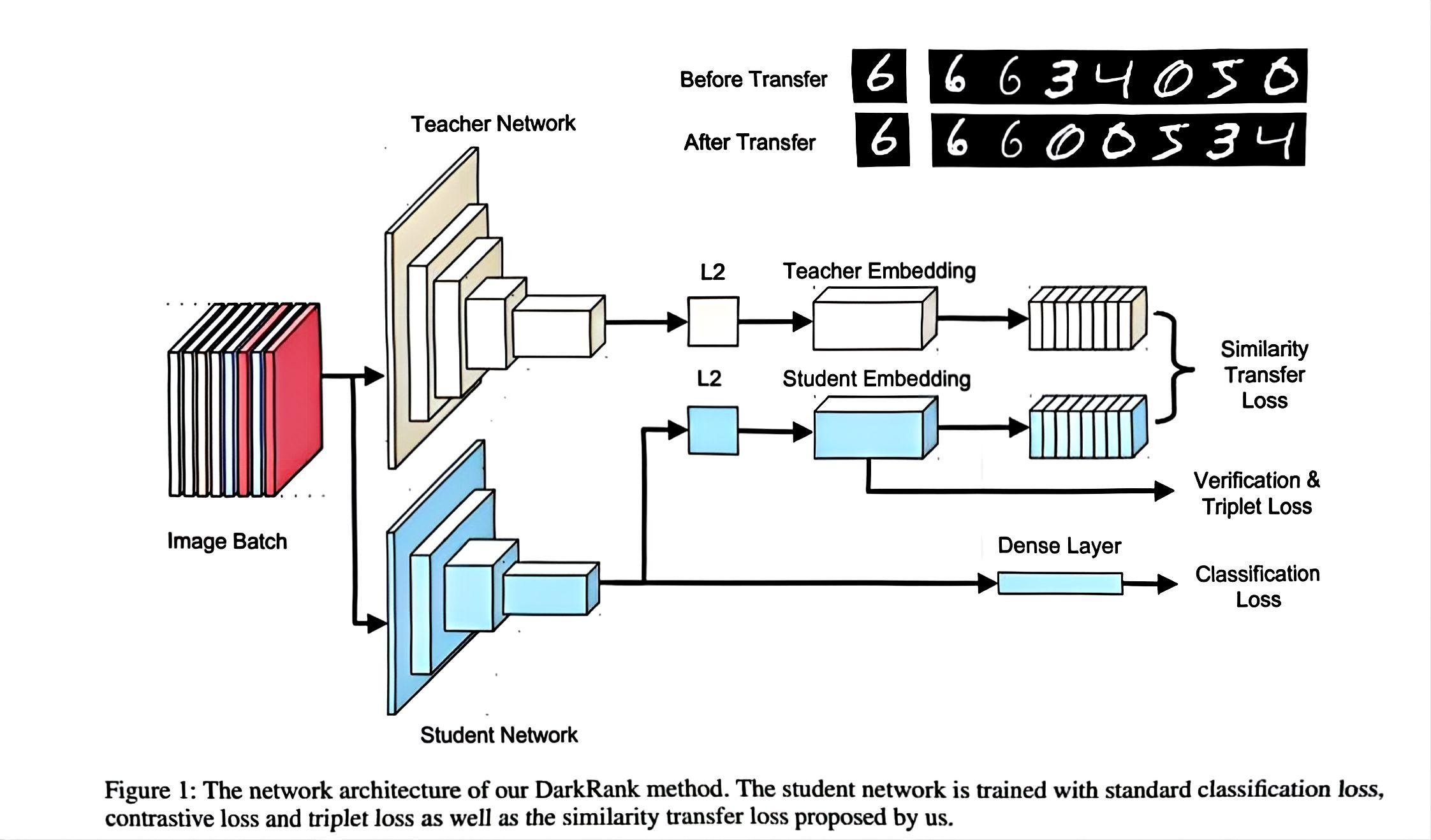
本质上来讲学生模型与教师模型都是神经网络,所以说这个特征对于学生模型的参考意义会非常的大,它会带来一个很神奇的效果:我们用两个损失同时去训练这个学生模型,他训练的会非常快(就像你在考试,旁边给你安排了个清华教授,你刚做出了一道题,教授直接把答案告诉你,你再参考答案去考试,那肯定快咯)。
学生模型在训练时候有两个损失,那么学生模型应该更加偏向于哪个损失呢?
-
在开始的时候,学生模型更加偏向教师模型提供的特征输出的损失去调整自己的损失,它会更加偏向于第一个损失,比如说最开始教师输出的特征损失权重参考设置为
0.9,参考意义很大,学生模型根据数据与所得的损失最开始权重0.1。(这样设置的原因很简单:因为一开始你是小白,自己答案就是错的,你就照抄老师的答案就完事儿了)。 -
每参考一次学生模型的能力都会有所提升,慢慢的学生模型得自己学会独立的去处理这个数据,这个时候设置教师输出特征损失权重逐渐的降低(比如说
0.9降到0.7,降到0.6,降到0.1),然后学生模型对这个数据原生的理解会逐渐的升高(比如由0.1升到0.3再升到0.4,最后升到0.9),最后完全脱离教师模型,学生模型就可以独立的理解这个数据了。这时候学生模型的性能可能接近或超过教师模型,这就是知识蒸馏。
4.3 知识蒸馏流程
4.3.1 教师模型和学生模型同时参与训练
教师模型是固定的:在蒸馏阶段,教师模型已经预训练完成,其参数被冻结(不更新) ,仅作为“参考答案生成器”。
学生模型是待训练的:只有学生模型的参数会通过反向传播更新。
关键点:“同时”,是指同一批输入数据会前向传播两次(一次通过教师模型,一次通过学生模型),但只有学生模型的输出会参与梯度计算。
4.3.2 两种损失的计算与融合
1)教师模型的输出(软标签)
- 输入数据 ( x ) 通过教师模型,得到输出概率分布qteacherq^{teacher}qteacher(使用带温度系数 ( T ) 的Softmax):
qiteacher=exp(ziteacher/T)∑jexp(zjstudent/T)q_{i}^{teacher} = \frac{exp(z_{i}^{teacher}/T)} {\sum_{j}exp(z_{j}^{student}/T)}qiteacher=∑jexp(zjstudent/T)exp(ziteacher/T)
温度系数 ( T ) :放大教师模型输出的类别间差异(例如,( T>1 ) 时概率分布更平滑)。
2)学生模型的输出
- 同一数据 ( x ) 通过学生模型,得到输出概率分布qstudentq^{student}qstudent(使用相同 ( T ):
qistudent=exp(zistudent/T)∑jexp(zjstudent/T) q_{i}^{student} = \frac{exp(z_{i}^{student}/T)} {\sum_{j}exp(z_{j}^{student}/T)} qistudent=∑jexp(zjstudent/T)exp(zistudent/T)
4.3.3 损失函数组合
学生模型的优化目标是两类损失的加权和:
Ltotal=a⋅Lhard+(1−a)⋅Lsoft L_{total} = a·L_{hard} + (1 - a)·L_{soft} Ltotal=a⋅Lhard+(1−a)⋅Lsoft
分类损失(Hard Loss) :学生输出与真实标签 ( y ) 的交叉熵:
Lhard=−∑yilog(qistudent) L_{hard} = -\sum{y_i log(q_{i}^{student})} Lhard=−∑yilog(qistudent)
通常使用温度 ( T=1 )(即标准Softmax)。
蒸馏损失(Soft Loss) :学生输出与教师输出的KL散度:
Lsoft=T2⋅KL(qteacher∣∣qstudent)L_{soft} = T^2·KL(q_{teacher} || q_{student})Lsoft=T2⋅KL(qteacher∣∣qstudent)
T2T^2T2用于平衡温度缩放的影响(梯度量级)。
4.3.4 学生模型如何“参考”教师模型
梯度信号来源:
在反向传播时,总损失(LtotalL_{total}Ltotal)的梯度同时包含两部分:
-
来自真实标签的监督信号(修正学生的基础分类能力)。
-
来自教师模型的软标签信号(传递教师学到的“暗知识”,如类别间相似性)。
动态权重(aaa)
-
若(aaa)较小(如0.1),学生更依赖教师的软标签(适合早期训练或学生模型较弱时)。
-
若(aaa) 较大(如0.9),学生更依赖真实标签(适合后期训练或教师模型不完美时)。
注意:许多实际应用直接固定(aaa)(如0.5),动态调整并非必须。
在知识蒸馏的温度缩放软标签(Temperature-scaled Softmax)公式中:
qiteacher=exp(ziteacherT)∑jexp(zjteacherT) q_{i}^{teacher} = \frac{exp(\frac{z_{i}^{teacher}} {T})} {\sum_{j}exp(\frac{z_{j}^{teacher}} {T})} qiteacher=∑jexp(Tzjteacher)exp(Tziteacher)
4.4 知识蒸馏在大模型中的应用
知识蒸馏在训练大模型时有成本,以前提出知识蒸馏是为了把模型变小,但是现在是为了快速达到大模型的效果(deepseek 模型的基座就是蒸馏的 openAI 的模型,节约了大量成本),注意:蒸馏只能达到或逼近大模型的效果,如果想超越大模型需要再次加强模型。
把模型设计的很大(
deepseek原生模型很大,是为了学习openAI大模型的能力),用一个大模型学习另外的大模型(前提:我的模型不比大模型的体量小太多),蒸馏一定是有效的,且是学习最快的一种方法。
DeepSeek团队展示了较大模型的推理模式可以被蒸馏到较小模型中,与通过强化学习在小模型上训练的推理模式相比,蒸馏后的模型表现更佳。
如下图:DeepSeek 模型是基于 Qwen 架构进行蒸馏的: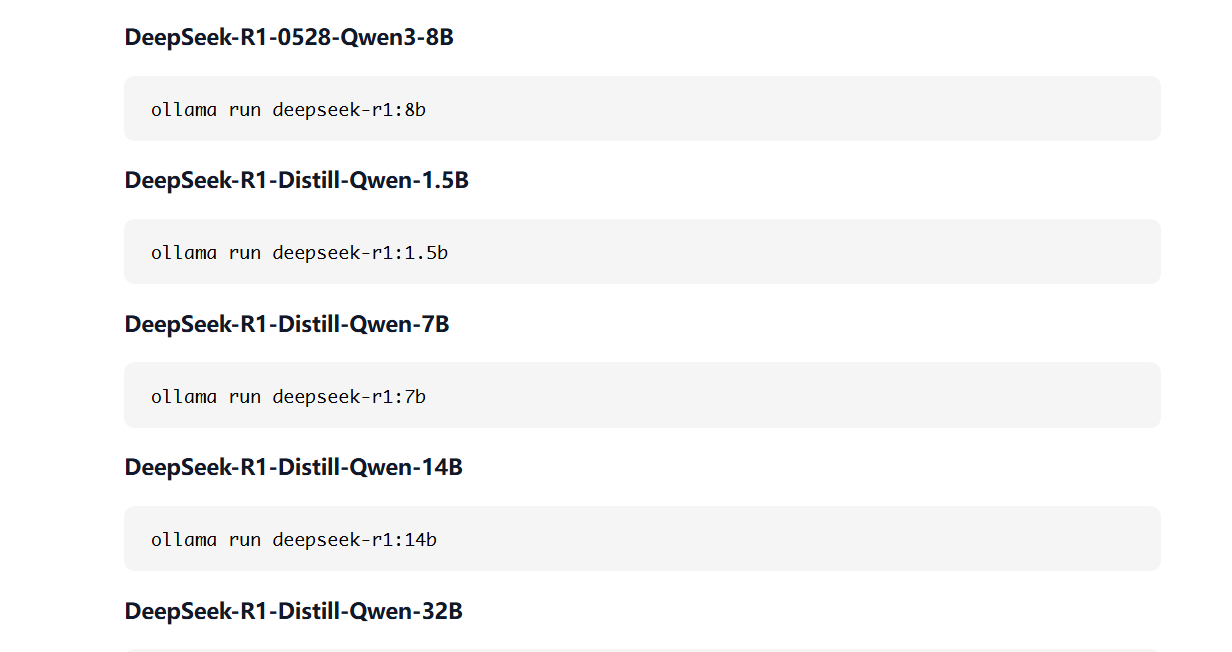
deepSeek-R1-Distill-Qwen-1.5B指的是一个15亿参数(1.5B)的、基于Qwen-1.5B模型的、通过知识蒸馏技术从更大的DeepSeek-R1模型中提取出来的轻量级版本。
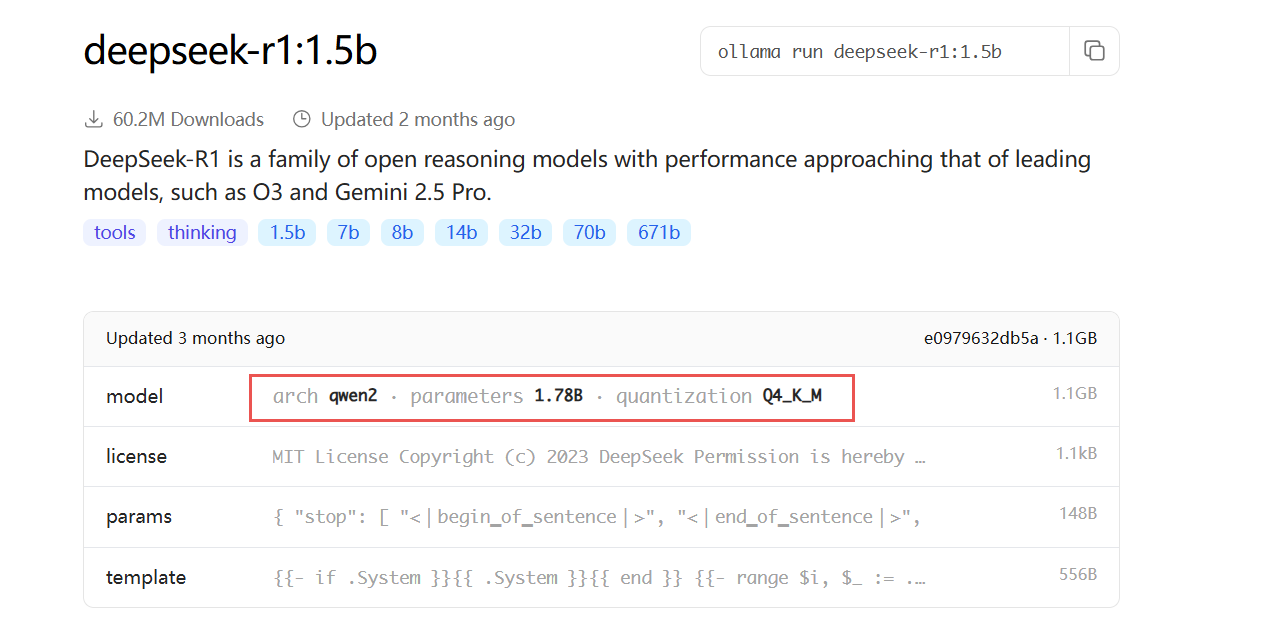
知识蒸馏在DeepSeek中的核心意义:
1、降低算力与成本
DeepSeek 通过蒸馏技术将模型训练成本压缩至 0penAI 同类模型的1/20。
- 例如,
DeepSeek-V3仅消耗278.8万GPU小时(成本约557.6万美元),而0penAI类似模型的训练成本高达49亿美元。这种低成本特性使中小企业也能负担高性能AI模型的开发。
2、加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊断、自动驾驶等场景的低延迟需求。
3、推动行业应用落地
-
教育领域:
DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策略,降低教育平台运营成本。 -
工业场景: 木地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助力智能制造中的质检、供应链优化等任务。
-
内容创作: AI写作工具结合蒸馏模型,创作效率提升
50%,同时API调用成本仅为0penAI的1/4,推动新媒体运营与创意产业发展。
4、技术自主可控
面对美国 GPU芯片禁运,DeepSeek 通过蒸馏技术降低对算力的依赖,结合 FP8 混合精度训练和DualPipe 流水线机制,在国产芯片(如华为昇腾)上实现高性能推理,增强中国AI产业的自主可控能力。
4.5 知识蒸馏代码
测试的代码如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AdamW
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
# ========== 配置参数 ==========
class Config:
# 模型设置
teacher_model_name = "Qwen/Qwen-7B"
student_model_name = "Qwen/Qwen-1.8B"
# 训练参数
batch_size = 16
num_epochs = 3
learning_rate = 2e-5
max_seq_length = 512
temperature = 5.0
alpha = 0.7 # 蒸馏损失权重
# 设备设置
device = "cuda" if torch.cuda.is_available() else "cpu"
grad_accum_steps = 4 # 梯度累积步数
config = Config()
# ========== 数据加载 ==========
class DistillationDataset(Dataset):
def __init__(self, tokenizer, sample_texts):
self.tokenizer = tokenizer
self.examples = []
# 示例数据(实际需替换为真实数据集)
sample_texts = [
"人工智能的核心理念是",
"大语言模型蒸馏的关键在于",
"深度学习模型的压缩方法包括"
]
for text in sample_texts:
encoding = tokenizer(
text,
max_length=config.max_seq_length,
padding="max_length",
truncation=True,
return_tensors="pt"
)
self.examples.append(encoding)
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
return {
"input_ids": self.examples[idx]["input_ids"].squeeze(),
"attention_mask": self.examples[idx]["attention_mask"].squeeze()
}
# ========== 模型初始化 ==========
def load_models():
# 加载教师模型(冻结参数)
teacher = AutoModelForCausalLM.from_pretrained(
config.teacher_model_name,
device_map="auto",
torch_dtype=torch.bfloat16
).eval()
# 加载学生模型
student = AutoModelForCausalLM.from_pretrained(
config.student_model_name,
device_map="auto",
torch_dtype=torch.bfloat16
).train()
return teacher, student
# ========== 蒸馏损失函数 ==========
class DistillationLoss:
@staticmethod
def calculate(
teacher_logits, # 教师模型logits [batch, seq_len, vocab]
student_logits, # 学生模型logits [batch, seq_len, vocab]
temperature=config.temperature,
alpha=config.alpha
):
# 软目标蒸馏损失
soft_teacher = F.softmax(teacher_logits / temperature, dim=-1)
soft_student = F.log_softmax(student_logits / temperature, dim=-1)
kl_loss = F.kl_div(
soft_student,
soft_teacher,
reduction="batchmean",
log_target=False
) * (temperature ** 2)
# 学生自训练损失(交叉熵)
shift_logits = student_logits[..., :-1, :].contiguous()
shift_labels = teacher_logits.argmax(-1)[..., 1:].contiguous()
ce_loss = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1)
)
return alpha * kl_loss + (1 - alpha) * ce_loss
# ========== 训练流程 ==========
def train():
# 初始化组件
tokenizer = AutoTokenizer.from_pretrained(config.teacher_model_name)
teacher, student = load_models()
# 数据集示例
dataset = DistillationDataset(tokenizer)
dataloader = DataLoader(dataset, batch_size=config.batch_size)
# 优化器设置
optimizer = AdamW(student.parameters(), lr=config.learning_rate)
# 混合精度训练
scaler = torch.cuda.amp.GradScaler()
# 训练循环
step_count = 0
student.to(config.device)
for epoch in range(config.num_epochs):
for batch_idx, batch in enumerate(dataloader):
inputs = {k: v.to(config.device) for k, v in batch.items()}
# 教师模型前向(不计算梯度)
with torch.no_grad(), torch.cuda.amp.autocast():
teacher_outputs = teacher(**inputs)
# 学生模型前向
with torch.cuda.amp.autocast():
student_outputs = student(**inputs)
loss = DistillationLoss.calculate(
teacher_outputs.logits,
student_outputs.logits
)
# 反向传播(带梯度累积)
scaler.scale(loss / config.grad_accum_steps).backward()
if (batch_idx + 1) % config.grad_accum_steps == 0:
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0)
# 参数更新
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
step_count += 1
# 学习率调整(示例)
lr = config.learning_rate * min(step_count ** -0.5, step_count * (300 ** -1.5))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 打印训练信息
if step_count % 10 == 0:
print(f"Epoch {epoch + 1} | Step {step_count} | Loss: {loss.item():.4f}")
# 保存蒸馏后的模型
student.save_pretrained("./distilled_qwen")
tokenizer.save_pretrained("./distilled_qwen")
if __name__ == "__main__":
train()

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)