从单智能体到多智能体都离不开的基础:深入理解LangGraph状态流转,大模型入门到精通,收藏这篇就足够了!
不少朋友留言说有些基础概念不太清楚,比如State到底是什么、节点之间怎么传递数据、为什么要用TypedDict等等。今天咱们就把这些知识点彻底讲透,保证你看完就能上手写代码。
昨天发了单智能体的文章后,不少朋友留言说有些基础概念不太清楚,比如State到底是什么、节点之间怎么传递数据、为什么要用TypedDict等等。今天咱们就把这些知识点彻底讲透,保证你看完就能上手写代码。
说实话,我刚学LangGraph的时候也是一头雾水。什么State、Node、Edge,听着挺玄乎的。但真正理解了State的运作机制后,突然就开窍了——原来整个框架就是围绕"状态"这个核心在转。无论是单智能体还是多智能体这些都是基础。
一、先把环境准备好
咱们先把开发环境搞定,后面代码都能直接跑起来。打开终端,依次执行:
# 安装核心包
pip install langgraph langchain-openai
# 安装可视化工具(可选,但强烈推荐)
pip install pyppeteer ipython
创建一个langgraph_demo.py文件,把API Key配置好:
import os
import getpass
# 设置OpenAI API Key
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("请输入你的OpenAI API Key: ")
好了,准备工作完成。接下来进入正题。
二、State到底是个啥?
很多教程上来就讲概念,我换个思路。咱们先看一个实际场景:
假设你要做一个简单的计算器程序,流程是这样的:
- 用户输入一个数字,比如10
- 第一步:给这个数字加1
- 第二步:用上一步的结果减2
- 最后输出结果
传统写法可能是这样:
def calculator(x):
x = x + 1 # 第一步
y = x - 2 # 第二步
return x, y
result = calculator(10)
print(result) # (11, 9)
这没问题,但如果流程复杂了呢?比如有10个步骤,每个步骤可能用到前面多个结果,代码就会很乱。
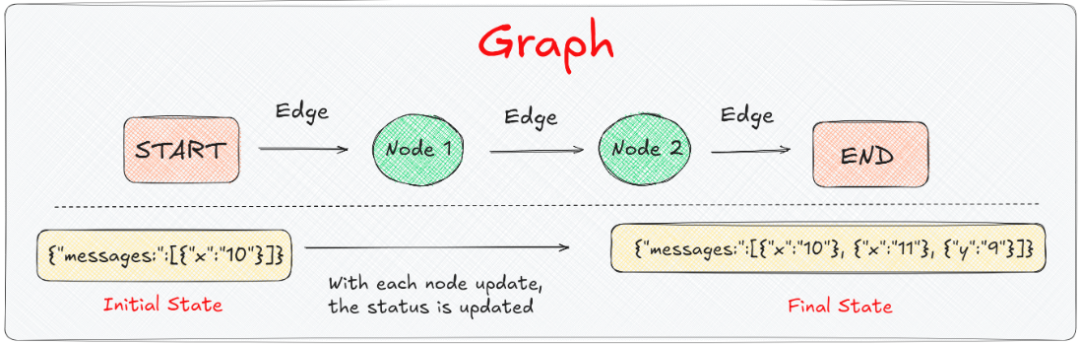
LangGraph的解决方案是:用一个共享的"状态"(State)来存储所有中间结果。每个处理步骤只需要:
- 读取State中需要的数据
- 处理完后,把结果写回State
- 不用管其他步骤的数据
这就是State的核心思想:一个在整个流程中共享的数据容器。
三、第一个例子:用字典做State
咱们把刚才的计算器用LangGraph实现一遍。完整代码如下,每行都加了注释:
from langgraph.graph import StateGraph, START, END
# 定义第一个节点:加法
def addition(state):
"""
这个函数会收到当前的state(一个字典)
从里面取出x的值,加1后返回
"""
print(f"加法节点收到的state: {state}")
current_x = state["x"]
new_x = current_x + 1
# 只返回更新的部分,不用担心其他数据会丢
return {"x": new_x}
# 定义第二个节点:减法
def subtraction(state):
"""
这个函数也会收到state
注意:这里的state已经包含了上一个节点更新后的x值
"""
print(f"减法节点收到的state: {state}")
current_x = state["x"]
y = current_x - 2
# 这里我们新增了一个y,x会保留
return {"y": y}
# 开始构建图
# StateGraph(dict)表示我们的state是一个普通字典
builder = StateGraph(dict)
# 添加两个节点
# 第一个参数是节点名称,第二个参数是对应的函数
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)
# 定义节点之间的连接关系(边)
# START -> addition -> subtraction -> END
builder.add_edge(START, "addition") # 起点连到addition
builder.add_edge("addition", "subtraction") # addition连到subtraction
builder.add_edge("subtraction", END) # subtraction连到终点
# 编译成可执行的图
graph = builder.compile()
# 运行!传入初始状态
initial_state = {"x": 10}
final_state = graph.invoke(initial_state)
print(f"\n最终状态: {final_state}")
运行这段代码,你会看到:
加法节点收到的state: {‘x’: 10}
减法节点收到的state: {‘x’: 11}
最终状态: {‘x’: 11, ‘y’: 9}
看到了吗?关键点来了:
- addition节点只返回了
{"x": 11},但y没有丢 - subtraction节点返回了
{"y": 9},x也还在 - 最终状态包含了所有的更新
这就是LangGraph的魔法:节点只需要返回它要更新的部分,其他数据会自动保留。
看看图长什么样
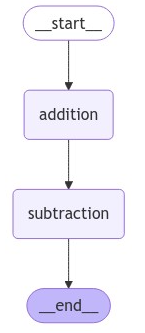
代码能跑是一回事,理解结构又是另一回事。咱们把这个图可视化出来:
from IPython.display import Image, display
# 生成图的可视化
# xray=True表示显示详细信息
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
你会看到一个流程图,清楚地显示了节点的连接关系。开发的时候这个功能特别有用,能一眼看出逻辑对不对。
四、进阶:用TypedDict让代码更严谨
用字典虽然灵活,但有个大问题:如果你不小心写错了key的名字,程序运行到那里才会报错。
比如这样:
def buggy_function(state):
# 假设state里没有"z"这个key
return {"result": state["z"] + 1} # 💥运行时报错
为了避免这种问题,实际开发中我们用
TypedDict
来定义State的结构:
from typing_extensions import TypedDict
# 定义State的结构
class State(TypedDict):
x: int # x是整数
y: int # y也是整数
# 现在用State来构建图
builder = StateGraph(State)
# 节点函数保持不变
def addition(state: State): # 加上类型标注
return {"x": state["x"] + 1}
def subtraction(state: State):
return {"y": state["x"] - 2}
# 后面的代码完全一样
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)
graph = builder.compile()
# 运行
result = graph.invoke({"x": 10})
print(result) # {'x': 11, 'y': 9}
用了TypedDict后,IDE会给你代码提示,写错了key名编辑器就会提醒你。虽然代码多了几行,但避免了很多低级错误。
五、Reducer:状态更新的幕后功臣
现在来解答一个关键问题:为什么节点只返回部分数据,State就能自动合并?
答案是Reducer函数。每个State的key背后都有一个Reducer,默认行为是"覆盖"。我画个图帮你理解:
当前State: {“x”: 10}
节点返回: {“x”: 11}
Reducer执行: 把x从10改成11
结果State: {“x”: 11}
当前State: {“x”: 11}
节点返回: {“y”: 9}
Reducer执行: x不变,新增y
结果State: {“x”: 11, “y”: 9}
默认的Reducer很简单,就是更新或新增。但我们可以自定义更复杂的行为。
六、实战:维护消息列表
聊天机器人需要记住对话历史,每次都要往消息列表里追加新消息。如果用默认的Reducer(覆盖),每次都会丢失之前的对话。
这时候就需要operator.add这个Reducer:
import operator
from typing import Annotated, List
from typing_extensions import TypedDict
# 注意这里的写法
class State(TypedDict):
# Annotated[类型, Reducer函数]
messages: Annotated[List[dict], operator.add]
# 测试一下
def node1(state):
# 返回一个包含新消息的列表
return {"messages": [{"role": "user", "content": "你好"}]}
def node2(state):
print(f"node2收到的消息: {state['messages']}")
# 再追加一条消息
return {"messages": [{"role": "assistant", "content": "你好啊"}]}
builder = StateGraph(State)
builder.add_node("node1", node1)
builder.add_node("node2", node2)
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)
graph = builder.compile()
# 初始状态包含一个空列表
result = graph.invoke({"messages": []})
print(f"\n最终消息列表: {result['messages']}")
运行结果:
node2收到的消息: [{'role': 'user', 'content': '你好'}]
最终消息列表: [
{'role': 'user', 'content': '你好'},
{'role': 'assistant', 'content': '你好啊'}
]
看到了吗?用了operator.add之后,每次返回的消息列表会追加到现有列表中,而不是覆盖。这就是Reducer的威力。
七、接入真实的AI模型
铺垫了这么多,终于到激动人心的部分了——接入GPT做一个真正能聊天的机器人!
完整代码如下,建议你创建一个新文件chatbot.py:
import os
import getpass
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from IPython.display import Image, display
# 配置API Key
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("请输入OpenAI API Key: ")
# 定义State结构
class State(TypedDict):
# add_messages是LangGraph提供的专门处理消息的Reducer
messages: Annotated[list, add_messages]
# 创建GPT模型实例
llm = ChatOpenAI(model="gpt-4o")
# 定义聊天节点
def chatbot(state: State):
"""
这个函数接收包含对话历史的state
把所有消息发给GPT,获取回复
"""
# state["messages"]是一个消息列表
# 直接传给模型就行
response = llm.invoke(state["messages"])
# 返回模型的回复,add_messages会自动追加到列表
return {"messages": [response]}
# 构建图
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
# 编译
graph = builder.compile()
# 可视化看看(可选)
# display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
# 单次对话测试
def test_single():
user_message = HumanMessage(content="你好,请介绍一下你自己")
result = graph.invoke({"messages": [user_message]})
print("用户:", user_message.content)
print("AI:", result["messages"][-1].content)
# 连续对话测试
def chat_loop():
print("聊天机器人已启动(输入'退出'结束对话)\n")
while True:
user_input = input("你: ").strip()
if user_input == "退出":
print("再见!")
break
if not user_input:
continue
# 每次都创建新的对话
# 如果要保持对话历史,需要把messages保存下来
for event in graph.stream({"messages": [HumanMessage(content=user_input)]}):
for value in event.values():
print(f"AI: {value['messages'][-1].content}\n")
# 运行
if __name__ == "__main__":
# test_single() # 测试单次对话
chat_loop() # 开启连续对话
运行这段代码,你就有了一个能对话的AI助手!
不过这个版本有个问题:每次对话都是独立的,没有记忆。要实现带记忆的版本,需要这样改:
def chat_with_memory():
"""带对话历史的聊天"""
print("聊天机器人已启动(输入'退出'结束对话)\n")
# 用这个列表保存整个对话历史
conversation_history = []
while True:
user_input = input("你: ").strip()
if user_input == "退出":
print("再见!")
break
if not user_input:
continue
# 把用户消息加入历史
conversation_history.append(HumanMessage(content=user_input))
# 用完整的历史调用模型
result = graph.invoke({"messages": conversation_history})
# 获取AI回复
ai_message = result["messages"][-1]
print(f"AI: {ai_message.content}\n")
# 把AI回复也加入历史
conversation_history.append(ai_message)
# 运行带记忆的版本
if __name__ == "__main__":
chat_with_memory()
现在你可以这样聊:
你: 我叫小明
AI: 你好小明!很高兴认识你…
你: 我刚才说我叫什么?
AI: 你刚才说你叫小明。
看,AI能记住之前的对话了!
八、add_messages的秘密
可能你注意到了,我们用的是add_messages而不是operator.add。这两个有什么区别?
operator.add很简单粗暴:直接把两个列表拼起来。
add_messages更聪明:
- 每条消息都有唯一ID
- 如果新消息的ID和已有消息相同,就更新那条消息
- 如果ID不同,就追加新消息
看个例子:
from langgraph.graph.message import add_messages
from langchain_core.messages import HumanMessage, AIMessage
# 场景1:追加新消息
msg1 = [HumanMessage(content="你好", id="1")]
msg2 = [AIMessage(content="你好啊", id="2")]
result = add_messages(msg1, msg2)
print("场景1 - 追加:", [m.content for m in result])
# 输出: ['你好', '你好啊']
# 场景2:更新已有消息
msg1 = [HumanMessage(content="你好", id="1")]
msg2 = [HumanMessage(content="你好呀", id="1")] # 注意ID相同
result = add_messages(msg1, msg2)
print("场景2 - 更新:", [m.content for m in result])
# 输出: ['你好呀'] # 第一条消息被更新了
这个特性在人机协作场景特别有用。比如用户可以修改AI的回复,然后继续对话。
九、源码解析:add_messages是怎么实现的?
有些同学喜欢刨根问底,咱们快速过一下核心逻辑(不想看可以跳过):
def add_messages(left, right):
"""
left: 已有的消息列表
right: 新来的消息列表
"""
# 1. 确保都是列表
if not isinstance(left, list):
left = [left]
if not isinstance(right, list):
right = [right]
# 2. 给每条消息分配ID(如果没有的话)
for m in left:
if m.id is None:
m.id = str(uuid.uuid4())
for m in right:
if m.id is None:
m.id = str(uuid.uuid4())
# 3. 建立ID到消息的映射
left_idx_by_id = {m.id: i for i, m in enumerate(left)}
# 4. 合并:ID相同就更新,不同就追加
merged = left.copy()
for m in right:
if m.id in left_idx_by_id:
# ID存在,更新
merged[left_idx_by_id[m.id]] = m
else:
# ID不存在,追加
merged.append(m)
return merged
核心就是用ID来判断是更新还是追加。简单但很实用。
十、完整项目:支持多轮对话的智能助手
最后把所有知识点整合一下,做个功能完整的聊天助手:
import os
import getpass
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
# ===== 配置部分 =====
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("请输入OpenAI API Key: ")
# ===== State定义 =====
class ChatState(TypedDict):
messages: Annotated[list, add_messages]
# ===== 创建模型 =====
llm = ChatOpenAI(
model="gpt-4o",
temperature=0.7, # 控制回复的创造性
)
# ===== 定义节点 =====
def chatbot_node(state: ChatState):
"""处理用户消息,生成回复"""
messages = state["messages"]
response = llm.invoke(messages)
return {"messages": [response]}
# ===== 构建图 =====
builder = StateGraph(ChatState)
builder.add_node("chatbot", chatbot_node)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
graph = builder.compile()
# ===== 主程序 =====
def main():
print("=" * 50)
print("智能聊天助手 v1.0")
print("=" * 50)
print("提示:输入'退出'结束对话\n")
# 设置系统提示词
conversation = [
SystemMessage(content="你是一个友好、专业的AI助手。回答要简洁明了。")
]
while True:
# 获取用户输入
user_input = input("👤 你: ").strip()
# 退出判断
if user_input.lower() in ["退出", "exit", "quit"]:
print("\n👋 感谢使用,再见!")
break
# 跳过空输入
if not user_input:
continue
# 添加用户消息
conversation.append(HumanMessage(content=user_input))
try:
# 调用图进行处理
result = graph.invoke({"messages": conversation})
# 获取AI回复
ai_response = result["messages"][-1]
conversation.append(ai_response)
# 显示回复
print(f"🤖 AI: {ai_response.content}\n")
except Exception as e:
print(f"❌ 出错了: {str(e)}\n")
# 出错时移除最后添加的用户消息
conversation.pop()
if __name__ == "__main__":
main()
这个版本包含了:
- ✅ 完整的对话历史管理
- ✅ 系统提示词设置
- ✅ 异常处理
- ✅ 友好的交互界面
直接运行就能用!
十一、常见问题答疑
Q1: State可以存储什么类型的数据?
A: 理论上任何Python对象都行:字典、列表、自定义类、甚至函数。但建议用简单的数据结构,方便序列化和持久化。
Q2: 节点函数可以不返回任何东西吗?
A: 可以。如果节点只是做一些副作用操作(比如打印日志),可以返回空字典{}或者None。
Q3: 怎么调试State的变化?
A: 在每个节点函数里加print(state),就能看到每一步State的变化情况。
Q4: TypedDict是必须的吗?
A: 不是必须的,但强烈推荐。它能帮你在开发阶段就发现很多类型错误。
Q5: 对话历史会越来越长,怎么办?
A: 这是个好问题。可以定期裁剪历史,只保留最近N条消息。或者用摘要技术压缩历史信息。后面的文章会详细讲。
十二、总结
今天我们深入学习了LangGraph的核心——State管理:
- State是什么:在整个流程中共享的数据容器
- 基本用法:节点读取State,处理后返回更新的部分
- TypedDict:让代码更严谨,避免运行时错误
- Reducer机制:控制State的更新方式(覆盖、追加等)
- add_messages:智能管理消息列表的专用Reducer
- 实战应用:构建带记忆的聊天机器人
掌握了这些,你就能灵活构建各种LangGraph应用了。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)