强化学习 - 第16章 - 西瓜书 - 笔记(上)(马尔科夫决策过程 - ϵ-贪心 - 蒙特卡洛方法 - On-Policy 同策略 - Off-Policy 异策略)
强化学习 (Reinforcement Learning, RL) 讨论的是智能体 (agent) 如何在复杂、不确定的环境 (environment) 中通过学习来最大化它能获得的累积奖励。在我们深入技术细节之前,先从你熟悉的监督学习出发,建立一个对强化学习的宏观认识。这对于理解其核心思想至关重要
16.1 任务与奖励
强化学习 (Reinforcement Learning, RL) 讨论的是智能体 (agent) 如何在复杂、不确定的环境 (environment) 中通过学习来最大化它能获得的累积奖励。
从监督学习到强化学习:一个宏观的理解
在我们深入技术细节之前,先从你熟悉的监督学习出发,建立一个对强化学习的宏观认识。这对于理解其核心思想至关重要。
监督学习和强化学习的异同:
- 相似点:两者都在学习一个“映射”。监督学习学习从“特征”到“标签”的映射,而强化学习学习从“环境状态”到“最优动作”的映射。从这个角度看,强化学习中的策略 (policy) 就好比是监督学习中的分类器或回归器。
- 核心区别:在于反馈机制。
- 监督学习:拥有明确的、即时的“标签” (ground-truth)。模型做出预测后,可以立即通过损失函数计算与真实标签的差距,然后直接优化。这就像一个学生做练习题,每道题都有标准答案。
- 强化学习:没有现成的“正确答案”。智能体必须先做出一个动作,然后从环境中获得一个反馈信号(奖赏)。这个奖赏往往是延迟的 (delayed),甚至是稀疏的 (sparse)。比如下围棋,可能要到几十步甚至最终棋局结束时,才能知道最初的几步是好是坏。这就是所谓的**“延迟标记信息”。智能体必须通过“事后反思”来判断之前的哪一步动作对最终结果贡献最大,这个过程也叫做“信用分配” (Credit Assignment) 问题**。
总而言之,如果说监督学习是“模仿式学习”,那么强化学习就是**“试错式学习” (Trial-and-Error Learning)**。
马尔可夫决策过程 (MDP)
强化学习任务通常使用马尔可夫决策过程 (Markov Decision Process, MDP) 作为数学框架来描述。它之所以重要,是因为它提供了一套形式化的语言来描述智能体与环境的交互过程。
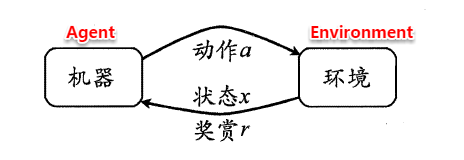
图 16.1 讲解:
这张图展示了强化学习的基本交互循环。
- 在 ttt 时刻,智能体观测到当前状态 xtx_txt。
- 基于状态 xtx_txt,智能体的策略 π\piπ 决定执行一个动作 ata_tat。
- 环境接收到动作 ata_tat 后,会转移到一个新的状态 xt+1x_{t+1}xt+1,并反馈给智能体一个即时奖赏 rt+1r_{t+1}rt+1。
这个 “状态-动作-奖赏” 的循环不断持续,智能体的目标就是通过调整其策略 π\piπ 来最大化未来的累积奖赏。
一个 MDP 由一个四元组 E=(X,A,P,R)E = (X, A, P, R)E=(X,A,P,R) 定义:
- XXX: 状态空间 (State Space),包含了智能体可能感知到的所有环境状态的集合。
- 为什么用 XXX? 这是数学上的惯例。在机器学习和数学中,通常用大写字母如 X,Y,ZX, Y, ZX,Y,Z 来表示一个集合或空间。这里的 XXX 代表状态 (State) 的全集。
- AAA: 动作空间 (Action Space),包含了智能体可以采取的所有动作的集合。
- PPP: 状态转移函数 (State Transition Function),P:X×A×X↦[0,1]P: X \times A \times X \mapsto [0, 1]P:X×A×X↦[0,1]。它定义了环境的动态。P(x′∣x,a)P(x' | x, a)P(x′∣x,a) 表示在状态 xxx 下执行动作 aaa 后,环境随机转移到状态 x′x'x′ 的概率。
- 为什么用 ×\times× (乘号)? 这里的 ×\times× 不是乘法,而是数学中表示 “笛卡尔积” (Cartesian Product) 的符号。X×A×XX \times A \times XX×A×X 表示这个函数 PPP 的“输入域” (domain)。它说明 PPP 接受一个组合作为输入,这个组合是一个元组 (tuple)
(状态, 动作, 下一个状态),例如 (x,a,x′)(x, a, x')(x,a,x′)。然后 PPP 会为这个特定的组合输出一个概率值。 - x′x'x′ 是可以计算出来的吗? 这是一个关键区别。在图 16.2 所示的随机 (stochastic) 环境中,我们不能“计算”出(即 100% 确定地预测)下一个状态 x′x'x′ 将是什么。我们能“计算”的是转移到任何一个特定 x′x'x′ 的概率。
- 例如:在“健康”状态下执行“不浇水”动作,我们无法计算出 x′x'x′ 就是 “缺水”。我们只能计算出 x′x'x′ 有 p=0.5p=0.5p=0.5 的概率是“缺水”,有 p=0.5p=0.5p=0.5 的概率是“健康”。
- 因此,x′x'x′ 本身是环境随机过程的一个结果 (outcome),而 P(x′∣x,a)P(x'|x,a)P(x′∣x,a)(即这个结果发生的概率)才是模型 PPP 允许我们“计算”或(在“有模型”学习中)“查询”到的东西。
- 图 16.2 中的概率 § 是怎么来的? 在这个例子中,这些概率是预先定义好的模型的一部分。我们假设我们对这个“西瓜生长”环境有充分的了解,知道浇水/不浇水后它会以怎样的概率变化。这属于 “有模型” (Model-based) 学习 的范畴,即环境的动态模型 (PPP 和 RRR) 是已知的。在更多实际情况中,这个模型是未知的(即 “免模型” learning),智能体必须通过与环境的大量交互来估计它。
- 为什么用 ×\times× (乘号)? 这里的 ×\times× 不是乘法,而是数学中表示 “笛卡尔积” (Cartesian Product) 的符号。X×A×XX \times A \times XX×A×X 表示这个函数 PPP 的“输入域” (domain)。它说明 PPP 接受一个组合作为输入,这个组合是一个元组 (tuple)
- RRR: 奖赏函数 (Reward Function),R:X×A×X↦RR: X \times A \times X \mapsto \mathbb{R}R:X×A×X↦R。它定义了智能体的目标。R(x,a,x′)R(x, a, x')R(x,a,x′) 表示在状态 xxx 执行动作 aaa 并转移到 x′x'x′ 后,智能体能获得的即时奖赏 (immediate reward)。
- 为什么映射到 R\mathbb{R}R? R\mathbb{R}R 代表实数集。奖赏可以是一个正数(奖励)、负数(惩罚)或零。
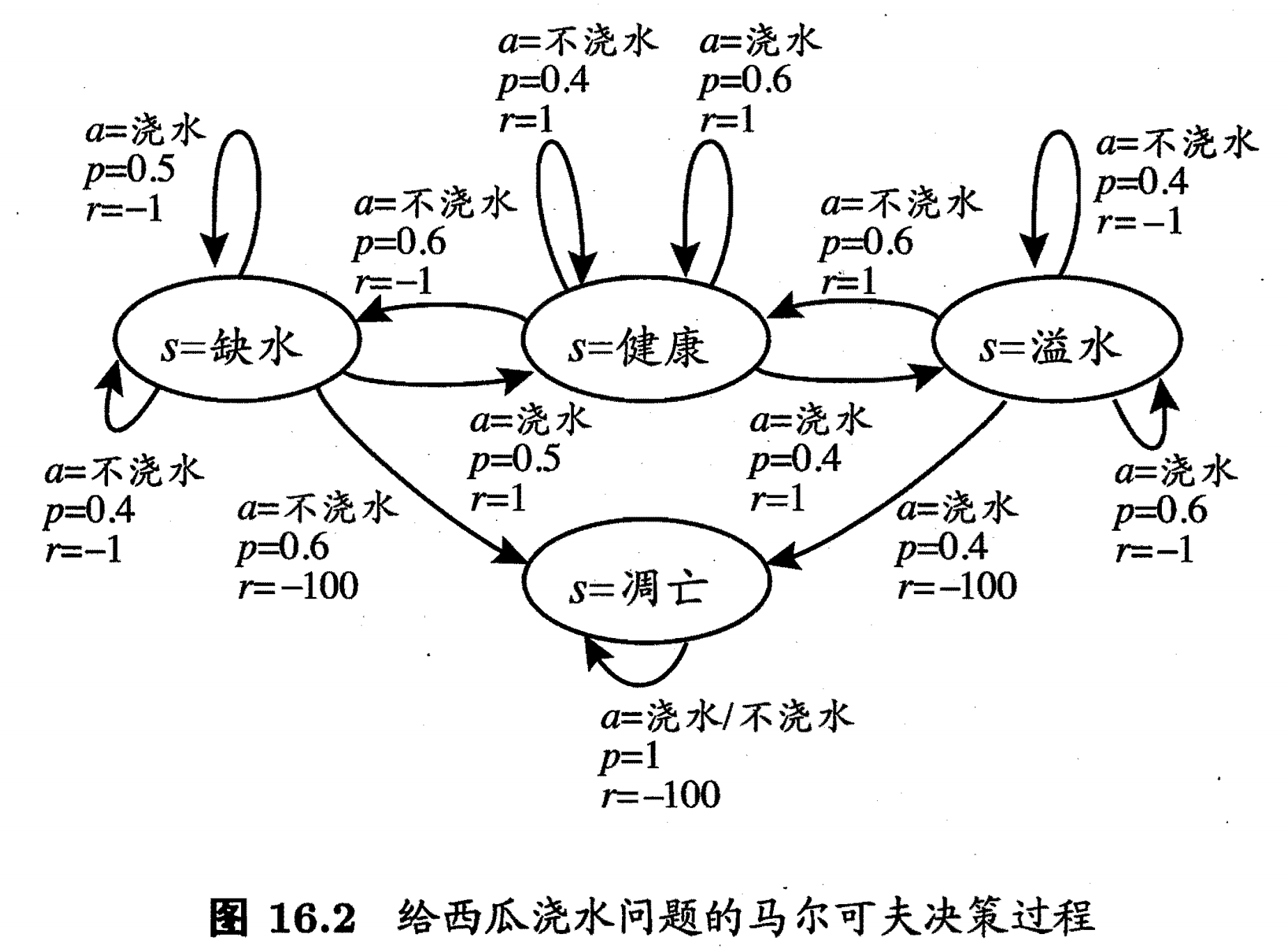

图 16.2 讲解:
这是一个具体的 MDP 示例,将抽象概念具象化。
- 状态 (s): 共有 4 个状态:{健康, 缺水, 溢水, 凋亡}。
- 动作 (a): 共有 2 个动作:{浇水, 不浇水}。
- 转移概率 §: 定义了环境的不确定性。例如,即使在 “健康” 状态下 “浇水”,也不能 100% 保证继续健康,存在 p=0.4p=0.4p=0.4 的概率会变为 “溢水”。
- 奖赏 ®: 提供了即时反馈。保持健康有正奖赏,进入不良状态有负奖赏,最终 “凋亡” 获得一个巨大的负奖赏,这强烈地指导智能体要避免这个结局。
- 终止状态: “凋亡” 是一个终止状态 (terminal state)。
-
这个例子和 MDP 是怎么来的?是人为建模的吗? 是的。图 16.2 是一个人为建模的、简化的环境模型。我们作为设计者,假设我们完全理解西瓜生长的所有规则(即状态转移概率 PPP)以及每种结果的好坏(即奖赏函数 RRR)。
- MDP 的局限性和环境建模的难度:
- MDP 最大的局限性在于它假设我们已知完美的环境模型(即 PPP 和 RRR)。
- 在现实中,这几乎是不可能的。 比如,在自动驾驶中,我们无法建立一个完美的数学模型来描述“在路口左转,撞上行人的概率是 0.01%”。
- 环境建模(即找出 PPP 和 RRR)是极其困难的。 这就是为什么强化学习分为两大流派:
- 有模型学习 (Model-based):先尝试学习环境模型 PPP 和 RRR(这本身就很难),然后再利用这个模型来计算最优策略。(图 16.2 的例子就是“有模型”的前提)
- 免模型学习 (Model-free):放弃对环境建模。智能体不去管 PPP 和 RRR 到底长什么样,它只管在环境中大量“试错”,直接根据获得的经验(即
(状态, 动作, 奖赏, 下一状态)四元组)来逐步优化自己的策略 π\piπ。
- 免模型学习(如 Q-Learning, Policy Gradient)是目前应用更广泛的方法,因为它绕过了“环境建模”这个难题。
- MDP 最大的局限性在于它假设我们已知完美的环境模型(即 PPP 和 RRR)。
策略 (Policy)
策略 (π\piπ) 是智能体的“大脑”,它决定了智能体在某个状态下应该采取什么动作。策略是强化学习算法最终要学习到的东西。
- 策略 (π\piπ) 是怎么来的?它是不是 RL 训练的对象?
-
- 策略是训练的核心对象:策略 π\piπ 就是强化学习要“训练”和“优化”的那个东西。在深度强化学习中,这个策略 π\piπ 通常就是一个神经网络。
-
- 它如何开始:在训练刚开始时,这个策略(神经网络)是随机初始化的。它完全不知道在什么状态该做什么动作,所以它的行为就像“瞎蒙”。
-
- 它如何更新:智能体使用这个随机策略去和环境交互,收集了大量经验(即历史奖赏)。然后,它会“反思”这些经验:
- “哦,上次我在状态 xxx 做了动作 aaa,结果导致我后来拿到了很高的累积奖赏,那么我下次再遇到 xxx 时,选择 aaa 的概率就应该提高一点。”
- “反之,如果一个动作导致了很差的后果(比如‘凋亡’),我就要降低这个动作的概率。”
-
- 最终目标:通过不断的“试错-反馈-更新”,策略 π\piπ 被逐步优化,最终收敛到一个能使其长期累积奖赏最大化的(近似)最优策略。
- 确定性策略 (Deterministic Policy): π:X↦A\pi: X \mapsto Aπ:X↦A。对于任意状态 xxx,策略都给出一个确定的动作 aaa。
- 随机性策略 (Stochastic Policy): π:X×A↦[0,1]\pi: X \times A \mapsto [0, 1]π:X×A↦[0,1]。π(a∣x)\pi(a|x)π(a∣x) 表示在状态 xxx 时,选择动作 aaa 的概率。
-
为什么定义里写 ↦R\mapsto \mathbb{R}↦R (实数),但又说是概率? 从严谨的数学定义上,函数输出的值域是实数集 R\mathbb{R}R,但我们额外增加了一个约束条件:对于同一个状态 xxx 下的所有动作 aaa,其概率之和必须为 1,即 ∑a∈Aπ(a∣x)=1\sum_{a \in A} \pi(a|x) = 1∑a∈Aπ(a∣x)=1。同时,每个概率值都在 [0,1][0, 1][0,1] 区间内。满足这些条件的实数就是概率。所以,虽然它输出的是实数,但这些实数必须符合概率的定义。
-
累积奖赏 (Cumulative Reward)
一个好的策略不能只看重眼前的即时奖赏,而应该追求长期的回报。因此,我们用累积奖赏来评估一个策略的好坏。
这个奖赏(Reward)是怎么来的?也是人为设计的吗?
- 是的,奖赏函数 RRR(即时奖赏)是人为设计的,它是整个强化学习问题的 “规则制定者”。
-
- RRR 是人为设计的:设计 RRR 的过程叫做 “奖赏工程” (Reward Engineering)。它告诉智能体“什么是好的,什么是坏的”。比如在西瓜例子中,我们规定“保持健康”奖赏 r=+1r=+1r=+1,“凋亡”奖赏 r=−100r=-100r=−100。
-
- RRR 在训练中固定不变:一旦设计好,RRR 就代表了任务的目标,在整个训练过程中是固定不变的。如果它变了,那任务本身就变了。
-
- RRR 是训练策略的核心驱动力:
- 我们人为设计了(固定的)即时奖赏 RRR。
- 由此推导出了(固定的)累积奖赏目标(例如 γ\gammaγ 折扣累积奖赏)。
- 策略 π\piπ 的全部训练目标,就是最大化这个固定的累积奖赏的期望值。
- 因此,奖赏函数 RRR 的设计至关重要,如果 RRR 设计得不好(比如,你只奖励“浇水”这个动作,而不关心西瓜的状态),智能体就会学到一个很荒谬的策略(比如疯狂浇水直到“溢水”)。
-
TTT 步累积奖赏:
E[1T∑t=1Trt] \mathbb{E}\left[\frac{1}{T} \sum_{t=1}^T r_t\right] E[T1t=1∑Trt]- rtr_trt 是什么? rtr_trt 是智能体在第 ttt 步获得的即时奖赏。
- 公式解读: 这个公式计算的是在有限的 TTT 步内,智能体能获得的平均奖赏。∑t=1Trt\sum_{t=1}^T r_t∑t=1Trt 是把这 TTT 步的所有即时奖赏加起来,除以 TTT 就是求平均。E[⋅]\mathbb{E}[\cdot]E[⋅] 表示求期望,因为策略和环境状态转移都可能是随机的,所以累积奖赏是一个随机变量,我们关心的是它的期望值。这种评估方式适用于一些有明确固定时长的任务。
-
γ\gammaγ 折扣累积奖赏:
E[∑t=0∞γtrt+1] \mathbb{E}\left[\sum_{t=0}^\infty \gamma^t r_{t+1}\right] E[t=0∑∞γtrt+1]- 公式解读: 这个公式用于评估无限时长的任务。它将未来每一步的奖赏 rt+1r_{t+1}rt+1 乘以一个折扣因子 (discount factor) γt\gamma^tγt。
- γ∈[0,1)\gamma \in [0, 1)γ∈[0,1):
- 这确保了即使是无限步数的奖赏加和,结果也会收敛为一个有限值。
- 这也符合经济学直觉:未来的奖励不如眼前的奖励有价值。γ\gammaγ 越接近 1,说明智能体越有“远见”,对未来的奖赏越重视;γ\gammaγ 越接近 0,则智能体越“短视”,更关心即时回报。
16.2 K-臂老虎机
在深入研究完整的多步 (multi-step) 强化学习问题(如 MDP)之前,我们先从一个简化的情况入手:K-臂老虎机 (K-armed bandit)。
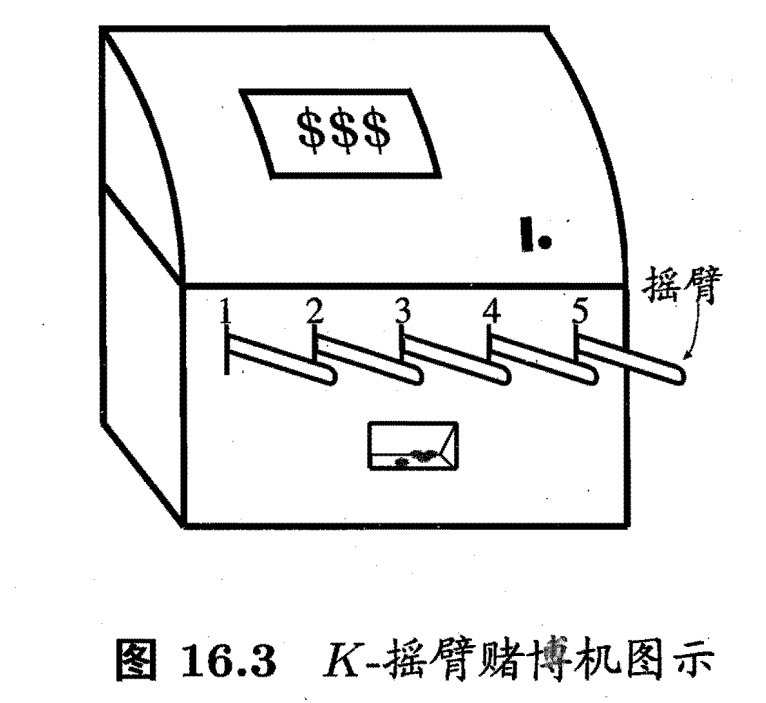

K-臂老虎机是一个 “单步强化学习任务” (single-step reinforcement learning task)。它被用来研究强化学习中的一个核心挑战:“探索与利用” (Exploration vs. Exploitation) 的窘境。
- K-臂老虎机: 如图 16.3 所示,想象有一台有 KKK 个摇臂的老虎机(也叫赌博机)。
- 动作 (Action): 在每一步,智能体(赌徒)选择一个摇臂 kkk 按下。
- 奖赏 (Reward): 智能体立即获得一个奖赏 vvv。
- 不确定性: 每个摇臂 kkk 的奖赏 vvv 并不是一个固定值,而是服从一个未知的概率分布。智能体只能通过多次尝试来估计每个摇臂的平均奖赏(期望奖赏)。
- 目标: 在有限的 TTT 次尝试中,最大化累积奖赏。
K-臂老虎机和完整的 MDP (马尔可夫决策过程) 有什么区别?
- 步数: K-臂老虎机是单步的。你做出一个动作(选摇臂),立刻得到奖赏,任务结束。MDP 是多步的,动作会引发状态转移,奖赏往往是延迟的 (delayed)。
- 状态 (State): K-臂老虎机问题没有“状态”的概念(或者说,它只有一个永不改变的单一状态)。无论你之前做了什么,你都面临着同样的 KKK 个摇臂。而在 MDP 中,你的动作会带你进入新的状态。
简而言之,K-臂老虎机是 MDP 的一个特例,它剥离了所有复杂性(如状态转移、延迟奖赏),只保留了“在不确定性中选择最优动作”这一个核心问题,因此它是研究**“探索-利用窘境”**的最佳模型。
16.2.1 探索与利用
为了最大化累积奖赏,我们显然希望“利用”我们已知的最好的摇臂。但问题是,我们如何知道哪个是最好的?我们对每个摇臂 kkk 期望奖赏的估计 Q(k)Q(k)Q(k) 只是一个近似值。
这就引出了著名的 “探索-利用窘境” (Exploration-Exploitation Dilemma):
- 利用 (Exploitation): 选择当前(根据已有经验)估算出的期望奖赏最高的摇臂。
- 好处: 立刻获得(当前看来)最好的回报。
- 风险: 如果当前的估计不准,你可能会永远错过那个真正最好的摇臂,导致最终的累积奖赏并非最大化。
- 探索 (Exploration): 选择一个当前估计并非最优的摇臂。
- 好处: 获得更多关于这个摇臂的信息,从而更新对它的奖赏估计 Q(k)Q(k)Q(k),未来有可能发现它才是“最优摇臂”。
- 风险: 浪费了一次本可以“利用”已知最优摇臂的机会,导致即时奖赏受损。
两种极端的策略:
- “仅探索” (Exploration-only) 策略: 将所有的 TTT 次尝试平均分配给 KKK 个摇臂。
- 结果: 这种策略可以很好地估计出每个摇臂的期望奖赏,但它在“探索”上花费了太多精力。它会明知某些摇臂很差,却依然要继续尝试,因此无法最大化累积奖赏。
- “仅利用” (Exploitation-only) 策略: 尝试每个摇臂一次(或几次),然后“锁定”那个当前看起来最好的摇臂,之后永远只选它。
- 结果: 如果最初的估计有偏差(几乎必然如此),这个策略很可能会“短视”地锁定在一个非最优的摇臂上,导致无法最大化累积奖赏。
结论:强化学习智能体必须在探索和利用之间达成折中 (trade-off)。
16.2.2 ϵ\epsilonϵ-贪心
ϵ\epsilonϵ-贪心法 (ϵ\epsilonϵ-greedy) 是平衡探索与利用的最简单、最常用的策略之一。
核心思想:
设置一个 [0, 1] 之间的小数 ϵ\epsilonϵ(例如 0.1)。
- 以 1−ϵ1-\epsilon1−ϵ 的概率进行利用 (Exploitation):
- 选择当前估计的平均奖赏 Q(k)Q(k)Q(k) 最高的那个摇臂 kkk(即 k=argmaxiQ(i)k = \arg\max_{i} Q(i)k=argmaxiQ(i))。
- 以 ϵ\epsilonϵ 的概率进行探索 (Exploitation):
- 在所有 KKK 个摇臂中随机选择一个。
ϵ\epsilonϵ 是什么?它如何控制这个平衡?
- ϵ\epsilonϵ (epsilon) 是 “探索率” (Exploration Rate)。
- 若 ϵ=0\epsilon = 0ϵ=0,则算法变为“仅利用” (Exploitation-only) 策略。
- 若 ϵ=1\epsilon = 1ϵ=1,则算法变为“仅探索” (Exploitation-only) 策略(纯随机选择)。
- 通常 ϵ\epsilonϵ 是一个接近 0 的小值(如 0.1 或 0.01),确保算法以 “贪心”(即利用)为主,但保留一小部分机会去探索其他可能性。
奖赏的增量计算
为了执行 ϵ\epsilonϵ-贪心法,我们需要一种方法来高效地估计每个摇臂 kkk 的平均奖赏 Q(k)Q(k)Q(k)。
如果我们直接使用
Q(k)=1n∑i=1nviQ(k) = \frac{1}{n} \sum_{i=1}^n v_iQ(k)=n1∑i=1nvi,(公式 16.1)
就需要记录摇臂 kkk 获得的所有历史奖赏 v1,…,vnv_1, \dots, v_nv1,…,vn,这在尝试次数 nnn 很大时效率低下。
因此,我们使用 增量式 (incremental) 计算:
假设摇臂 kkk 已被尝试了 n−1n-1n−1 次,平均奖赏为 Qn−1(k)Q_{n-1}(k)Qn−1(k)。当它第 nnn 次被尝试,获得了新奖赏 vnv_nvn 后,新的平均奖赏 Qn(k)Q_n(k)Qn(k) 可以更新为:
Qn(k)=1n∑i=1nvi=1n(vn+∑i=1n−1vi)=1n(vn+(n−1)×Qn−1(k)) \begin{aligned} Q_n(k) &= \frac{1}{n} \sum_{i=1}^n v_i \\ &= \frac{1}{n} \left( v_n + \sum_{i=1}^{n-1} v_i \right) \\ &= \frac{1}{n} (v_n + (n-1) \times Q_{n-1}(k)) \end{aligned} Qn(k)=n1i=1∑nvi=n1(vn+i=1∑n−1vi)=n1(vn+(n−1)×Qn−1(k))(16.2)
公式 (16.2) 的讲解:
这个公式非常高效。它告诉我们,不需要存储摇臂 kkk 过去所有的 v1,…,vnv_1, \dots, v_nv1,…,vn 奖赏值。我们只需要记住两个值:
- 旧的平均值 Qn−1(k)Q_{n-1}(k)Qn−1(k)
- 旧的计数值 n−1n-1n−1
当新的奖赏 vnv_nvn 到来时,我们用 (n−1)×Qn−1(k)(n-1) \times Q_{n-1}(k)(n−1)×Qn−1(k) 瞬时恢复出“过去的奖赏总和”,加上 vnv_nvn 得到“新的奖赏总和”,再除以“新的计数值” nnn,就得到了新的平均值 Qn(k)Q_n(k)Qn(k)。这正是教材 (原西瓜书 图 16.4 ϵ\epsilonϵ-贪心算法,对应下方笔记中 图 16.4 伪代码的第 22 行) 伪代码中第 11 行 Q(k) = (Q(k) * count(k) + v) / (count(k) + 1) 的数学原理(伪代码中的 Q(k) 和 count(k) 是 n−1n-1n−1 时的旧值)。
将公式 (16.2) 稍作变换,我们可以得到一个在强化学习中更具普遍意义的形式:
Qn(k)=1n(vn+(n−1)Qn−1(k))=1n(vn+nQn−1(k)−Qn−1(k))=Qn−1(k)+1n(vn−Qn−1(k)) \begin{aligned} Q_n(k) &= \frac{1}{n} (v_n + (n-1)Q_{n-1}(k)) \\ &= \frac{1}{n} (v_n + n Q_{n-1}(k) - Q_{n-1}(k)) \\ &= Q_{n-1}(k) + \frac{1}{n} (v_n - Q_{n-1}(k)) \end{aligned} Qn(k)=n1(vn+(n−1)Qn−1(k))=n1(vn+nQn−1(k)−Qn−1(k))=Qn−1(k)+n1(vn−Qn−1(k))(16.3)
公式 (16.3) 的直觉理解 (非常重要!):
这个公式是强化学习中许多更新规则(如 Q-Learning)的原型。我们可以把它解读为:
新估计值 = 旧估计值 + 步长 ×\times× ( 目标值 - 旧估计值 )
- 新估计值: Qn(k)Q_n(k)Qn(k)
- 旧估计值: Qn−1(k)Q_{n-1}(k)Qn−1(k)
- 步长 (Step Size): α=1n\alpha = \frac{1}{n}α=n1。它代表我们这次修正的“幅度”。
- 目标值 (Target): vnv_nvn。这是我们刚刚观测到的“真实”奖赏(尽管它也只是一个样本)。
- ( 目标值 - 旧估计值 ): vn−Qn−1(k)v_n - Q_{n-1}(k)vn−Qn−1(k)。这被称为 “误差” (Error) 或 TD-Error (时序差分误差 - Temporal Difference Error) 的雏形。它代表了我们的“估计”与“现实”之间的差距。
解读: 我们的算法在旧的估计 Qn−1(k)Q_{n-1}(k)Qn−1(k) 的基础上,朝着“误差” vn−Qn−1(k)v_n - Q_{n-1}(k)vn−Qn−1(k) 的方向,迈出了一小步(步长为 1n\frac{1}{n}n1)来进行修正,从而得到了新的、更准确的估计 Qn(k)Q_n(k)Qn(k)。
ϵ\epsilonϵ-贪心算法伪代码
结合教材图 16.4 所示,ϵ\epsilonϵ-贪心算法的流程如下:
输入: 摇臂数量 K, 奖励函数 R, 尝试次数 T, 探索率 ϵ\epsilonϵ
输出: 累积奖赏 r
1: r = 0 // 初始化累积奖赏
2: // 初始化 Q 数组 (存储每个摇臂的平均奖赏估计)
3: // 初始化 count 数组 (存储每个摇臂被尝试的次数)
4: ∀i=1,...,K:Q(i)=0,count(i)=0\forall i=1,...,K: Q(i) = 0, \text{count}(i) = 0∀i=1,...,K:Q(i)=0,count(i)=0
5: // ∀\forall∀ 读作"对于所有的", 在这里指初始化循环:
// 遍历所有 K 个摇臂,把它们的 Q 值和 count 值都设为 0
6:
7: for t = 1 to T do: // 循环 T 次
8: if rand()<ϵ\text{rand}() < \epsilonrand()<ϵ then:
9: // 探索:从 K 个摇臂中随机选一个
10: k=uniform_random_select_from(1,...,K)k = \text{uniform\_random\_select\_from}(1, ..., K)k=uniform_random_select_from(1,...,K)
11: else:
12: // 利用:选择当前 Q 值最高的摇臂
13: k=argmaxi(Q(i))k = \text{argmax}_i(Q(i))k=argmaxi(Q(i))
14: end if
15: // 执行动作 (拉下摇臂 k),观测即时奖赏 v
16: v=R(k)v = R(k)v=R(k)
17: // 更新累积奖赏
18: r=r+vr = r + vr=r+v S
19: // 更新摇臂 k 的计数值和平均奖赏估计 (使用公式 16.2)
20: Q(k)=(Q(k)×count(k)+v)/(count(k)+1)Q(k) = (Q(k) \times \text{count}(k) + v) / (\text{count}(k) + 1)Q(k)=(Q(k)×count(k)+v)/(count(k)+1)
21: count(k)=count(k)+1\text{count}(k) = \text{count}(k) + 1count(k)=count(k)+1
22:
23: end for
伪代码讲解 (图 16.4):
- 输入/输出: 算法需要知道有几个摇臂 KKK、总共能试多少次 TTT、探索率 ϵ\epsilonϵ 以及一个奖励函数 RRR。它的目标是返回最终的累积奖赏 rrr。
- 关于奖励函数 RRR 的澄清:RRR 不是 ϵ\epsilonϵ-贪心算法本身。RRR 代表的是环境(Environment),或者说问题本身(例如那 KKK 台老虎机)。
- ϵ\epsilonϵ-贪心算法是决策者(Agent/Policy),它决定“下一步拉哪根摇臂”。
- 当算法(在第16行)执行
v = R(k)时,它是在与环境 RRR 交互:算法选择动作 kkk(拉第 kkk 根摇臂),环境 RRR 根据其内部机制(这个机制对算法是未知的)返回一个即时奖赏 vvv。 - 因此,RRR 是算法的输入(算法需要调用它来获取奖赏),而不是算法本身。
- 初始化 (Lines 1-4): 我们需要“记账本”。
r是总奖赏。Q数组是我们的“大脑”,记录对每个摇臂的“价值估计”,初始都为0。count数组记录每个摇臂被拉了多少次,初始也为0。 - 主循环 (Line 6): 重复 TTT 次“选择-行动-更新”的循环。
- 探索/利用决策 (Lines 7-13): 这是 ϵ\epsilonϵ-贪心的核心。
if rand() < ε: 产生一个 0 到 1 的随机数。如果它小于 ϵ\epsilonϵ(比如 ϵ=0.1\epsilon=0.1ϵ=0.1 时,有 10% 的概率发生),则执行“探索”:在 KKK 个摇臂中随便选一个。else: 在 1−ϵ1-\epsilon1−ϵ 的概率下(比如 90% 的概率),执行“利用”:在Q数组中找到当前值最大的那个摇臂 kkk。
- 行动与更新 (Lines 16-23):
v = R(k): 拉下选定的摇臂 kkk,环境返回一个奖赏 vvv。r = r + v: 更新总奖赏。Q(k) = ...和count(k) = ...: 这是最关键的学习步骤。我们只更新被选中的那个摇臂 kkk 的记账本。使用公式 (16.2) 的逻辑来更新它的平均奖赏 Q(k)Q(k)Q(k),并将其尝试次数count(k)加 1。
ϵ\epsilonϵ 应该如何设置?是固定的吗?
ϵ\epsilonϵ 是一个超参数,它的设置对算法性能影响很大。
- 固定 ϵ\epsilonϵ:
- 如果奖赏的不确定性很大(即概率分布方差很大),则需要较大的 ϵ\epsilonϵ 来进行更多的探索。
- 如果奖赏比较确定(方差很小),则较小的 ϵ\epsilonϵ 就足够了。
- 衰减 ϵ\epsilonϵ (Decaying ϵ\epsilonϵ):
- 一个更优的策略是让 ϵ\epsilonϵ 随着尝试次数 ttt 的增加而逐渐减小,例如 ϵt=1/t\epsilon_t = 1 / \sqrt{t}ϵt=1/t。
- 直觉: 在初期(ttt 很小),我们对摇臂一无所知,此时 ϵ\epsilonϵ 较大,算法倾向于探索。随着后期(ttt 很大)经验的积累,我们的估计 Q(k)Q(k)Q(k) 越来越准,此时 ϵ\epsilonϵ 变小,算法倾向于利用已知的最优摇臂。这完美地平衡了探索和利用。
16.2.3 Softmax
ϵ\epsilonϵ-贪心法在“探索”时,是以均等概率从所有 KKK 个摇臂中随机选择一个。这在某些情况下可能不是最优的,因为它对待一个“估计很差”的摇臂和一个“估计只比当前最优差一点点”的摇臂是完全相同的。
Softmax 算法 提供了另一种更“智能”的思路来平衡探索和利用。它的核心思想是:不再以 ϵ\epsilonϵ 的概率进行完全随机的探索,而是根据当前对各个摇臂的奖赏估计值 Q(k)Q(k)Q(k) 来分配探索的概率。
Q(k)Q(k)Q(k) 越高的摇臂,被选中的概率也越高;反之,Q(k)Q(k)Q(k) 越低的摇臂,被选中的概率也越低,但仍然有被选中的可能。
这种概率分配是基于 玻尔兹曼分布 (Boltzmann distribution):
P(k)=eQ(k)τ∑i=1KeQ(i)τ P(k) = \frac{e^{\frac{Q(k)}{\tau}}}{\sum_{i=1}^K e^{\frac{Q(i)}{\tau}}} P(k)=∑i=1KeτQ(i)eτQ(k) (16.4)
公式 (16.4) 的直觉理解:
- Q(k)Q(k)Q(k): 摇臂 kkk 的当前平均奖赏估计。
- eQ(k)e^{Q(k)}eQ(k) (指数函数): 这是一个关键。指数函数 exe^xex 能将估计值 Q(k)Q(k)Q(k) 映射为正数,并且能放大估计值之间的差异。例如,Q=2Q=2Q=2 的臂会比 Q=1Q=1Q=1 的臂获得 eee 倍(约 2.718 倍)的“权重”,而不仅仅是 2 倍。
- ∑i=1KeQ(i)/τ\sum_{i=1}^K e^{Q(i)/\tau}∑i=1KeQ(i)/τ (分母): 这是归一化项。它把所有 KKK 个摇臂的“权重”全部加起来,用以确保所有摇臂的 P(k)P(k)P(k) 概率之和为 1。
- τ\tauτ (温度参数): 这是 Softmax 算法的核心超参数,被称为 “温度” (Temperature),它控制着探索与利用的平衡。
“温度”参数 τ\tauτ 是如何控制探索-利用平衡的?
τ\tauτ (tau) 是一个大于 0 的正数。
-
当 τ→∞\tau \to \inftyτ→∞ (高温):
- 数学上: τ\tauτ 非常大,导致所有的 Q(k)/τQ(k)/\tauQ(k)/τ 都趋近于 0。
- 结果: 所有的 eQ(k)/τe^{Q(k)/\tau}eQ(k)/τ 都趋近于 e0=1e^0 = 1e0=1。
- 公式变为: P(k)≈1∑i=1K1=1KP(k) \approx \frac{1}{\sum_{i=1}^K 1} = \frac{1}{K}P(k)≈∑i=1K11=K1。
- 结论: 算法退化为 “仅探索” (Exploration-only) 策略,即在所有摇臂中均匀随机选择(和 ϵ=1\epsilon=1ϵ=1 的 ϵ\epsilonϵ-贪心法一样)。
-
当 τ→0\tau \to 0τ→0 (低温 / 冰点):
- 数学上: τ\tauτ 非常小,我们假设 Q(k∗)Q(k^*)Q(k∗) 是所有 QQQ 值中最大的那个。此时,Q(k∗)/τQ(k^*)/\tauQ(k∗)/τ 会是一个巨大的正数,而其他 Q(j)/τQ(j)/\tauQ(j)/τ (其中 j≠k∗j \neq k^*j=k∗) 相比之下会是小得多(甚至是巨大的负数)。
- 结果: eQ(k∗)/τe^{Q(k^*)/\tau}eQ(k∗)/τ 将会远远大于所有其他的 eQ(j)/τe^{Q(j)/\tau}eQ(j)/τ。
- 公式变为: 分母 ∑eQ(i)/τ\sum e^{Q(i)/\tau}∑eQ(i)/τ 几乎完全被 eQ(k∗)/τe^{Q(k^*)/\tau}eQ(k∗)/τ 主导。
- 对于最优臂 k∗k^*k∗: P(k∗)≈eQ(k∗)/τeQ(k∗)/τ→1P(k^*) \approx \frac{e^{Q(k^*)/\tau}}{e^{Q(k^*)/\tau}} \to 1P(k∗)≈eQ(k∗)/τeQ(k∗)/τ→1。
- 对于其他臂 jjj: P(j)≈eQ(j)/τeQ(k∗)/τ→0P(j) \approx \frac{e^{Q(j)/\tau}}{e^{Q(k^*)/\tau}} \to 0P(j)≈eQ(k∗)/τeQ(j)/τ→0。
- 结论: 算法退化为 “仅利用” (Exploitation-only) 策略,即 100% 确定地选择当前估计值最高的那个摇臂(和 ϵ=0\epsilon=0ϵ=0 的 ϵ\epsilonϵ-贪心法一样)。
-
合适的 τ\tauτ: 当 τ\tauτ 取一个中间值时(如 τ=0.1\tau=0.1τ=0.1),算法会表现出“Softmax”的特性:QQQ 值高的臂有很大概率被选中,QQQ 值低的臂也有小概率被“探索”。
-
衰减 τ\tauτ: 类似于 ϵ\epsilonϵ 衰减,τ\tauτ 也可以设计为随时间 ttt 逐渐衰减。初期 τ\tauτ 较大(高温),鼓励探索;后期 τ\tauτ 变小(降温),鼓励利用。
伪代码讲解 (图 16.5)
Softmax 算法的伪代码(教材图 16.5)在结构上与 ϵ\epsilonϵ-贪心法(图 16.4)几乎完全相同。
输入: 摇臂数量 K, 奖励函数 R, 尝试次数 T, 温度参数 τ\tauτ
输出: 累积奖赏 r
1: r = 0
2: ∀i=1,...,K:Q(i)=0,count(i)=0\forall i=1,...,K: Q(i) = 0, \text{count}(i) = 0∀i=1,...,K:Q(i)=0,count(i)=0
3: for t = 1 to T do: // 循环 T 次
4: // 核心区别:
5: // 1. 根据当前 Q(1)…Q(K) 和 τ\tauτ, 使用式 (16.4) 计算 K 个概率
6: // P(1)…P(K)
7: // 2. 按照这个概率分布 P, 随机抽样选择一个摇臂 k
8: k=select_from({1...K}) using Pk = \text{select\_from}(\{1...K\}) \text{ using } Pk=select_from({1...K}) using P
9:
10: v=R(k)v = R(k)v=R(k) // 执行动作, 观测奖赏
11: r=r+vr = r + vr=r+v // 更新累积奖赏
12: // 后续更新步骤与 ϵ\epsilonϵ-贪心法完全相同
13: Q(k)=(Q(k)×count(k)+v)/(count(k)+1)Q(k) = (Q(k) \times \text{count}(k) + v) / (\text{count}(k) + 1)Q(k)=(Q(k)×count(k)+v)/(count(k)+1)
14: count(k)=count(k)+1\text{count}(k) = \text{count}(k) + 1count(k)=count(k)+1
15: end for
对比 ϵ\epsilonϵ-贪心法:
- 相同点: 初始化 (Lines 1-2)、与环境交互 (
v = R(k))、更新累积奖赏 (r = r + v)、更新平均值和计数值 (Lines 13-14) 的逻辑是完全一致的。 - 唯一区别: 仅在于动作选择的策略(Lines 5-8)。
- ϵ\epsilonϵ-贪心法使用一个
if/else模块:(1-ϵ\epsilonϵ) 的概率“贪心”选择 argmaxQ(k)\arg\max Q(k)argmaxQ(k),ϵ\epsilonϵ 的概率“均匀”探索。 - Softmax 算法则是一个统一的概率框架:它总是在进行“加权探索”,只不过这个“权重”由 τ\tauτ 控制,当 τ→0\tau \to 0τ→0 时,这个“加权探索”就退化为了“贪心利用”。
- ϵ\epsilonϵ-贪心法使用一个
Softmax 和 ϵ\epsilonϵ-贪心法,哪个更好?
这个问题没有绝对的答案,取决于具体的应用(教材 图 16.6)。
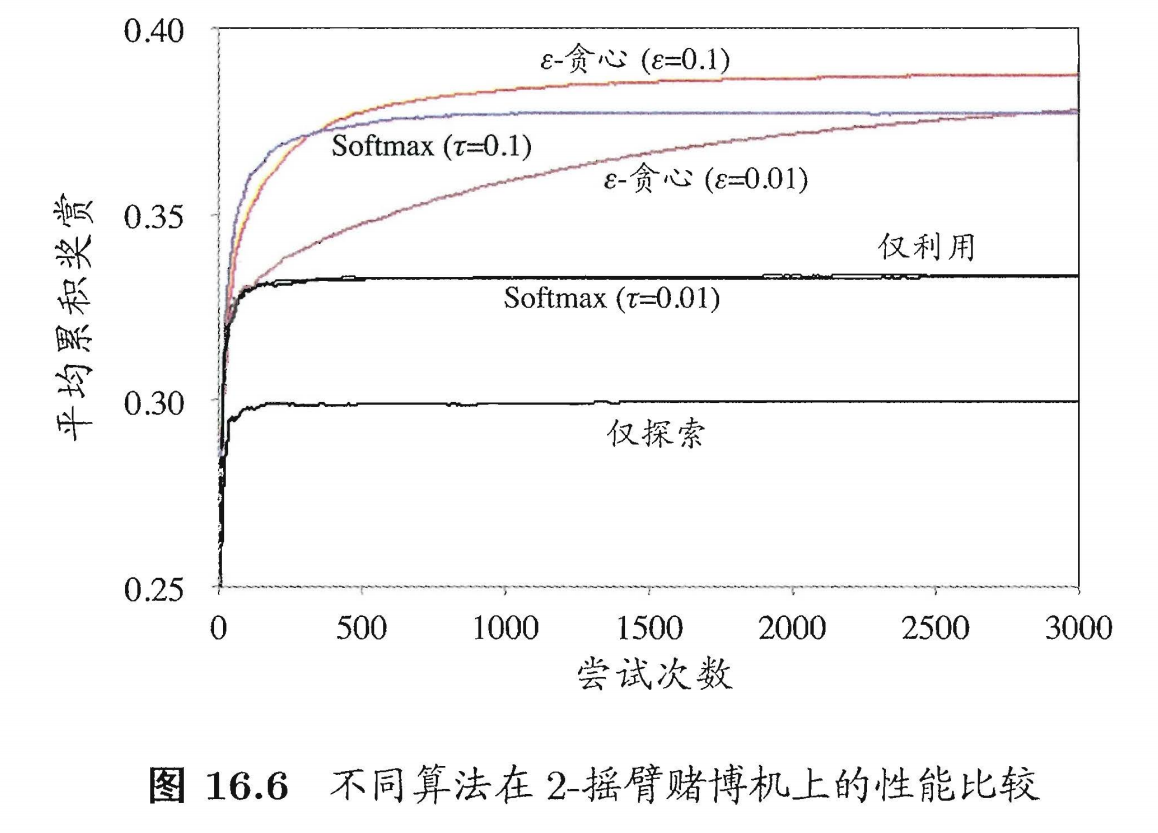

教材(图 16.6)中展示了一个 2-臂老虎机实验:
- 臂 1: P(r=1)=0.4,P(r=0)=0.6P(r=1)=0.4, P(r=0)=0.6P(r=1)=0.4,P(r=0)=0.6 (期望奖赏 0.4)
- 臂 2: P(r=1)=0.2,P(r=0)=0.8P(r=1)=0.2, P(r=0)=0.8P(r=1)=0.2,P(r=0)=0.8 (期望奖赏 0.2)
实验结果 (图 16.6):
- “仅探索” (纯随机) 表现最差,平均奖赏收敛到 (0.4+0.2)/2=0.3(0.4+0.2)/2 = 0.3(0.4+0.2)/2=0.3。
- “仅利用” 表现次差,它很可能在早期因为随机性而锁定了较差的臂 2。
- ϵ\epsilonϵ-贪心 (ϵ=0.01\epsilon=0.01ϵ=0.01) 因为探索率太低,收敛较慢。
- ϵ\epsilonϵ-贪心 (ϵ=0.1\epsilon=0.1ϵ=0.1) 和 Softmax (τ=0.1\tau=0.1τ=0.1) 在这个特定问题上表现最好,且性能非常接近,都快速收敛到了接近最优臂 1 的期望奖赏(约 0.38-0.39)。
结论:
- ϵ\epsilonϵ-贪心法:实现简单,计算开销极小。
- Softmax 算法:实现略复杂,每一步都需要计算 KKK 个指数和一次归一化,计算开销稍大。但它的探索策略更“合理”(即更倾向于探索“看起来不错”的臂)。
在很多任务中,两者在调好参数(ϵ\epsilonϵ 或 τ\tauτ)后性能相近。
16.3 有模型学习
(这部分笔记内容待补充…)
(现在的16.3笔记直接跳过了教材,仅为后续学习 Flow Q-Learning 使用)
在 16.1 中,我们定义了马尔可夫决策过程 (MDP) E=(X,A,P,R)E = (X, A, P, R)E=(X,A,P,R)。其中 PPP(状态转移函数)和 RRR(奖赏函数)共同构成了环境模型。
有模型学习 (Model-Based Learning) 的核心前提是:我们已知 这个环境模型 PPP 和 RRR。
这就像我们在玩一个游戏(比如西瓜种植,图 16.2),我们不仅能玩,手上还拿着一本完整的游戏规则说明书(即 PPP 和 RRR)。这本说明书精确地告诉了我们:
- 在任何状态 xxx 下,执行任何动作 aaa,会以什么概率 P(x′∣x,a)P(x'|x,a)P(x′∣x,a) 转移到下一个状态 x′x'x′。
- 在发生这次转移后,我们会得到多少即时奖赏 R(x,a,x′)R(x,a,x')R(x,a,x′)。
有模型学习的目标是什么?
既然我们已经知道了全部规则,我们就不再需要“试错” (Trial-and-Error) 了。
我们的任务从“学习” (Learning) 转化为了 “规划” (Planning)。
想象一下,你站在一个迷宫的起点,手上拿着完整的迷宫地图(模型)。你不需要真的去“探索”每一条死路,你可以在起点就利用这张地图,“规划”出一条通往终点的最优路径。
因此,有模型学习的目标是:利用已知的 PPP 和 RRR,通过计算,直接找出那个能最大化累积奖赏的最优策略 π∗\pi^*π∗。
16.3.1 核心工具:价值函数与贝尔曼方程
为了“规划”,我们需要一个工具来衡量“一个状态有多好”或“一个动作有多好”。这就是价值函数。
💡 教材定义
在模型已知时, 对任意策略 π\piπ 能估计出该策略带来的期望累积奖赏。
- 函数 Vπ(x)V^\pi(x)Vπ(x) 表示从状态 xxx 出发, 使用策略 π\piπ 所带来的累积奖赏;
- 函数 Qπ(x,a)Q^\pi(x, a)Qπ(x,a) 表示从状态 xxx 出发, 执行动作 aaa 后再使用策略 π\piπ 带来的累积奖赏。
这里的 V(⋅)V(\cdot)V(⋅) 称为 “状态价值函数” (state value function), Q(⋅)Q(\cdot)Q(⋅) 称为 “状态-动作价值函数” (state-action value function), 分别表示指定“状态”上以及指定“状态-动作”上的累积奖赏。
笔记解读:
-
状态价值函数 (State-Value Function) Vπ(x)V^\pi(x)Vπ(x):
- 含义:从状态 xxx 出发,后续一直 采用策略 π\piπ,能获得的 γ\gammaγ-折扣累积奖赏的期望值。
- Vπ(x)V^\pi(x)Vπ(x) 衡量的是“状态 xxx 本身有多好”(在策略 π\piπ 的指导下)。
-
状态-动作价值函数 (State-Action-Value Function) Qπ(x,a)Q^\pi(x, a)Qπ(x,a):
- 含义:在状态 xxx 时,先执行动作 aaa,然后后续再 采用策略 π\piπ,能获得的 γ\gammaγ-折扣累积奖赏的期望值。
- Qπ(x,a)Q^\pi(x, a)Qπ(x,a) 衡量的是“在状态 xxx 下执行动作 aaa 有多好”(在策略 π\piπ 的指导下)。
Q-Function 就是我们要找的 Q-Learning 里的 Q 吗?
是的! 这就是 Q-Learning 中“Q”的来源。Qπ(x,a)Q^\pi(x, a)Qπ(x,a) 是后续所有免模型学习(包括 FQL)的核心概念。FQL 中的 “Critic” 网络,其目标就是估计这个 QQQ 函数。
贝尔曼方程 (Bellman Equation)
有了 PPP 和 RRR,我们就可以推导出价值函数必须满足的一个关键性质,即贝尔曼方程。这个方程是整个强化学习的基石。
它将一个状态的价值 Vπ(x)V^\pi(x)Vπ(x) 与其后续状态的价值 Vπ(x′)V^\pi(x')Vπ(x′) 建立起了递归联系:
Vπ(x)=∑a∈Aπ(a∣x)∑x′∈XP(x′∣x,a)(R(x,a,x′)+γVπ(x′)) V^\pi(x) = \sum_{a \in A} \pi(a|x) \sum_{x' \in X} P(x'|x,a) \left( R(x,a,x') + \gamma V^\pi(x') \right) Vπ(x)=a∈A∑π(a∣x)x′∈X∑P(x′∣x,a)(R(x,a,x′)+γVπ(x′)) (16.5)
公式 (16.5) 的直觉理解 (非常重要!):
这个公式看起来很吓人,但它只是在做“加权平均”:
“当前状态 xxx 的价值” = “所有可能的下一步的期望价值”
我们把它拆开看:
R(x,a,x') + γV^π(x'): 这是你“单步”的总回报。你先执行 aaa 转移到 x′x'x′,立即获得奖赏 RRR,然后从 x′x'x′ 开始继续执行策略 π\piπ,获得未来的折扣价值 γVπ(x′)\gamma V^\pi(x')γVπ(x′)。∑_{x' ∈ X} P(x'|x,a) [ ... ]: 这是在求“动作 aaa”的期望价值。因为从 (x,a)(x, a)(x,a) 出发,环境是随机的(图 16.2),你可能转移到 x1′x'_1x1′,也可能转移到 x2′x'_2x2′。所以你需要用转移概率 PPP 来加权平均,算出执行动作 aaa 后所有可能结果的期望回报。这个结果就是 Qπ(x,a)Q^\pi(x, a)Qπ(x,a)!∑_{a ∈ A} π(a|x) [ ... ]: 这是在求“状态 xxx”的期望价值。因为在状态 xxx,你的策略 π\piπ 本身也可能是随机的,你可能选择 a1a_1a1,也可能选择 a2a_2a2。所以你必须再用策略概率 π\piπ 来加权平均,算出在状态 xxx 下所有可能动作的期望回报。
因此,(16.5) 也可以拆解为两个更简洁的公式:
Vπ(x)=∑a∈Aπ(a∣x)Qπ(x,a) V^\pi(x) = \sum_{a \in A} \pi(a|x) Q^\pi(x, a) Vπ(x)=a∈A∑π(a∣x)Qπ(x,a) (16.6)
Qπ(x,a)=∑x′∈XP(x′∣x,a)(R(x,a,x′)+γVπ(x′)) Q^\pi(x, a) = \sum_{x' \in X} P(x'|x,a) \left( R(x,a,x') + \gamma V^\pi(x') \right) Qπ(x,a)=x′∈X∑P(x′∣x,a)(R(x,a,x′)+γVπ(x′)) (16.7)
我们的最终目标是找到最优价值函数 V∗(x)V^*(x)V∗(x) 和 Q∗(x,a)Q^*(x, a)Q∗(x,a),它们对应了最优策略 π∗\pi^*π∗。最优策略一定是贪心的,它会选择能带来最高 Q∗Q^*Q∗ 值的动作。因此,贝尔曼方程可以被写成贝尔曼最优方程 (Bellman Optimality Equation):
Q∗(x,a)=∑x′∈XP(x′∣x,a)(R(x,a,x′)+γmaxa′Q∗(x′,a′)) Q^*(x, a) = \sum_{x' \in X} P(x'|x,a) \left( R(x,a,x') + \gamma \max_{a'} Q^*(x', a') \right) Q∗(x,a)=x′∈X∑P(x′∣x,a)(R(x,a,x′)+γa′maxQ∗(x′,a′)) (16.8)
这是 16.4 Q-Learning 算法的理论基石。
16.3.2 如何求解?(策略迭代与值迭代)
💡 核心思想:有模型学习 = 动态规划 (无泛化)
“在模型已知时,强化学习任务能归结为基于动态规划的寻优问题。与监督学习不同,这里并未涉及到泛化能力,而是为每一个状态找到最好的动作。”
这句话是理解“有模型学习”的关键,我们来拆解一下:
-
“…归结为基于动态规划 (Dynamic Programming, DP) 的寻优问题”
-
什么是动态规划? 动态规划的核心思想是将一个大问题分解为一堆相关的“子问题”,通过求解所有子问题,最终得到大问题的解。
-
它和强化学习 (RL) 有什么关系?
-
我们在
16.3.1中推导出的贝尔曼方程 (Bellman Equation) 就是一个完美的 DP 结构! -
大问题:求解状态 xxx 的最优价值 V∗(x)V^*(x)V∗(x)。
-
子问题:求解 xxx 的所有“下一步”状态 x′x'x′ 的最优价值 V∗(x′)V^*(x')V∗(x′)。
-
贝尔曼方程 V(x)=⋯∑P(…(R+γV(x′)))V(x) = \dots \sum P(\dots (R + \gamma V(x')))V(x)=⋯∑P(…(R+γV(x′))) 告诉我们,一个状态的价值可以由其后续状态的价值来递归定义。
-
因此,我们接下来要讲的 “策略迭代” 和 “值迭代”,它们本质上就是两种经典的动态规划算法,用来迭代求解这个递归的贝尔曼方程。
-
-
“…与监督学习不同,这里并未涉及到泛化能力…”
-
这是有模型 DP 算法与神经网络(如 DQN)最根本的区别。
-
监督学习(例如图像分类):你用 6 万张手写数字图片(训练集)去训练一个神经网络。你的目标是让这个网络在 1 万张它从未见过的图片(测试集)上也能表现良好。这就是 “泛化” (Generalization)。
-
有模型 DP 算法(例如值迭代):想象一个 4x4 的格子世界 (Grid World),总共有 16 个状态。我们的算法会计算并存储一个 4x4 的表格 (Table),精确地记录每一个格子的价值(比如 V(1,1)=0.8,V(1,2)=0.9,…V(1,1)=0.8, V(1,2)=0.9, \dotsV(1,1)=0.8,V(1,2)=0.9,…)。
-
这个算法没有“泛化”可言。它不知道 V(1,1)V(1,1)V(1,1) 和 V(1,2)V(1,2)V(1,2) 在“概念上”是邻居。它只是为 16 个离散的状态,计算出了 16 个精确的数值。如果你把世界改成 5x5,这个 4x4 的表格就完全没用了,必须从头重算。
-
-
“…而是为每一个状态找到最好的动作。”
-
这承接了上一点。因为我们为每一个状态 xxx 都计算出了精确的 V∗(x)V^*(x)V∗(x) 或 Q∗(x,a)Q^*(x,a)Q∗(x,a),所以我们的最优策略 π∗\pi^*π∗ 也是一个**“查找表” (Lookup Table)**。
-
例如,在 4x4 格子世界中,最终的策略 π∗\pi^*π∗ 会是这样一个表格:
-
在状态 (1,1)(1,1)(1,1),执行 →\rightarrow→
-
在状态 (1,2)(1,2)(1,2),执行 →\rightarrow→
-
在状态 (1,3)(1,3)(1,3),执行 ↑\uparrow↑
-
…
-
我们为每一个状态都找到了一个确定的“最优解”。这是一种 “规划” (Planning),而不是像监督学习那样的“泛化” (Generalization)。
-
有了模型 P,RP, RP,R 和贝尔曼方程,求解最优策略 π∗\pi^*π∗ 就变成了纯粹的计算问题。主要有两种算法:
-
策略迭代 (Policy Iteration):
- 思路:像“演员”和“评论家”一样交替工作。
- 步骤:
- 策略评估 (Policy Evaluation):固定当前策略 πk\pi_kπk。利用已知的 P,RP, RP,R 和公式 (16.5),解一个N元一次方程组(N是状态总数),计算出当前策略下所有状态的真实价值 Vπk(x)V^{\pi_k}(x)Vπk(x)。
- 策略改进 (Policy Improvement):根据 Vπk(x)V^{\pi_k}(x)Vπk(x),更新策略。对于每个状态 xxx,都贪心地选择那个能导向最高未来价值的动作 aaa,形成新策略 πk+1\pi_{k+1}πk+1。
- 循环: 重复 1 和 2,直到策略 π\piπ 不再变化,此时的 π\piπ 就是最优策略 π∗\pi^*π∗。
-
值迭代 (Value Iteration):
- 思路:更直接,不关心中间的策略,只专注于迭代计算出最优价值 V∗(x)V^*(x)V∗(x)。
- 步骤:
- 初始化一个随意的 V0(x)V_0(x)V0(x)(比如全为0)。
- 迭代更新: 不断地用贝尔曼最优方程 (16.8) 的逻辑作为更新规则,迭代 kkk 次:
Vk+1(x)←maxa∑x′∈XP(x′∣x,a)(R(x,a,x′)+γVk(x′)) V_{k+1}(x) \leftarrow \max_{a} \sum_{x' \in X} P(x'|x,a) \left( R(x,a,x') + \gamma V_k(x') \right) Vk+1(x)←amaxx′∈X∑P(x′∣x,a)(R(x,a,x′)+γVk(x′)) (16.9) - 循环: 重复步骤 2,直到 Vk(x)V_k(x)Vk(x) 收敛不再变化。此时的 VkV_kVk 就是 V∗V^*V∗。
- 提取策略: 一旦有了 V∗V^*V∗,最优策略 π∗\pi^*π∗ 也就随之确定了:在任何状态 xxx,选择那个能最大化 (16.9) 右侧的动作 aaa 即可。
小结
-
有模型学习的本质是:利用已知的模型 (PPP 和 RRR),通过动态规划(如值迭代),为所有已知的、离散的状态 xxx 计算出一个精确的最优价值 V∗(x)V^*(x)V∗(x),并导出一个“查找表”式的最优策略 π∗\pi^*π∗。
-
这为我们引出了
16.3.3的“诅咒”: 如果状态空间 XXX 不是 4x4 这种小表格,而是像自动驾驶的“图像”那样连续且无限的,这种“为每一个状态计算”的 DP 方法就彻底失效了。这也正是16.5 值函数近似(用神经网络来近似 V(x)V(x)V(x)) 必须被提出的原因。
16.3.3 “模型的诅咒”:为什么有模型学习不够用?
读到这里,你可能会想:既然有模型学习可以通过“规划”直接算出最优解,为什么我们还要费劲去学“免模型”呢?
这就是 “模型的诅咒” (Curse of the Model),也是我们必须转向 16.4 的核心原因。有模型学习在现实中几乎不可行,因为它依赖两个致命的假设:
-
假设一:我们已知 PPP 和 RRR。
- 现实是:我们几乎永远不知道完美的环境模型。我们无法写出一个函数 PPP,来精确计算“在自动驾驶时,方向盘左转5度,下一帧图像是 x′x'x′ 的概率”。
- 对策?:我们可以尝试去“学习”模型 PPP 和 RRR。但这本身就是一个极其困难的监督学习问题,甚至比直接学习策略更难。
-
假设二:我们的状态空间 XXX 是有限且足够小的。
- 现实是:策略迭代和值迭代都要求我们能遍历 (iterate) 状态空间中的每一个状态 xxx。
- 诅咒:在现实任务中,状态空间 XXX 往往是天文数字。
- 围棋的状态空间 ≈10170\approx 10^{170}≈10170。
- 自动驾驶的状态 xxx 是一张摄像头图像,状态空间 XXX 是所有可能的图像,这是一个连续且无限的空间。
- 当状态空间巨大或连续时,你根本无法执行 V(x)←…V(x) \leftarrow \dotsV(x)←… 这样的更新,因为你连存储所有 V(x)V(x)V(x) 的表格都做不到。
这为我们后续的学习铺平了道路:
-
## 16.4 免模型学习(如 Q-Learning) 就是为了解决假设一。它提出了一种天才般的思路:我们能不能不依赖 PPP 和 RRR,仅仅通过“试错”收集的样本(x, a, r, x'),就直接估计出最优的 Q∗(x,a)Q^*(x, a)Q∗(x,a)? -
## 16.5 值函数近似就是为了解决假设二。它提出:既然我们存不下 Q(x,a)Q(x, a)Q(x,a) 这张大表,我们能不能用一个神经网络 Qθ(x,a)Q_\theta(x, a)Qθ(x,a) 来近似它?- 这正是你
Flow Q-Learning 学习路线.md中提到的 Critic (评论家) / 价值网络 (Q网络)。 - 这也正是你的 FQL 论文中,Actor-Critic 框架里的那个 Critic。
- 这正是你
现在,我们已经初步准备好进入 16.4,去探究 Q-Learning 是如何巧妙地绕过“模型”这个大山的。
16.4 免模型学习
在 16.3.3 中,我们讨论了“模型的诅咒” (Curse of the Model),指出了“有模型学习” (Model-Based Learning) 的两个致命假设:
- 我们必须已知完美的环境模型 PPP (状态转移函数) 和 RRR (奖赏函数)。
- 状态空间 XXX 必须是有限且足够小的,以便我们能用动态规划 (DP) 遍历所有状态。
在绝大多数现实任务中,这两个假设都不成立。我们几乎永远无法获知环境的精确模型 PPP 和 RRR。
因此,我们必须转向 “免模型学习” (Model-Free Learning)。
💡 免模型学习的核心思想
免模型学习算法不依赖环境模型 PPP 和 RRR。
它放弃了“规划” (Planning),回归到“试错式学习” (Trial-and-Error)。智能体必须在未知的环境中亲自执行动作,通过采样和观察实际发生的经验——即
(状态, 动作, 奖赏, 下一状态)四元组——来直接估计价值函数和优化策略。这也使得免模型学习比有模型学习要困难得多。
16.4.1 蒙特卡洛强化学习
蒙特卡洛 (Monte Carlo, MC) 方法 是我们接触的第一种,也是最直观的免模型学习方法。
💡 什么是蒙特卡洛方法?
蒙特卡洛方法的核心思想是 “采样” (Sampling)。当我们无法计算一个量的精确期望值时(例如因为我们不知道 PPP 和 RRR),我们可以通过大量随机试验,用试验结果的平均值来近似这个期望值。
这就好像我们在
16.2K-臂老虎机中所做的那样:我们不知道摇臂 kkk 的期望奖赏 Q(k)Q(k)Q(k),但我们可以通过多次拉动它,用观测到的所有奖赏的平均值来估计它。
在强化学习中,我们要估计的是价值函数(即累积奖赏的期望值)。
MC 方法如何估计价值函数?
很简单:让智能体在环境中完整地运行 NNN 次(NNN 很大)。每一次从开始到结束称为一条 “轨迹” (Trajectory) 或 “幕” (Episode)。
<x0,a0,r1,x1,a1,r2,…,xT> <x_0, a_0, r_1, x_1, a_1, r_2, \dots, x_T> <x0,a0,r1,x1,a1,r2,…,xT>
对于轨迹中出现的每一个状态 xxx(或状态-动作对 (x,a)(x, a)(x,a)),我们都计算出它在这条轨迹中获得的 “实际”累积奖赏(即“回报”,Return)。然后,我们将 NNN 次试验中观测到的所有“回报”进行平均,以此作为价值函数的估计值。
免模型学习的困境:V 还是 Q?
在 16.3 有模型学习中,我们既可以学习状态价值函数 V(x)V(x)V(x),也可以学习状态-动作价值函数 Q(x,a)Q(x, a)Q(x,a)。
但在免模型设定下,只学习 V(x)V(x)V(x) 是不够的。
-
为什么? 回想一下,如果我们只有 V(x)V(x)V(x),我们要如何改进策略?我们需要“贪心”地选择动作,即:
π(x)=argmaxa∑x′∈XP(x′∣x,a)(R(x,a,x′)+γV(x′)) \pi(x) = \arg\max_{a} \sum_{x' \in X} P(x'|x,a) \left( R(x,a,x') + \gamma V(x') \right) π(x)=argamaxx′∈X∑P(x′∣x,a)(R(x,a,x′)+γV(x′))
问题:要执行这个 argmax\arg\maxargmax,我们必须知道 PPP 和 RRR。但在免模型学习中, PPP 和 RRR 是未知的!我们无法“向前看” (lookahead) 来判断哪个动作 aaa 会导向最好的 V(x′)V(x')V(x′)。 -
解决方案:我们必须直接估计 Q(x,a)Q(x, a)Q(x,a)。
- Q(x,a)Q(x, a)Q(x,a) 函数的定义是“在状态 xxx 执行动作 aaa,后续遵循策略 π\piπ 的期望累积奖赏”。
- 它已经把动作 aaa 的即时后果(即 PPP 和 RRR 的作用)“内化” (internalize) 到了 QQQ 值本身。
- 一旦我们有了 Q(x,a)Q(x, a)Q(x,a) 的估计,改进策略就变得非常简单,不再需要 PPP 和 RRR:
π(x)=argmaxaQ(x,a) \pi(x) = \arg\max_{a} Q(x, a) π(x)=argamaxQ(x,a)
因此,免模型学习的核心目标就是估计 Q(x,a)Q(x, a)Q(x,a)。MC 方法就是通过平均多条轨迹的实际回报来估计 Q(x,a)Q(x, a)Q(x,a)。
探索-利用窘境 (再访)
这里出现了和 K-臂老虎机完全一样的问题:如果我们总是“利用” (Exploitation) 当前最好的 Q(x,a)Q(x, a)Q(x,a),我们可能会错过那个真正 最优的动作,因为我们从未“探索” (Explore) 过它。
例如,在状态 xxx,我们尝试了动作 a1a_1a1 并发现 Q(x,a1)=10Q(x, a_1)=10Q(x,a1)=10。如果我们从此“仅利用”,我们就永远不会去尝试 a2a_2a2,也就永远不会发现 Q(x,a2)Q(x, a_2)Q(x,a2) 可能是 100。
解决方案:和 16.2.2 K-臂老虎机一样,我们必须在策略中引入探索。最简单的方法就是 ϵ\epsilonϵ-贪心法 (ϵ\epsilonϵ-greedy)。
- 以 1−ϵ1-\epsilon1−ϵ 的概率进行利用:选择 argmaxaQ(x,a)\arg\max_a Q(x, a)argmaxaQ(x,a)。
- 以 ϵ\epsilonϵ 的概率进行探索:从所有动作中随机选择一个。
这引出了我们的第一个完整算法:同策略蒙特卡洛学习。
同策略蒙特卡洛学习 (On-Policy MC)
“同策略” (On-Policy) 是一个非常关键的术语。
💡 什么是“同策略” (On-Policy)?
它的含义是:我们用来“生成轨迹数据”的策略,与我们正在“评估和改进”的策略,是同一个策略。
在这个算法 (图 16.10) 中:
- 我们维护一个 ϵ\epsilonϵ-贪心策略 π\piπ。
- 我们用这个 π\piπ 去和环境交互,生成轨迹 (line 5)。
- 我们用生成的轨迹来更新 π\piπ 自己的 QQQ 值 (line 17-18)。
- 我们用更新后的 QQQ 值来改进 π\piπ (line 22)。
从始至终,都只有这一个 ϵ\epsilonϵ-贪心策略 π\piπ 在自我迭代和更新。
教材 图 16.10 给出了同策略 MC 算法的伪代码,它完美地结合了 K-臂老虎机中的“增量式平均”和 ϵ\epsilonϵ-贪心策略。
1: Q(x,a)=0,count(x,a)=0,∀x∈X,a∈AQ(x, a) = 0, \text{count}(x, a) = 0, \forall x \in X, a \in AQ(x,a)=0,count(x,a)=0,∀x∈X,a∈A
2: π(x,a)=1/∣A(x)∣,∀x∈X,a∈A\pi(x, a) = 1 / |A(x)|, \forall x \in X, a \in Aπ(x,a)=1/∣A(x)∣,∀x∈X,a∈A // 初始化为均匀随机策略
3: for s = 1, 2, … do: // 循环每一“幕” (episode)
4: // 3a. 【生成轨迹】
// 在环境 E 中, 从 x_0 出发, 执行策略 π,产生1个 episode 的轨迹:
5: <x0,a0,r1,x1,a1,r2,...,xT−1,aT−1,rT,xT><x_0, a_0, r_1, x_1, a_1, r_2, ..., x_{T-1}, a_{T-1}, r_T, x_T><x0,a0,r1,x1,a1,r2,...,xT−1,aT−1,rT,xT> // <x0,a0,r1><x_0, a_0, r_1><x0,a0,r1> 为1组
6:
7: // 3b. 【评估策略 (Q值更新)】
8: G=0G = 0G=0 // 初始化“未来累积奖赏”(Return)
9: // 从后向前遍历轨迹 (t = T-1, T-2, …, 0)
10: for t = T-1 down to 0 do:
11: // 1. 高效计算累积奖赏
12: // G=rt+1+γ×GG = r_{t+1} + \gamma \times GG=rt+1+γ×G
13: G=rt+1+γ×GG = r_{t+1} + \gamma \times GG=rt+1+γ×G
14:
15: // 2. 使用“增量式平均” (公式 16.2) 更新 Q 值
16: // 将 G 视为 (x_t, a_t) 这对“摇臂”的一次“奖赏”
17: Q(xt,at)=Q(xt,at)×count(xt,at)+Gcount(xt,at)+1Q(x_t, a_t) = \frac{Q(x_t, a_t) \times \text{count}(x_t, a_t) + G}{\text{count}(x_t, a_t) + 1}Q(xt,at)=count(xt,at)+1Q(xt,at)×count(xt,at)+G
18: count(xt,at)=count(xt,at)+1\text{count}(x_t, a_t) = \text{count}(x_t, a_t) + 1count(xt,at)=count(xt,at)+1
19: end for
20:
21: // 3c. 【改进策略 (ε-贪心)】
22: for x in 所有在轨迹中出现过的状态 x do:
23: a∗=argmaxa′Q(x,a′)a^* = \arg\max_{a'} Q(x, a')a∗=argmaxa′Q(x,a′) // 1. 找到“利用”的动作
24: for a in A(x) do: // 2. 更新所有动作的概率
25: if a==a∗a == a^*a==a∗ then:
26: π(x,a)=1−ϵ+ϵ/∣A(x)∣\pi(x, a) = 1 - \epsilon + \epsilon / |A(x)|π(x,a)=1−ϵ+ϵ/∣A(x)∣
27: else:
28: π(x,a)=ϵ/∣A(x)∣\pi(x, a) = \epsilon / |A(x)|π(x,a)=ϵ/∣A(x)∣
29: end if
30: end for
31: end for
32: end for
伪代码讲解 (图 16.10):
-
Line 1-2 (初始化):
Q(x, a)和count(x, a)是什么?- 它们不是集合,而是两个巨大的 “查找表” (Lookup Tables)。在实际编程中,你可以把它们想象成两个字典 (Dictionary) 或哈希表 (Hash Map)。
Q(x, a):这个表存储的是“状态-动作对”的价值。它的“键”是(x, a)对,“值”是一个数字,代表我们当前对“在状态 xxx 下执行动作 aaa”的平均累积奖赏的估计。count(x, a):这是一个并行的“记账本”。它的“键”也是(x, a)对,“值”也是一个数字,代表我们总共访问过(x, a)这对组合多少次。- Line 1 的 ∀x∈X,a∈A\forall x \in X, a \in A∀x∈X,a∈A 是一个概念上的描述,意思是“这个表格准备好存储所有可能的
(x, a)组合”。在实际操作中,你不需要(也不可能)
在一开始就初始化所有(x, a)。你通常是“惰性” (lazy) 初始化:当你在 Line 17 第一次遇到某个(x_t, a_t)组合时,你才在Q表和count表中创建这个条目,并将其值设为 0。
-
x, a, r 和 Q表的关系:
- 1.
x可以理解为模型每一帧的输入吗?- 是的。
x就是智能体在 ttt 时刻观察到的“环境快照”。 - 重要限制:在这个“表格型”算法中,
x必须是离散的、可枚举的。比如“格子世界中的(2, 3)坐标”或“西瓜的‘健康’状态”。它不能是原始的、高维的图像(比如[1080, 1920, 3]的像素矩阵),因为你无法为“每一张可能的图像”都在Q表里创建一个条目。
- 是的。
- 2.
a是每一帧的动作输出吗?- 是的。
a就是智能体根据x决定执行的动作,比如“向东走”或“浇水”。
- 是的。
- 3.
r是每一帧的奖励吗?- 是的。
r_t是即时奖赏 (immediate reward)。它是你在 t−1t-1t−1 时刻做出动作 at−1a_{t-1}at−1 后,环境在 ttt 时刻立即反馈给你的“分数”。
- 是的。
- 4. Q表是不是要记录“每个t对应的x和a,以及其对应的r”?
- 不,这是最关键的区别!
Q表不记录r(即时奖赏)。 Q表记录的是G(未来累积奖赏)的平均值。Q(x, a)不是日志 (Log):它不记录“我在第1幕的第3帧遇到了(x_1, a_1),回报是G=10;在第5幕的第8帧又遇到了(x_1, a_1),回报是G=12”。Q(x, a)是摘要 (Summary):它只记录“对于(x_1, a_1)这个组合,我总共见过了count=2次,它们的回报G的平均值现在是Q=11。”- 这就是 Line 17
(Q * count + G) / (count + 1)的全部意义:它是在更新这个平均值,而不是在“记录”一个新的条目。
- 不,这是最关键的区别!
- 1.
-
Line 3 (主循环): 算法会不断产生新的轨迹(幕-episode),直到设置的 episode 的上限
-
Line 5 (生成轨迹): 这是“同策略”的核心。算法使用它当前的策略 π\piπ(它是一个 ϵ\epsilonϵ-贪心策略)与环境交互,从头(x0x_0x0)到尾(xTx_TxT)跑完一整幕,并记录下所有
(x, a, r)。 -
Line 8-19 (遍历轨迹与更新Q值): 这是 MC 方法的核心,也是算法实现的关键。
for t = T-1 down to 0和 G=rt+1+γ×GG = r_{t+1} + \gamma \times GG=rt+1+γ×G 是如何工作的?- 这个
for循环没有问题,它是一种非常高效的动态规划技巧,用来计算轨迹上每一步的“未来累积奖赏”(也称为 Return)。 G是一个临时累加器,它的值在循环的每一步中都会被覆盖。- 我们来一步一步走这个循环 (Line 8-19),假设 γ=0.9\gamma=0.9γ=0.9:
- Line 8: 循环开始前,
G被初始化为0。 - 第 1 轮循环 (
t = T-1):t等于T-1。- Line 13:
G = r_{(T-1)+1} + \gamma * G→\rightarrow→G = r_T + 0.9 * 0→\rightarrow→G = r_T。 G现在的值是r_T。这个G是(x_{T-1}, a_{T-1})这对组合的“回报”。- Line 17: 我们更新
Q(x_{T-1}, a_{T-1})的值。假设这是我们第一次遇到(x_{T-1}, a_{T-1}),那么Q和count都是 0。Q(x_{T-1}, a_{T-1}) = (0 * 0 + G) / (0 + 1) = G(即r_T)。
- Line 18:
count(x_{T-1}, a_{T-1}) = 0 + 1 = 1。 - 小结:在
t=T-1时,我们计算出最后一步的(x,a)对的回报是r_T,并更新了Q表:Q(x_{T-1}, a_{T-1})的新估计值是r_T,访问次数是 1。
- (省略后续循环 t 的推演)
- Line 8: 循环开始前,
- 这个
- 总结:这个反向循环是一个绝妙的技巧。它只用一个变量
G,就在一次遍历中,为轨迹中的每一个(x_t, a_t)对都计算出了它对应的正确的未来折扣累积奖赏。
-
Line 22-31 (改进策略): 在评估完这一幕轨迹(即用 Line 10-19 更新了
Q表)之后,我们立刻改进 (Improve) 我们的策略π。这个过程被称为 “策略改进” (Policy Improvement)。-
Line 22: for x in 所有在轨迹中出现过的状态 x do:- 讲解: 我们只更新那些在本幕 (episode) 中实际访问过的状态 xxx 所对应的策略。这是一个效率优化,我们不需要去更新那些我们根本没去过的状态的策略。
-
Line 23: a^* = \arg\max_{a'} Q(x, a')- 讲解: 这是从“价值函数” (
Q表) 中提取“贪心策略”的核心步骤。我们来拆解这里的所有符号: x是什么?x是一个特定的状态,比如在“西瓜”例子中x = "健康",或在“格子世界”中x = (2, 3)。
A(x)是什么? (Line 24 中会用到)A(x)是一个集合 (Set),代表在状态x下所有可用的动作 (Action)。- 数据结构:
{"浇水", "不浇水"}或者{"北", "南", "东", "西"}。 |A(x)|是什么? (Line 26/28 中会用到)|A(x)|是这个集合的大小 (cardinality),即一个数字。如果A(x) = {"北", "南", "东", "西"},那么|A(x)| = 4。
a'(a-prime) 是什么?a'是一个迭代变量 (iterator) 或“哑变量”。\arg\max_{a'}的意思是:“请遍历A(x)集合中的每一个动作a'…”。
Q(x, a')是什么?- 这是在查询 (Query) 我们的
Q表。我们遍历a',对每一个a' \in A(x),都去Q表中查出(x, a')这个键 (key) 对应的价值 (value)。
- 这是在查询 (Query) 我们的
a^*(a-star) 是什么?a^*是\arg\max运算的结果。它不是一个数字,而是那个导致Q(x, a')值最大的特定动作 (action)。- 数据结构: 和
a一样,是一个动作,比如"浇水"或"东"。
- 一个具体的例子 (假设
x = (2, 3)):A(x)是{"北", "南", "东", "西"}。a'开始遍历。- 查询
Q表:a' = "北": 查到Q((2,3), "北") = 10.5a' = "南": 查到Q((2,3), "南") = -5.1a' = "东": 查到Q((2,3), "东") = 15.2(在本幕中刚被更新过)a' = "西": 查到Q((2,3), "西") = 8.0
\arg\max比较这些值 (10.5, -5.1, 15.2, 8.0),发现 15.2 是最大的。a^*被赋值为导致 15.2 的那个动作。- 最终结果:
a^* = "东"。
- 讲解: 这是从“价值函数” (
-
一个关键问题:
Q(x, a')和Q(x_t, a_t)(Line 17) 有何不同?Q(x_t, a_t)(Line 17): 这是一个写操作 (Update)。x_t和a_t是过去时,它们是轨迹中在t时刻已经发生的特定状态和动作。我们用G(回报) 来更新Q表中这一个条目。Q(x, a')(Line 23): 这是一个读操作 (Query)。x是一个给定的状态,a'是未来时,代表所有可能的动作。我们查询Q表中的多个条目,目的是为了决策——找出最好的动作a^*是谁。
-
Line 24-31: for a in A(x) do ... end for- 讲解: 现在我们已经知道了在状态
x下最好的动作是a^*(比如"东")。接下来的这个循环是去更新策略π。 π(x, a)(pi) 是什么?它和Q表是什么关系?π(pi) 就是策略 (Policy)。在“表格型”强化学习中,它也是一个查找表 (Lookup Table),就像Q表一样。Q表 (价值函数) 存储的是价值(Value):Q(x, a)存储一个数字 (比如 15.2),代表“在x做a有多好”。π表 (策略函数) 存储的是概率(Probability):π(x, a)存储一个概率 (比如 0.925),代表“在x时,我们有多大概率选择a”。- 关系:
π是根据Q计算出来的。Q表是“事实依据”,π表是基于这些依据做出的“行动计划”。Line 22-31 的全部工作,就是根据Q表的最新事实,来更新π表的行动计划。
- 讲解: 现在我们已经知道了在状态
-
Line 26: π(x,a)=1−ϵ+ϵ/∣A(x)∣π(x, a) = 1 - \epsilon + \epsilon / |A(x)|π(x,a)=1−ϵ+ϵ/∣A(x)∣
-
Line 28: π(x,a)=ϵ/∣A(x)∣π(x, a) = \epsilon / |A(x)|π(x,a)=ϵ/∣A(x)∣
- 讲解: 这两行就是在构建
\epsilon-贪心策略。我们继续用上面的例子: - 已知:
x = (2, 3),a^* = "东",\epsilon = 0.1,|A(x)| = 4。 - 计算“探索”概率:
\epsilon / |A(x)| = 0.1 / 4 = 0.025。 - 计算“利用”概率:
1 - \epsilon = 1 - 0.1 = 0.9。 for a in A(x)循环开始:a = "北":a不等于a^*( “北” != “东” )。- 执行
Line 28:π((2,3), "北") = 0.025。
- 执行
a = "南":a不等于a^*( “南” != “东” )。- 执行
Line 28:π((2,3), "南") = 0.025。
- 执行
a = "东":a等于a^*( “东” == “东” )。- 执行
Line 26:π((2,3), "东") = 0.9 + 0.025 = 0.925。
- 执行
a = "西":a不等于a^*( “西” != “东” )。- 执行
Line 28:π((2,3), "西") = 0.025。
- 执行
- 循环结束。我们更新了
π表中关于x = (2, 3)状态的策略:π((2,3))对应的策略现在是:{"北": 0.025, "南": 0.025, "东": 0.925, "西": 0.025}。- (检查总和: 0.025 * 3 + 0.925 = 1.0。完美。)
- 为什么
Line 26的公式是1 - \epsilon + \epsilon / |A(x)|?- 因为
\epsilon-贪心策略的含义是:- 你有
1 - \epsilon(90%) 的概率去利用(即选择a^*)。 - 你有
\epsilon(10%) 的概率去探索(即在所有|A(x)|个动作中均匀随机选择一个)。
- 你有
- 这意味着,
a^*( “东” ) 这个动作,它既能从“利用”中分到1 - \epsilon(90%) 的概率,也能从“探索”中分到\epsilon / |A(x)|(2.5%) 的概率。所以它的总概率是这两者之和。 - 而其他所有非最优动作(“北”, “南”, “西”),它们只能从“探索”中分到
\epsilon / |A(x)|(2.5%) 的概率。
- 因为
- 讲解: 这两行就是在构建
-
-
Line 32 (end for): 这一幕 (episode sss) 结束。我们已经用这一幕的经验,更新了
Q表(Line 10-19),并基于更新后的Q表,更新了π表(Line 22-31)。-
现在,算法回到
Line 3,开始下一幕 (episode s+1s+1s+1) 游戏。 -
最关键的是,在
Line 5,当它要生成下一条轨迹时,它会使用这个刚刚被微小改进过的新策略π。这就是“同策略” (On-Policy) 的精髓:策略在“自我迭代”,用自己(sss 时刻的 π\piπ)产生的经验,来创造一个更好的自己(s+1s+1s+1 时刻的 π\piπ)。
-
这个“生成轨迹 →\rightarrow→ 评估 QQQ →\rightarrow→ 改进策略 π\piπ”的循环不断重复,最终 Q 表和策略 π\piπ 将收敛到(近似)最优。
异策略蒙特卡洛学习 (Off-Policy MC)
“同策略” (On-Policy) 算法(如图 16.10)有一个核心限制:它必须在“探索”和“利用”之间进行妥协。它最终学习到的,是一个 ϵ\epsilonϵ-贪心策略,而不是一个最优的(纯贪心)策略。
我们真正想要的,是学习一个确定性的最优策略 π\piπ(即“原始策略”,Original Policy),但为了保证充分探索,我们的“试错”数据(轨迹)又必须来自一个随机性的探索策略 π′\pi'π′(如 ϵ\epsilonϵ-贪心策略)。
💡 什么是“异策略” (Off-Policy)?
它的含义是:我们使用一个策略(称为 “行为策略” π′\pi'π′,Behavior Policy)来与环境交互、生成轨迹数据;同时,我们利用这些数据来评估和改进另一个策略(称为 “目标策略” π\piπ,Target Policy)。
- 目标策略 π\piπ: 我们真正想学习的策略。在 16.4.1 中,这就是我们想要的那个确定性的、纯贪心的最优策略。
- 行为策略 π′\pi'π′: 我们用来探索环境、收集样本的策略。它必须是探索性的(例如 ϵ\epsilonϵ-贪心),以确保能采样到所有可能的 (x,a)(x, a)(x,a) 对。
这就带来了一个核心问题:我们如何使用从 π′\pi'π′ 获得的“回报” RRR 来估计 π\piπ 的 QπQ^\piQπ 值?这两个策略下,同一个 (x,a)(x, a)(x,a) 对的期望回报是不同的。
答案是使用 “重要性采样” (Importance Sampling)。
重要性采样 (Importance Sampling)
让我们用一个非常具体的比喻来理解重要性采样。
比喻:估计 A 班的平均分,但你只能抽 B 班的学生
- 你的目标 (Target):你想知道 A 班(目标策略 π\piπ)学生的平均数学成绩(期望回报 Eπ[R]E_\pi[R]Eπ[R])。
- 你的限制 (Behavior):你没有 A 班的学生名单。你只能去B 班(行为策略 π′\pi'π′)随机抽查学生,问他们的成绩。
- 已知信息:
- A 班的“学霸”比例是 50%,B 班的“学霸”比例是 10%。
- A 班的“学渣”比例是 50%,B 班的“学渣”比例是 90%。
- 学霸的成绩都是 100 分,学渣的成绩都是 50 分。
问题:如果你直接抽 B 班的学生,然后计算他们的平均分,你会得到什么?
你大概率会抽到 9 个学渣和 1 个学霸,平均分 ≈(9×50+1×100)/10=55\approx (9 \times 50 + 1 \times 100) / 10 = 55≈(9×50+1×100)/10=55 分。
这个 55 分严重低估了 A 班的真实平均分(应该是 (50%×100+50%×50)=75(50\% \times 100 + 50\% \times 50) = 75(50%×100+50%×50)=75 分)。
重要性采样的作用:
重要性采样提供了一个 “加权” 的方法,来修正这个偏差。
它的核心思想是:“你从 B 班抽到的这个样本,在 A 班有多‘重要’(即多‘稀有’)?”
-
当你从 B 班抽到了一个学渣(50 分)时:
- 这个学渣在 A 班出现的概率 p(学渣)=0.5p(\text{学渣}) = 0.5p(学渣)=0.5
- 这个学渣在 B 班出现的概率 q(学渣)=0.9q(\text{学渣}) = 0.9q(学渣)=0.9
- 权重 ρ=p/q=0.5/0.9≈0.56\rho = p/q = 0.5 / 0.9 \approx 0.56ρ=p/q=0.5/0.9≈0.56。
- 解读:B 班的学渣“太不值钱了”,A 班没那么多学渣。所以我们要给这个 50 分的样本一个更低的权重(小于 1)。
-
当你从 B 班抽到了一个学霸(100 分)时:
- 这个学霸在 A 班出现的概率 p(学霸)=0.5p(\text{学霸}) = 0.5p(学霸)=0.5
- 这个学霸在 B 班出现的概率 q(学霸)=0.1q(\text{学霸}) = 0.1q(学霸)=0.1
- 权重 ρ=p/q=0.5/0.1=5.0\rho = p/q = 0.5 / 0.1 = 5.0ρ=p/q=0.5/0.1=5.0。
- 解读:B 班的学霸“太稀有了”,在 A 班其实很常见。所以我们要给这个 100 分的样本一个巨大的权重(大于 1)。
现在,我们用这个加权平均来重新计算:
(1×学霸的权重×100分+9×学渣的权重×50分)/10(1 \times \text{学霸的权重} \times 100\text{分} + 9 \times \text{学渣的权重} \times 50\text{分}) / 10(1×学霸的权重×100分+9×学渣的权重×50分)/10
≈(1×5.0×100+9×0.56×50)/10\approx (1 \times 5.0 \times 100 + 9 \times 0.56 \times 50) / 10≈(1×5.0×100+9×0.56×50)/10
≈(500+252)/10=75.2\approx (500 + 252) / 10 = 75.2≈(500+252)/10=75.2 分。
看!这个结果就非常接近 A 班的真实平均分 75 分了。
现在,我们来看数学公式:
我们想计算 E[f(x)]E[f(x)]E[f(x)],其中 x∼px \sim px∼p,但我们只能从 x∼qx \sim qx∼q 采样:
Ep[f]=∫p(x)f(x)dx=∫q(x)p(x)q(x)f(x)dx=Eq[p(x)q(x)f(x)] \begin{aligned} E_p[f] &= \int p(x) f(x) dx \\ &= \int q(x) \frac{p(x)}{q(x)} f(x) dx \\ &= E_q\left[ \frac{p(x)}{q(x)} f(x) \right] \end{aligned} Ep[f]=∫p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Eq[q(x)p(x)f(x)] (基于 16.23)
公式 (16.23) 拆解:
这个公式是重要性采样的理论核心。它展示了我们如何将一个“无法计算的期望”转变为一个“可以计算的期望”。
- Ep[f]=∫p(x)f(x)dxE_p[f] = \int p(x) f(x) dxEp[f]=∫p(x)f(x)dx:目标期望值。
- 这就是我们“想求的平均值”。
- 积分 ∫\int∫ 在这里是计算连续变量(例如状态是车速、角度)的期望(平均值)的数学定义。
- 它在概念上等同于 A/B 班比喻中离散情况下的求和 ∑\sum∑。
- 比喻中:A 班的真实平均分(75 分),即 EA[分数]=∑xpA(x)×分数(x)E_A[\text{分数}] = \sum_x p_A(x) \times \text{分数}(x)EA[分数]=∑xpA(x)×分数(x)。
- f(x)f(x)f(x):你关心的那个“值”。
- 比喻中:就是学生 xxx 的分数(100分 或 50分)。
- p(x)p(x)p(x):xxx 在“目标分布”中发生的概率密度 (PDF)。
- 比喻中:学生 xxx(比如“学霸”)在 A 班 出现的概率(p(学霸)=0.5p(\text{学霸})=0.5p(学霸)=0.5)。
- q(x)q(x)q(x):xxx 在“行为分布”中发生的概率密度 (PDF)(你实际采样的分布)。
- 比喻中:学生 xxx(比如“学霸”)在 B 班 出现的概率(q(学霸)=0.1q(\text{学霸})=0.1q(学霸)=0.1)。
- p(x)q(x)\frac{p(x)}{q(x)}q(x)p(x):这就是重要性采样系数 ρ(x)\rho(x)ρ(x)。
- 比喻中:我们计算的权重(学霸的权重是 5.0)。
- Eq[… ]E_q\left[ \dots \right]Eq[…]:在“行为分布” qqq 下求期望。
- 比喻中:在 B 班 进行抽样。
- Eq[p(x)q(x)f(x)]E_q\left[ \frac{p(x)}{q(x)} f(x) \right]Eq[q(x)p(x)f(x)]:
- 这就是整个变换的“魔术”:它告诉我们,想求 f(x)f(x)f(x) 在 A 班的平均分,我们不需要在 A 班抽样;我们只需要在 B 班 抽样,然后计算 p(x)q(x)f(x)\frac{p(x)}{q(x)} f(x)q(x)p(x)f(x) 这个“加权分数”的平均分即可。这两个平均分的期望在数学上是严格相等的。
在实际操作中,我们无法计算精确的期望 EqE_qEq,我们只能通过有限的 mmm 个样本来近似它:
E^p[f]≈1m∑i=1mp(xi)q(xi)f(xi)\hat{E}_p[f] \approx \frac{1}{m} \sum_{i=1}^m \frac{p(x_i)}{q(x_i)} f(x_i)E^p[f]≈m1i=1∑mq(xi)p(xi)f(xi) (基于 16.24)
公式 (16.24) 拆解:
这个公式是实践操作。它告诉我们如何用有限的样本去估计公式 (16.23) 那个理论上的期望值。这就是蒙特卡洛方法。
公式 (16.23) 是一个理论上的期望(用 ∫\int∫ 或 EqE_qEq 表示),我们无法精确计算它。所以我们通过在 qqq 分布(B班)中实际采样 mmm 次,用 mmm 个样本的平均值来近似它。
- mmm:你采样的总次数。
- 比喻中:你总共从 B 班抽了 m=10m=10m=10 个学生。
- xix_ixi:你抽到的第 iii 个样本(xix_ixi 是从 qqq 分布中抽取的)。
- 比喻中:你抽到的第 iii 个学生(比如,他是个“学霸”)。
- f(xi)f(x_i)f(xi):这个样本的值。
- 比喻中:这个“学霸”学生的分数(f(xi)=100f(x_i)=100f(xi)=100)。
- p(xi)q(xi)\frac{p(x_i)}{q(x_i)}q(xi)p(xi):这个样本的权重。
- 比喻中:p(学霸)q(学霸)=0.50.1=5.0\frac{p(\text{学霸})}{q(\text{学霸})} = \frac{0.5}{0.1} = 5.0q(学霸)p(学霸)=0.10.5=5.0。
- ∑i=1m…\sum_{i=1}^m \dots∑i=1m…:把所有 mmm 个样本的“加权分数”全部加起来。
- 1m∑…\frac{1}{m} \sum \dotsm1∑…:除以 mmm,求“加权平均分”。
- 这就是我们对 Ep[f]E_p[f]Ep[f](A班的真实平均分)的最终估计值。当 mmm 越大(抽的学生越多),这个估计值就越接近真实的 75 分。
将重要性采样应用于 MC
现在,我们把上面的比喻完美地对应到强化学习中:
| 抽象比喻 | 强化学习 (RL) |
|---|---|
| A 班 (想了解的) | 目标策略 π\piπ (Target Policy),例如那个纯贪心的最优策略。 |
| B 班 (能采样的) | 行为策略 π′\pi'π′ (Behavior Policy),例如 ϵ\epsilonϵ-贪心策略。 |
| p(x)p(x)p(x) (在 A 班的概率) | PπP^\piPπ (一条轨迹在 π\piπ 下发生的概率)。 |
| q(x)q(x)q(x) (在 B 班的概率) | Pπ′P^{\pi'}Pπ′ (同一条轨迹在 π′\pi'π′ 下发生的概率)。 |
| xxx (一个学生) | TTT (一条完整的轨迹) <x0,a0,r1,…,xT><x_0, a_0, r_1, \dots, x_T><x0,a0,r1,…,xT>。 |
| f(x)f(x)f(x) (学生的分数) | RRR (轨迹的回报),即 ∑γtrt+1\sum \gamma^t r_{t+1}∑γtrt+1。 |
现在我们来推导 RL 中的“权重” ρ\rhoρ:
我们需要计算 ρ=p(x)q(x)=PπPπ′\rho = \frac{p(x)}{q(x)} = \frac{P^\pi}{P^{\pi'}}ρ=q(x)p(x)=Pπ′Pπ。
一条轨迹发生的概率 PπP^\piPπ 是什么?它等于一连串事件发生的概率之和:
- 在 x0x_0x0 选择 a0a_0a0 的概率(由策略 π\piπ 决定)
- 并且 环境从 x0x_0x0 转移到 x1x_1x1 的概率(由环境 Px→x′P_{x \to x'}Px→x′ 决定)
- 并且 在 x1x_1x1 选择 a1a_1a1 的概率(由策略 π\piπ 决定)
- 并且 环境从 x1x_1x1 转移到 x2x_2x2 的概率(由环境 Px→x′P_{x \to x'}Px→x′ 决定)
- …以此类推
Pπ=∏i=0T−1π(xi,ai)Pxi→xi+1aiP^\pi = \prod_{i=0}^{T-1} \pi(x_i, a_i) P_{x_i \to x_{i+1}}^{a_i}Pπ=i=0∏T−1π(xi,ai)Pxi→xi+1ai (基于 16.27)
公式 (16.27) 拆解:
- PπP^\piPπ:目标策略 π\piπ 跑出这条轨迹 TTT 的总概率 (这就是 p(x)p(x)p(x))。
- ∏i=0T−1\prod_{i=0}^{T-1}∏i=0T−1:连乘符号。代表 P0×P1×⋯×PT−1\text{P}_0 \times \text{P}_1 \times \dots \times \text{P}_{T-1}P0×P1×⋯×PT−1。
- π(xi,ai)\pi(x_i, a_i)π(xi,ai):目标策略 π\piπ 在状态 xix_ixi 时,选择动作 aia_iai 的概率。
- Pxi→xi+1aiP_{x_i \to x_{i+1}}^{a_i}Pxi→xi+1ai:环境在 xix_ixi 状态和 aia_iai 动作下,转移到 xi+1x_{i+1}xi+1 状态的概率。
同理,行为策略 π′\pi'π′ 跑出同一条轨迹的概率为:
Pπ′=∏i=0T−1π′(xi,ai)Pxi→xi+1aiP^{\pi'} = \prod_{i=0}^{T-1} \pi'(x_i, a_i) P_{x_i \to x_{i+1}}^{a_i}Pπ′=i=0∏T−1π′(xi,ai)Pxi→xi+1ai
现在,计算权重 ρ\rhoρ (即 PπPπ′\frac{P^\pi}{P^{\pi'}}Pπ′Pπ):
ρ=∏i=0T−1π(xi,ai)Pxi→xi+1ai∏i=0T−1π′(xi,ai)Pxi→xi+1ai\rho = \frac{\prod_{i=0}^{T-1} \pi(x_i, a_i) P_{x_i \to x_{i+1}}^{a_i}}{\prod_{i=0}^{T-1} \pi'(x_i, a_i) P_{x_i \to x_{i+1}}^{a_i}}ρ=∏i=0T−1π′(xi,ai)Pxi→xi+1ai∏i=0T−1π(xi,ai)Pxi→xi+1ai
关键的简化来了!
你会发现,分子和分母中,所有与环境相关的项 Pxi→xi+1aiP_{x_i \to x_{i+1}}^{a_i}Pxi→xi+1ai 是完全一样的!它们可以全部约掉!
这太棒了!因为我们是“免模型”学习,我们根本不知道环境的 Px→x′P_{x \to x'}Px→x′ 是什么。而这个公式告诉我们,我们根本不需要知道它!
我们只需要知道两个策略本身:
ρ0:T−1=∏t=0T−1π(xt,at)π′(xt,at) \rho_{0:T-1} = \prod_{t=0}^{T-1} \frac{\pi(x_t, a_t)}{\pi'(x_t, a_t)} ρ0:T−1=t=0∏T−1π′(xt,at)π(xt,at) (基于 16.28)
公式 (16.28) 拆解:
- ρ0:T−1\rho_{0:T-1}ρ0:T−1:这条从 0 到 T−1T-1T−1 的完整轨迹的权重。
- π(xt,at)π′(xt,at)\frac{\pi(x_t, a_t)}{\pi'(x_t, a_t)}π′(xt,at)π(xt,at):在 ttt 时刻的单步权重。
- π(xt,at)\pi(x_t, a_t)π(xt,at):我们的目标策略(例如纯贪心)在 xtx_txt 时 会 选择 ata_tat 的概率。(如果 ata_tat 是贪心动作,概率为 1;否则为 0)。
- π′(xt,at)\pi'(x_t, a_t)π′(xt,at):我们的行为策略(例如 ϵ\epsilonϵ-贪心)在 xtx_txt 时 实际 选择 ata_tat 的概率。(例如 1−ϵ+ϵ/∣A∣1-\epsilon+\epsilon/|A|1−ϵ+ϵ/∣A∣ 或 ϵ/∣A∣\epsilon/|A|ϵ/∣A∣)。
最终的 Q 值更新:
当我们更新 Q(xt,at)Q(x_t, a_t)Q(xt,at) 时,我们只关心从 ttt 时刻开始的未来回报 RtR_tRt。
因此,我们也只需要计算从 ttt 时刻开始的未来权重 ρt:T−1\rho_{t:T-1}ρt:T−1。
我们的 QQQ 值更新(使用“普通重要性采样” OIS)就变成了:
Q(xt,at)←Average(ρt:T−1×Rt) Q(x_t, a_t) \leftarrow \text{Average}\left( \rho_{t:T-1} \times R_t \right) Q(xt,at)←Average(ρt:T−1×Rt) (基于 16.26)
公式 (16.26) 拆解:
- Q(xt,at)Q(x_t, a_t)Q(xt,at):我们要更新的目标,即“在状态 xtx_txt 执行 ata_tat”的价值。
- RtR_tRt:我们在这条轨迹中,从 ttt 时刻开始,实际观测到的未来累积回报 (这就是 f(x)f(x)f(x))。
- ρt:T−1\rho_{t:T-1}ρt:T−1:从 ttt 时刻开始的权重 (这就是 ρ(x)\rho(x)ρ(x))。
- ρt:T−1×Rt\rho_{t:T-1} \times R_tρt:T−1×Rt:“加权回报”。
- Average(… )\text{Average}(\dots)Average(…):
- 比喻中:我们用 (加权分数1+⋯+加权分数m)/m(\text{加权分数}_1 + \dots + \text{加权分数}_m) / m(加权分数1+⋯+加权分数m)/m 来估计平均分。
- RL 中:我们使用增量式平均(例如伪代码中的
Q = (Q * count + R) / (count + 1))来不断更新 Q(xt,at)Q(x_t, a_t)Q(xt,at) 的平均值。这里的 RRR 就是指这个加权回报 ρt:T−1×Rt\rho_{t:T-1} \times R_tρt:T−1×Rt。
$$
异策略 MC 算法伪代码
教材 图 16.11 给出了异策略 MC 算法的伪代码。这是一个“普通重要性采样” (OIS) 的实现,它使用增量式平均(类似式 16.2)来更新 Q 值。
1: Q(x,a)=0,count(x,a)=0,∀x∈X,a∈AQ(x, a) = 0, \text{count}(x, a) = 0, \forall x \in X, a \in AQ(x,a)=0,count(x,a)=0,∀x∈X,a∈A
π(x)=argmaxa′Q(x,a′)\pi(x) = \arg\max_{a'} Q(x, a')π(x)=argmaxa′Q(x,a′) // 初始化 π\piπ 为确定性贪心策略
2: for s = 1, 2, … do: // 循环每一“幕” (episode)
3: // 3a. 【用 π′\pi'π′ 生成轨迹】
// 在 E 中执行 ϵ\epsilonϵ-贪心策略 π′\pi'π′ (基于当前 Q) 产生轨迹:
<x0,a0,r1,x1,a1,r2,...,xT−1,aT−1,rT,xT><x_0, a_0, r_1, x_1, a_1, r_2, ..., x_{T-1}, a_{T-1}, r_T, x_T><x0,a0,r1,x1,a1,r2,...,xT−1,aT−1,rT,xT>
4:
5: // 3b. 【评估策略 π\piπ (Q值更新)】
// (注:书中伪代码此处的实现非常独特, 是一种前向计算方式)
// (为便于理解, 此处解释其“意图”)
6: for t = 0, 1, …, T-1 do: // 遍历轨迹中的每一步
7: // 1. 计算从 t 时刻开始的实际回报 GtG_tGt
8: Gt=∑i=t+1Tγi−t−1riG_t = \sum_{i=t+1}^{T} \gamma^{i-t-1} r_iGt=∑i=t+1Tγi−t−1ri
9:
10: // 2. 计算此回报的重要性采样系数 ρ\rhoρ
// (即式 16.28, 从 t 到 T-1 的概率比值)
11: ρt:T−1=∏k=tT−1π(xk,ak)π′(xk,ak)\rho_{t:T-1} = \prod_{k=t}^{T-1} \frac{\pi(x_k, a_k)}{\pi'(x_k, a_k)}ρt:T−1=∏k=tT−1π′(xk,ak)π(xk,ak)
12:
13: // 3. 计算加权回报 R
14: R=ρt:T−1×GtR = \rho_{t:T-1} \times G_tR=ρt:T−1×Gt
15:
16: // 4. 使用“增量式平均” (OIS) 更新 Q 值
17: Q(xt,at)=Q(xt,at)×count(xt,at)+Rcount(xt,at)+1Q(x_t, a_t) = \frac{Q(x_t, a_t) \times \text{count}(x_t, a_t) + R}{\text{count}(x_t, a_t) + 1}Q(xt,at)=count(xt,at)+1Q(xt,at)×count(xt,at)+R
18: count(xt,at)=count(xt,at)+1\text{count}(x_t, a_t) = \text{count}(x_t, a_t) + 1count(xt,at)=count(xt,at)+1
19:
20: // 5. 【改进策略 π\piπ】
21: π(xt)=argmaxa′Q(xt,a′)\pi(x_t) = \arg\max_{a'} Q(x_t, a')π(xt)=argmaxa′Q(xt,a′)
22: end for
23: end for
伪代码讲解 (图 16.11):
-
Line 1 (初始化): 这是与“同策略”的第一个关键区别。我们初始化两个策略:
Q和count照常。但目标策略 π\piπ 被显式地初始化为基于 QQQ 的纯贪心策略。 -
Line 3 (生成轨迹): 这是第二个关键区别。我们用于生成轨迹的,是行为策略 π′\pi'π′,它是一个基于当前 QQQ 的 ϵ\epsilonϵ-贪心策略。π\piπ 和 π′\pi'π′ 不再是同一个策略。
-
Line 6-22 (评估与改进): 循环遍历轨迹中的每一个 (xt,at)(x_t, a_t)(xt,at) 对。
- 计算回报 GtG_tGt: 和同策略一样,计算从 (xt,at)(x_t, a_t)(xt,at) 出发,实际获得的累积奖赏。
- 计算 IS 系数 ρt:T−1\rho_{t:T-1}ρt:T−1: 这是异策略的核心。我们必须计算这个回报的“权重”。
- π(xk,ak)\pi(x_k, a_k)π(xk,ak): 目标策略 π\piπ (纯贪心) 选择 aka_kak 的概率。如果 aka_kak 是 π(xk)\pi(x_k)π(xk) (即贪心动作),则概率为 1,否则为 0。
- π′(xk,ak)\pi'(x_k, a_k)π′(xk,ak): 行为策略 π′\pi'π′ (ϵ\epsilonϵ-贪心) 选择 aka_kak 的概率 (值为 1−ϵ+ϵ/∣A∣1-\epsilon+\epsilon/|A|1−ϵ+ϵ/∣A∣ 或 ϵ/∣A∣\epsilon/|A|ϵ/∣A∣)。
- 重要细节:如果轨迹中任何一个 aka_kak (k≥tk \ge tk≥t) 是 π′\pi'π′ 探索(非贪心)时选的,那么 π(xk,ak)=0\pi(x_k, a_k)=0π(xk,ak)=0,导致整个 ρt:T−1=0\rho_{t:T-1}=0ρt:T−1=0。这意味着,我们只从那些“目标策略 π\piπ 也有可能走出的”轨迹片段中学习。
- 计算加权回报 RRR: R=ρ×GtR = \rho \times G_tR=ρ×Gt。
- Line 17-18 (更新 Q 值): 这两行是“普通重要性采样” (OIS) 的增量式更新。我们把加权回报 RRR 当作一个新的样本,更新 QQQ 值的平均值。
- Line 21 (改进策略 π\piπ): 在更新 Q(xt,at)Q(x_t, a_t)Q(xt,at) 之后,我们立刻更新我们的目标策略 π\piπ,使其在 xtx_txt 状态上保持贪心。
-
OIS vs. WIS: 这种 OIS 算法(图 16.11)是无偏的,但其方差可能极大(因为 ρ\rhoρ 的连乘积可能变得非常大)。在实际应用中,更常用的是“加权重要性采样” (Weighted Importance Sampling, WIS),它通过对分母也进行加权来减小方差,尽管这会引入一点偏差。
(注:教材图 16.11 中的 Line 4 和 Line 6 是一种非常规的、前向计算 PDIS (逐决策重要性采样) 的方式,其数学形式复杂。上述伪代码(Line 7-14)是为清晰起见,对图 16.11 算法 意图 的重构,使其与式 16.28 的标准 IS 逻辑保持一致。)

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)