深度学习笔记:灾难性遗忘
【ICML2018】中提到,神经网络的所有的极小值都是连通在一起的;同时给出了如何从一个极小值找到一条通路连到另一个极小值的算法。——>从原始任务的某个极小值出发,在优化新任务的时候。,就可以保证原始任务不受影响了。
·
1 灾难性遗忘介绍
- 当神经网络被训练去学习新的任务时,它可能会完全忘记如何执行它以前学过的任务。
- 这种现象尤其在所谓的“连续学习”(continuous learning)或“增量学习”(incremental learning)场景中很常见
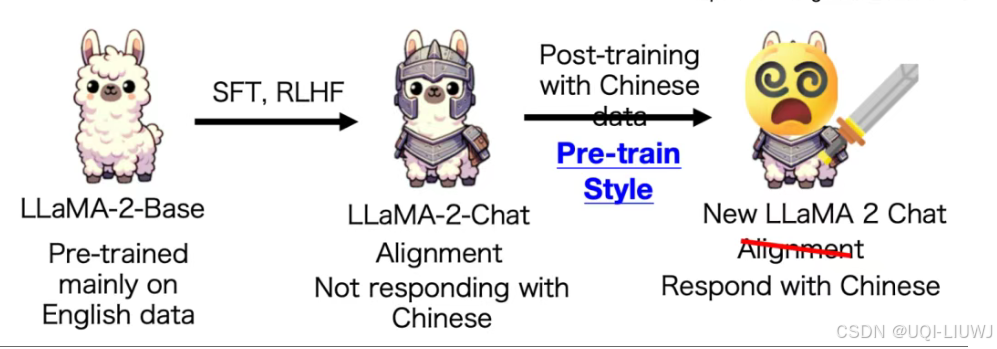
2 不同视角下看待灾难性遗忘 以及对应的解决方法
2.1 从梯度的视角
2.1.1 从梯度的视角看灾难性遗忘
- 我们有两个不同任务的损失曲面,用平滑的曲面训练完之后,再在坑坑洼洼的曲面上继续训练

- 在第二个任务上训练完之后,最优点沿着红色的箭头移动(向第二个任务平滑曲面的山峰移动),相当于向第一个任务(平滑曲面)的底部走了
- ——>第一个任务的损失越来越高,效果越来越差,这就是灾难性遗忘
2.1.2 从梯度的视角解决灾难性遗忘(1)——找到联通路径
[1803.00885] Essentially No Barriers in Neural Network Energy Landscape (arxiv.org) 【ICML2018】中提到,神经网络的所有的极小值都是连通在一起的;同时给出了如何从一个极小值找到一条通路连到另一个极小值的算法
——>从原始任务的某个极小值出发,在优化新任务的时候尽量沿着底部的通道走,就可以保证原始任务不受影响了
2.1.3 从梯度的视角解决灾难性遗忘(2)——新任务梯度和原始任务梯度垂直
- 在优化新任务的时候,保证优化的方向和原始任务不相干
- Orthogonal gradient descent for continual learning PMLR 2020:保证在优化新任务的时候产生的梯度和原始任务产生的梯度在一个低秩空间是垂直的
2.2 从权重的角度
2.2.1 从权重的角度看灾难性遗忘
- 某些权重对原始任务很重要,经过新任务训练,这些权重发生了改变,原始任务的效果当然也就受到了影响
- 例如,Transformer架构中的注意力机制参数可能同时负责语义理解和语法生成,新任务的训练可能误调与语法相关的权重,导致旧任务性能下降。
2.2.2 从权重的角度解决灾难性遗忘(1)——如何调整权重
Overcoming catastrophic forgetting in neural networks 2016

- 原始任务A的最优参数是分布在灰色区域中的;新训练任务B的最优参数区间在白色区域中
- 如果不做任何限制,训练完A任务后直接训练B任务,可能会沿着蓝色的射线方向走,那么就走出了原始任务A的最优参数区间了
- 所以这里提出了EWC的方法,这样可以让参数不离开原始任务A的最优参数区间,同时接近/到达原始任务B的最优参数区间
- 弹性权重巩固(Elastic Weight Consolidation, EWC)模拟人类大脑对重要记忆的优先保护机制。
- 通过计算每个参数对旧任务的重要性(基于Fisher信息矩阵),在微调时对关键参数施加惩罚项,限制其更新幅度,如同教师标记“核心知识点”防止学生遗忘。
- EWC主要内容
- 重要性评估
- 通过旧任务数据计算参数的Fisher信息,值越高表示该参数对旧任务越关键
- 正则化惩罚
为旧参数值
- 这迫使模型在微调时尽量保持关键参数(Fisher值高的)不变。
- 重要性评估
- EWC挑战
- 计算Fisher矩阵需额外的前向-后向传播,对万亿参数模型而言,单次计算耗时可能超过24小时
2.2.3 从权重的角度解决灾难性遗忘(2)——冻结部分参数
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks 2019 ICLR
- 神经网络里只有一部分权重真正起作用,很多都是没用的
- ——>freeze住重要的参数,不重要的参数finetune(时间序列部分2023年的微调大模型的方法就是这个思路)
2.3 从仿生学的角度
2.3.1 从仿生学的角度看灾难性遗忘
- 仿生学着重于模仿自然界中的生物机制和策略,以解决工程和技术上的挑战。
- 在这个背景下,考虑人类和其他动物是如何处理学习和记忆的,可以帮助我们理解并改善神经网络中的灾难性遗忘问题。
2.3.2 从仿生学的角度解决灾难性遗忘(1)——复习
- 样本复习——训练新任务的时候混一些旧任务的数据样本
2.3.3 缺乏知识蒸馏的先天不足
- 人类大脑能够将短期记忆提炼为长期记忆,形成稳定的知识框架。
- 但AI模型缺乏这种“蒸馏”能力,原始训练数据的分布一旦改变,浅层记忆便迅速消失,表现为对旧任务的突然失效。
3 其他解决方法
3.1 记忆回放
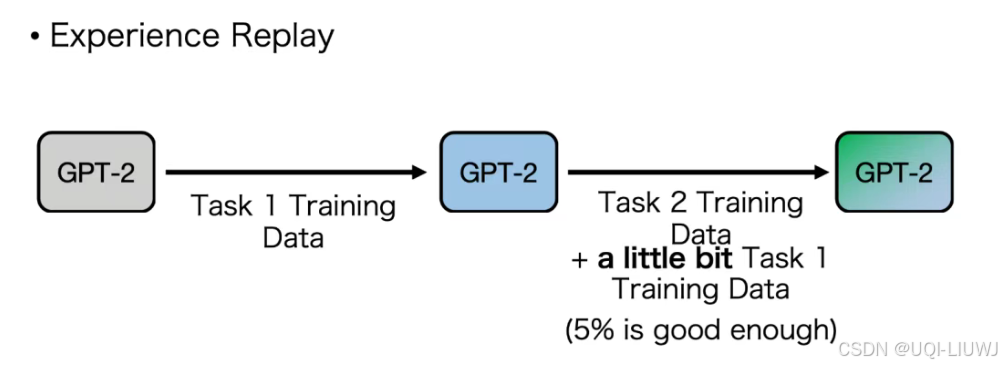
- 记忆回放(Replay Methods)模拟教师在新课中穿插复习旧知识的模式,通过在微调阶段混合新旧数据,强制模型同时维护两类知识
- 例如,在训练法律问答模型时,保留10%的通用文本数据,使模型在学习法律术语的同时,持续巩固日常语言理解能力。
- 优点:
- 实现简单,无需修改模型架构,适用于各类LLMs
- 局限性
- 需存储原始数据集,这在数据隐私严格的场景(如医疗数据)中可能不可行
- 训练成本随数据量线性增加,对千亿参数模型而言,显存占用可能翻倍
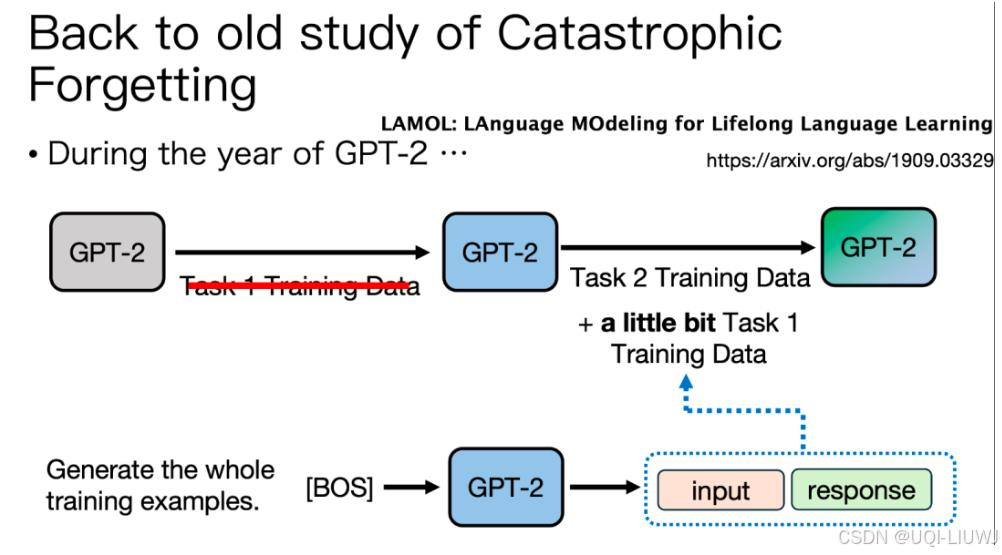
3.1.1 如果没有任务1的训练数据怎么办?
那么如何没有任务1的训练数据怎么办呢?比如现在开源的模型,我们都不知道它的训练数据都有哪些。可以输入一个起始token,让LLM自说自话,产生一些数据,把这些数据作为replay数据训练进去。
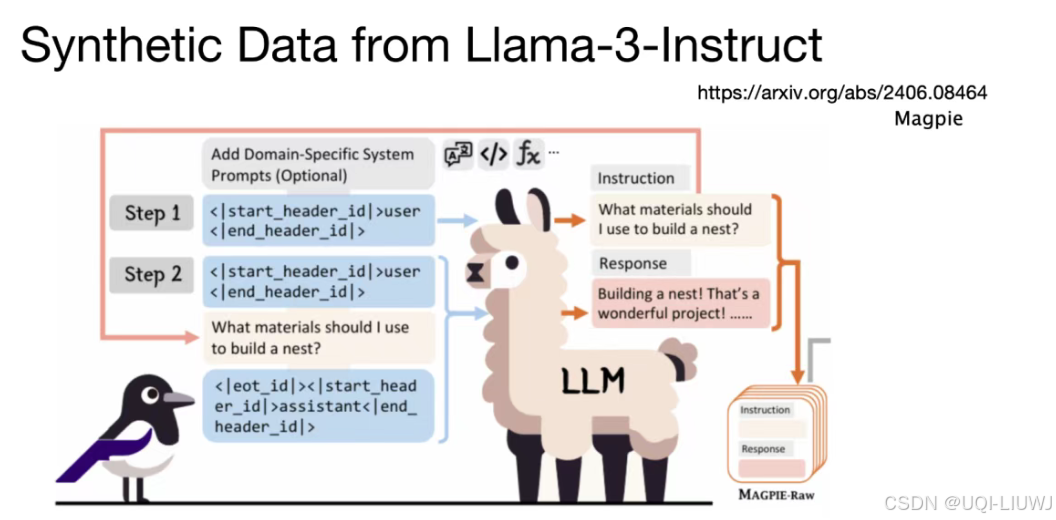
3.2 PEFT
- 为每个新任务分配独立的参数空间,如同给学生不同学科的专用笔记本
- 有以下几种方法
- Adapters
- 在Transformer层间插入小型任务特定模块,仅训练适配器参数而冻结基础模型
- LLaMA-Adapter在医疗微调时,仅新增0.1%参数即可实现专业能力提升,同时保留通用性能。
- LoRA
- 通过低秩矩阵分解近似权重更新,仅训练分解后的小矩阵
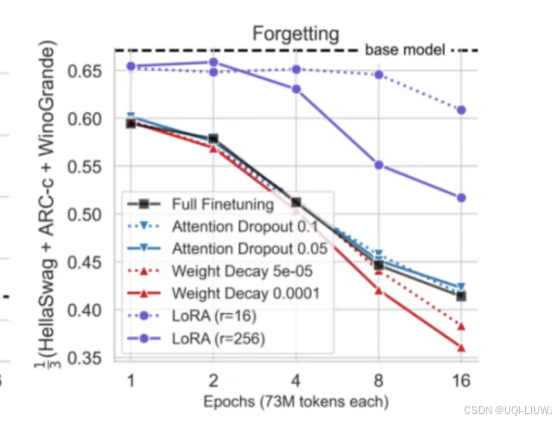
- 相比于dropout,weight decay,LoRA的防止遗忘做的最好
- 通过低秩矩阵分解近似权重更新,仅训练分解后的小矩阵
- Prompt Tuning
- 通过优化输入层的“软提示”向量引导模型行为,无需修改模型权重
- 在GPT-4中输入“以下是医疗咨询,请用专业术语回答”的软提示,可使其在不微调的情况下提升医疗问答准确率22%。
- Adapters
参考内容: 为什么神经网络会存在灾难性遗忘(catastrophic forgetting)这个问题? - 知乎 (zhihu.com)

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)