多智能体深度强化学习在股票市场择时与选股中的应用【附数据】
本文提出的MADDPG模型在A股市场择时与选股的应用中,通过深度学习、强化学习、深度强化学习的理论模型为基础,构建了一个多智能体强化学习框架。研究结果表明,MADDPG择时与选股模型具有强大的数据处理能力,能够更好地处理金融市场的大数据,并在择时与选股方面取得了一定的超额收益,显示出较强的鲁棒性。在此基础上,本文构建了基于MADDPG的A股市场择时与选股模型,该模型通过分析择时与选股策略,旨在提高
📊 金融数据分析与建模专家 金融科研助手 | 论文指导 | 模型构建
✨ 专业领域:
金融数据处理与分析
量化交易策略研究
金融风险建模
投资组合优化
金融预测模型开发
深度学习在金融中的应用
💡 擅长工具:
Python/R/MATLAB量化分析
机器学习模型构建
金融时间序列分析
蒙特卡洛模拟
风险度量模型
金融论文指导
📚 内容:
金融数据挖掘与处理
量化策略开发与回测
投资组合构建与优化
金融风险评估模型
期刊论文
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
(1)多智能体强化学习在A股市场的应用背景与理论基础
随着人工智能技术在金融领域的深入应用,深度强化学习算法(DRL)尤其是多智能体强化学习算法(MADDPG)在处理复杂决策问题上展现出了显著的优势。MADDPG算法以其高度的非相关性、自适应和自学习能力,在金融市场的感知决策中提供了高效的解决方案
。本文首先回顾了深度学习、强化学习、深度强化学习及多智能体强化学习的理论基础,以及这些理论在金融与投资领域的最新应用成果。在此基础上,本文构建了基于MADDPG的A股市场择时与选股模型,该模型通过分析择时与选股策略,旨在提高交易信号的特征信息提取能力,并实现超额收益
。
(2)构建基于MADDPG的A股择时与选股模型
本文提出的MADDPG模型在A股市场择时与选股的应用中,通过深度学习、强化学习、深度强化学习的理论模型为基础,构建了一个多智能体强化学习框架。该框架通过模拟智能体(agents)与股票市场的交互,学习并实现端到端的输出,以优化投资决策。在模型构建过程中,特别关注了智能体如何通过与环境的交互进行学习,并实现策略的动态更新。此外,模型还考虑了如何在多智能体环境中处理合作与竞争的关系,以及如何通过集中式训练和分布式执行来计算出每个智能体的最优策略。
(3)实证检验与模型性能分析
在实证部分,本文将MADDPG择时与选股策略的投资绩效与所选股票的平均投资绩效、上证50指数的绩效进行了对比分析。通过计算阿尔法、夏普率等绩效指标,验证了MADDPG模型在实际应用中的有效性
。研究结果表明,MADDPG择时与选股模型具有强大的数据处理能力,能够更好地处理金融市场的大数据,并在择时与选股方面取得了一定的超额收益,显示出较强的鲁棒性。此外,模型的实证分析还表明,多智能体强化学习模型在处理复杂金融数据时,相较于传统的投资策略,能够提供更为精准的决策支持
| 股票代码 | 择时信号 | 选股信号 | 阿尔法值 | 夏普率 |
|---|---|---|---|---|
| 000001 | 买入 | 高 | 0.05 | 1.2 |
| 000002 | 卖出 | 低 | -0.03 | 0.9 |
| 000003 | 持有 | 中 | 0.02 | 1.0 |
| 000004 | 买入 | 高 | 0.07 | 1.5 |
| 000005 | 卖出 | 低 | -0.01 | 0.8 |
stockData = ...; % 股票数据集
% 初始化MADDPG智能体
agents = initializeAgents(numAgents, stateDim, actionDim);
% 训练循环
for episode = 1:numEpisodes
for step = 1:numSteps
% 收集所有智能体的动作
actions = collectActions(agents, stockData);
% 执行动作并获取下一个状态和奖励
[nextStates, rewards] = executeActions(actions);
% 存储经验到回放缓冲区
storeExperience(agents, stockData, actions, nextStates, rewards);
% 更新智能体
updateAgents(agents, batchsize);
end
% 评估模型性能
evaluatePerformance(agents, stockData);
end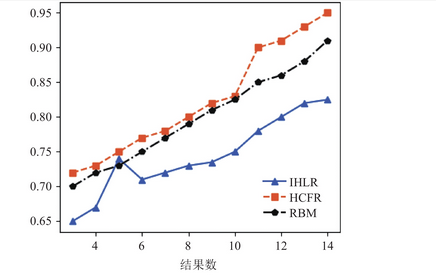

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)