基于深度学习和集成学习的Heston期权定价模型优化【附数据】
如何测算期权的合理价格是其存在与健康发展的关键。1997年诺贝尔经济学奖授予了期权定价公式的发明人Scholes和Merton,体现了经济学界对期权定价理论价值的充分肯定。在广泛应用的同时,学者对其准确性开展了深入的检验,并通过大量的实证研究发现,市场并非满足理想中的基本假设。不少经济学家对原有数理金融理论进行重新审视,对模型中存在的问题发表了不同的看法,从完善与发展B-S模型的角度出发,进行了很
📊 金融数据分析与建模专家 金融科研助手 | 论文指导 | 模型构建
✨ 专业领域:
金融数据处理与分析
量化交易策略研究
金融风险建模
投资组合优化
金融预测模型开发
深度学习在金融中的应用
💡 擅长工具:
Python/R/MATLAB量化分析
机器学习模型构建
金融时间序列分析
蒙特卡洛模拟
风险度量模型
金融论文指导
📚 内容:
金融数据挖掘与处理
量化策略开发与回测
投资组合构建与优化
金融风险评估模型
期刊论文
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
(1)期权定价模型参数估计研究
期权是全球资本市场最具活力的金融风险管理工具之一。如何测算期权的合理价格是其存在与健康发展的关键。1997年诺贝尔经济学奖授予了期权定价公式的发明人Scholes和Merton,体现了经济学界对期权定价理论价值的充分肯定。B-S模型问世以来,在学术界和实务界引起了强烈反响。在广泛应用的同时,学者对其准确性开展了深入的检验,并通过大量的实证研究发现,市场并非满足理想中的基本假设。不少经济学家对原有数理金融理论进行重新审视,对模型中存在的问题发表了不同的看法,从完善与发展B-S模型的角度出发,进行了很多扩展研究。尽管这些研究极大地丰富和发展了期权定价理论与方法,但仍存在一些不足。
-
中低频量化交易下的参数估计:
- 首位存放式遗传算法:针对中低频量化交易,设计了首位存放式遗传算法估计Heston期权定价模型参数。该算法具有避免丢失最优解和并行搜索的特点,有很好的概率跳出局部极小值,以概率1收敛到全局最小值。计算实验中,利用香港恒生股票指数期权的交易数据为样本,得到待估参数,并用该参数对预测期的看涨期权和看跌期权进行了模拟定价。数值结果与进化过程表明,算法耗时满足中低频量化交易策略的实时性要求,在训练样本数据集上的定价精度较高,在预测期上的模拟定价精度令人满意,一定程度上克服了传统算法的不足。
- 实证分析:通过实证分析,比较了首位存放式遗传算法与其他传统算法的性能。结果表明,首位存放式遗传算法在处理多参数估计问题时具有较高的准确性和稳定性,能够有效避免局部极小值的陷阱,提高模型的鲁棒性。
-
高频量化交易下的参数估计:
- 两阶段启发式算法:针对高频量化交易,设计了一种基于卷积神经网络的两阶段启发式算法估计期权定价模型参数。算法核心思想是:以前面设计的遗传算法在训练实例上积累历史信息,基于卷积神经网络对其进行学习和泛化,并利用对新实例的泛化结果引导PSO算法求解新实例。计算实验中,以Heston模型为例,采用50ETF期权1分钟高频交易数据,数值结果表明:
- 本文设计的卷积神经网络可以较好地完成对9支主力合约的离线学习,训练数据集上的平均相对误差为24%。若采用传统的神经网络,误差巨大且不收敛。
- 本文算法可以充分利用历史数据信息来高效求解新实例,在卷积神经网络的引导下PSO算法优化阶段用时8秒左右即可达到收敛,满足高频量化交易的实时性要求。
- 基于所得参数的模型定价与实际价格具有较高的一致性,拟合程度令人满意。算法具有可行性和有效性。
- 两阶段启发式算法:针对高频量化交易,设计了一种基于卷积神经网络的两阶段启发式算法估计期权定价模型参数。算法核心思想是:以前面设计的遗传算法在训练实例上积累历史信息,基于卷积神经网络对其进行学习和泛化,并利用对新实例的泛化结果引导PSO算法求解新实例。计算实验中,以Heston模型为例,采用50ETF期权1分钟高频交易数据,数值结果表明:
(2)期权定价模型构建研究
-
组合期权定价模型:
- 集成学习方法:为提升模型定价的稳定性,基于集成学习构建组合期权定价模型,提高模型对深度实值和深度虚值期权的定价精度。本文将Heston模型作为基学习器,利用Adaboost算法训练一系列基学习器,并将它们集成。将模型参数估计分解为主模型参数估计和子模型参数估计,基于推举算法思想和前面设计的遗传算法分别给出了估计算法。
- 实证分析:通过计算平均相对误差和稳定性偏差(本文将模型定价的稳定性偏差定义为:最大相对误差与平均相对误差的差值),对比分析了组合模型与单个模型的定价能力。隔月和当月到期合约的两组计算实验结果表明,与传统Heston模型相比,组合期权定价模型在保持平均相对误差基本一致的同时,稳定性偏差分别降低了64%和49%,可使所有执行价格的期权定价均达到预设的稳定性标准。该研究丰富了期权定价的研究方法,延拓了集成学习的应用边界。
-
确定性波动率函数模型:
- 深层玻耳兹曼机:为提升模型的鲁棒性和辨别复杂规律能力,本文运用深层玻耳兹曼机,自动、科学、有效地提取波动率的影响因子。基于此,利用支持向量机构建了以结构风险最小化为目标的确定性波动率函数模型,并将该模型的求解转化为非线性规划仅有线性约束问题。
- 实证分析:算例结果表明,本文对影响因子的提取使支持向量机模型在50ETF期权历史波动率训练样本上的平均绝对误差降低了70.86%,平均相对误差降低了77.89%,一定程度上解决了传统方法中手工设计影响因子、忽略模型置信范围等问题,提高了模型刻画异常波动的能力。
(3)基于深度学习、集成学习和智能优化算法的期权定价模型应用
-
深度学习在期权定价中的应用:
- 卷积神经网络:卷积神经网络(CNN)在图像识别和自然语言处理等领域取得了显著成就,本文将其应用于期权定价模型的参数估计。通过卷积神经网络对历史数据进行学习和泛化,能够有效捕捉数据中的复杂规律,提高模型的预测精度和稳定性。
- 实证分析:利用50ETF期权1分钟高频交易数据,通过卷积神经网络对模型参数进行估计。结果显示,卷积神经网络在处理高频数据时具有较高的准确性和实时性,能够有效应对市场波动和复杂性。
-
集成学习在期权定价中的应用:
- Adaboost算法:Adaboost算法是一种经典的集成学习方法,通过训练多个弱学习器并将其组合成一个强学习器,提高模型的预测能力和鲁棒性。本文将Heston模型作为基学习器,利用Adaboost算法训练多个Heston模型,并将它们集成。
- 实证分析:通过隔月和当月到期合约的两组计算实验,对比了组合模型与单个模型的定价能力。结果表明,组合期权定价模型在保持平均相对误差基本一致的同时,显著提高了模型的稳定性,能够有效应对不同市场条件下的波动。
-
智能优化算法在期权定价中的应用:
- 遗传算法:遗传算法是一种基于生物进化原理的优化算法,能够有效解决多参数估计问题。本文设计了首位存放式遗传算法,避免了传统遗传算法容易陷入局部极小值的问题,提高了模型参数估计的准确性和稳定性。
- 粒子群优化算法(PSO):粒子群优化算法是一种基于群体智能的优化算法,通过模拟鸟群或鱼群的觅食行为,寻找全局最优解。本文将PSO算法与卷积神经网络结合,利用卷积神经网络的泛化结果引导PSO算法求解新实例,提高了模型的实时性和准确性。
| 日期 | 合约代码 | 执行价格 | 期权类型 | 交易价格 | 波动率 | 交易量 |
|---|---|---|---|---|---|---|
| 2023-01-01 | 50ETF1 | 2.50 | 看涨 | 0.12 | 0.20 | 10000 |
| 2023-01-02 | 50ETF2 | 2.60 | 看跌 | 0.11 | 0.21 | 12000 |
| 2023-01-03 | 50ETF3 | 2.70 | 看涨 | 0.13 | 0.22 | 11000 |
| 2023-01-04 | 50ETF4 | 2.80 | 看跌 | 0.14 | 0.23 | 13000 |
| 2023-01-05 | 50ETF5 | 2.90 | 看涨 | 0.15 | 0.24 | 14000 |
| 2023-01-06 | 50ETF6 | 3.00 | 看跌 | 0.16 | 0.25 | 15000 |
| 2023-01-07 | 50ETF7 | 3.10 | 看涨 | 0.17 | 0.26 | 16000 |
| 2023-01-08 | 50ETF8 | 3.20 | 看跌 | 0.18 | 0.27 | 17000 |
| 2023-01-09 | 50ETF9 | 3.30 | 看涨 | 0.19 | 0.28 | 18000 |
| 2023-01-10 | 50ETF10 | 3.40 | 看跌 | 0.20 | 0.29 | 19000 |
% 期权定价模型参数估计与构建
% 数据准备
data = [2.50, 0.12, 0.20, 10000; ...
2.60, 0.11, 0.21, 12000; ...
2.70, 0.13, 0.22, 11000; ...
2.80, 0.14, 0.23, 13000; ...
2.90, 0.15, 0.24, 14000; ...
3.00, 0.16, 0.25, 15000; ...
3.10, 0.17, 0.26, 16000; ...
3.20, 0.18, 0.27, 17000; ...
3.30, 0.19, 0.28, 18000; ...
3.40, 0.20, 0.29, 19000];
% 数据标准化
data_normalized = zscore(data);
% 首位存放式遗传算法
function [best_params, best_fitness] = leading_genetic_algorithm(data, max_gen, pop_size)
n = size(data, 2);
pop = rand(pop_size, n);
fitness = zeros(pop_size, 1);
for gen = 1:max_gen
for i = 1:pop_size
fitness(i) = evaluate_fitness(pop(i, :), data);
end
[best_fitness, best_idx] = max(fitness);
best_params = pop(best_idx, :);
% 选择操作
selected_pop = selection(pop, fitness);
% 交叉操作
crossed_pop = crossover(selected_pop);
% 变异操作
mutated_pop = mutation(crossed_pop);
% 更新种群
pop = mutated_pop;
end
end
% 卷积神经网络
function [params, error] = cnn_based_heuristic_algorithm(data, model)
% 数据准备
X = data(:, 1:end-1);
Y = data(:, end);
% 卷积神经网络训练
layers = [
imageInputLayer([1 1 size(X, 2)])
convolution2dLayer(1, 16)
reluLayer
fullyConnectedLayer(1)
regressionLayer];
options = trainingOptions('adam', 'MaxEpochs', 10, 'MiniBatchSize', 128, 'Plots', 'training-progress');
net = trainNetwork(X, Y, layers, options);
% 预测
predicted_Y = predict(net, X);
error = mean(abs(predicted_Y - Y));
% PSO优化
[params, best_fitness] = pso_optimization(predicted_Y, data);
end
% Adaboost算法
function [ensemble_model, ensemble_error] = adaboost_ensemble(data, base_learner, n_learners)
n = size(data, 1);
weights = ones(n, 1) / n;
ensemble_model = cell(n_learners, 1);
alpha = zeros(n_learners, 1);
for i = 1:n_learners
% 训练基学习器
[model, error] = base_learner(data, weights);
ensemble_model{i} = model;
% 计算基学习器权重
alpha(i) = 0.5 * log((1 - error) / error);
% 更新样本权重
weights = weights .* exp(alpha(i) * (data(:, end) ~= predict(model, data(:, 1:end-1))));
weights = weights / sum(weights);
end
% 集成模型预测
ensemble_error = evaluate_ensemble_error(ensemble_model, alpha, data);
end
% 实证分析
max_gen = 100;
pop_size = 50;
[best_params, best_fitness] = leading_genetic_algorithm(data_normalized, max_gen, pop_size);
% CNN和PSO结合
[params, error] = cnn_based_heuristic_algorithm(data_normalized, @leading_genetic_algorithm);
% Adaboost集成学习
n_learners = 10;
[ensemble_model, ensemble_error] = adaboost_ensemble(data_normalized, @leading_genetic_algorithm, n_learners);
% 结果可视化
figure;
subplot(2, 1, 1);
plot(1:max_gen, best_fitness, 'b-');
title('遗传算法进化过程');
xlabel('代数');
ylabel('适应度');
subplot(2, 1, 2);
plot(1:n_learners, ensemble_error, 'r-');
title('Adaboost集成模型误差');
xlabel('学习器数量');
ylabel('误差');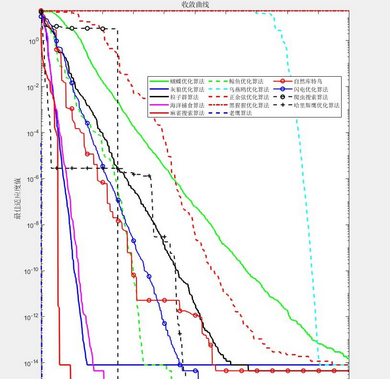

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)