一文读懂LLM智能体:定义、方法与应用前景(建议收藏)
本文系统综述了基于大型语言模型(LLM)的智能体,将其视为通往通用人工智能的潜在路径。文章详细阐述了LLM智能体的定义、核心组件(规划、记忆、反思等)、与强化学习智能体的对比,以及单智能体和多智能体系统的架构。同时介绍了主流数据集、基准测试,探讨了在自然科学、工程系统等领域的应用前景,并分析了LLM固有约束、安全信任等挑战及持续学习、多模态融合等发展趋势。
1. 概括
该综述聚焦基于大型语言模型(LLM)的智能体,将其视为通往通用人工智能(AGI)的潜在路径,系统梳理了单智能体与多智能体系统的定义、研究框架及核心组件(如规划、记忆、反思、工具使用、环境交互),对比了LLM-based智能体与强化学习(RL)智能体的优劣,阐述了多智能体系统中角色协作、消息传递及通信效率提升策略,介绍了主流数据集与基准测试,详细探讨了其在自然科学、社会科学、工程系统等领域的应用前景,同时指出LLM固有约束、动态扩展、安全信任等挑战,并展望了持续学习、多模态融合等发展趋势。
2. 思维导图

3. 详细总结
一、研究背景与智能体基础
- 智能体定义与定位
智能体是能从环境中感知信息并执行动作的实体,是实现人工通用智能(AGI) 的潜在路径,核心特征包括自主性(独立决策)、感知能力(传感器采集信息)、决策能力(基于感知选动作)、动作能力(改变环境状态)。 - 智能体分类
根据功能与决策逻辑,智能体分为5类:
- 简单反射型(基于当前感知直接反应)
- 基于模型反射型(结合环境模型决策)
- 目标导向型(以达成目标为核心)
- 效用导向型(追求效用最大化)
- 学习型(通过经验改进行为):RL-based智能体与LLM-based智能体均属于此类。
- LLM-based智能体的兴起
- RL-based智能体局限:训练时间长(需大量环境探索)、样本效率低(高计算成本)、稳定性差(高维函数逼近易振荡)、泛化性弱(仅适配特定任务)。
- LLM的优势与不足:擅长自然语言处理(推理、问答、编程),但存在上下文长度约束(易忽略中间文本)、知识更新慢(训练迭代耗资源)、无法直接用工具的问题。
- LLM-based智能体优势:① 强大的自然语言处理与知识储备(覆盖常识与领域知识);② 零样本/少样本学习(新任务需少量样本);③ 自然的人机交互(自然语言接口)。
二、LLM-based智能体系统框架
(一)单智能体系统
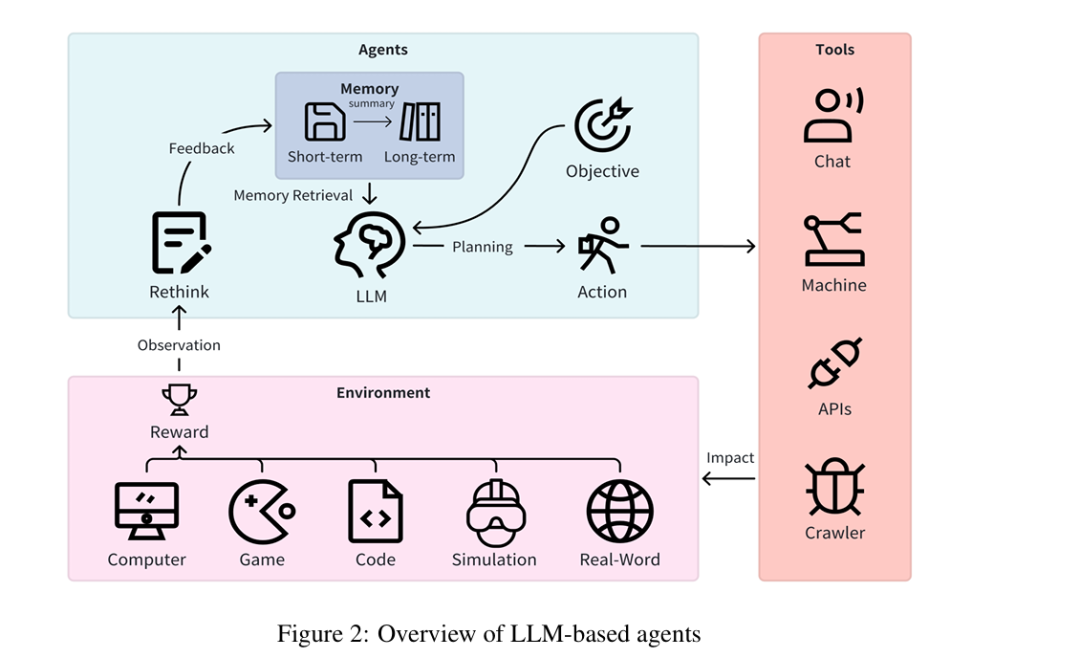
- 核心组件(五要素模型 (V=(L, O, M, A, R)))
| 组件 | 定义与功能 | 关键技术/示例 |
|---|---|---|
| LLM(L) | 认知核心,负责任务规划与决策,基于观察、记忆、奖励信息工作 | 动态调整温度参数,无需额外训练 |
| 目标(O) | 智能体需达成的终端状态,需基于目标进行任务分解 | 代码生成、游戏探索等具体任务目标 |
| 记忆(M) | 存储信息与当前状态,记录动作后的环境反馈与奖励 | 短期记忆(对话历史)、长期记忆(知识图谱) |
| 动作(A) | 智能体可执行的操作,包括使用工具、开发新工具、传递消息 | 调用API、使用计算器、控制机器人臂 |
| 反思(R) | 评估前序动作与环境反馈,整合记忆与LLM优化后续动作 | ReAct(交互推理+动作)、Reflexion(自我反思) |
- 外部组件
- 工具:智能体可调用的外部工具,如计算器、SQL执行器、代码解释器、机器人臂等,典型案例包括ToolFormer(LLM自主选工具)、HuggingGPT(集成多AI模型工具)。
- 环境:智能体交互的场景,分为5类:
| 环境类型 | 交互方式 | 典型案例 |
|---|---|---|
| 计算机环境 | 网页爬取、API调用、网页搜索、数据库查询 | WebGPT(搜索辅助问答)、SheetCopilot(表格交互) |
| 游戏环境 | 角色控制、环境交互、状态感知 | Voyager(Minecraft探索)、DECKARD(任务设计) |
| 代码环境 | 代码生成、调试、评估 | GPT-Engineer(生成代码库)、MetaGPT(协作编程) |
| 现实环境 | 数据采集(传感器)、设备控制(执行器)、人机交互 | TaPA(实体任务规划)、Di Palo等(机器人操作) |
| 仿真环境 | 模型操控、数据分析、优化 | TrafficGPT(交通仿真)、AucArena(拍卖仿真) |
- 核心能力实现
-
上下文学习:ReAct(交替生成推理与动作)、Reflexion(计算启发式判断环境重置)。
-
监督学习:CoH(基于反馈的序列优化)、Process Supervision(过程监督优于结果监督)。
-
强化学习:Retroformer(从回顾模型学习)、REMEMBER(强化学习+经验记忆更新)。
-
短期记忆:依赖LLM上下文窗口,存储当前任务相关信息(如ChatDev的对话历史)。
-
长期记忆:通过外部存储扩展,如知识图谱(存储实体关系)、向量数据库(高效检索)、MemGPT(管理多记忆层级)。
-
记忆检索:基于检索增强生成(RAG),结合外部知识库提升输出可靠性(如LaGR-SEQ的样本高效查询)。
-
上下文学习(ICL):如Chain of Thought(CoT)(拆解复杂任务)、Tree of Thought(ToT)(树状思维探索)、Self-consistency(多推理路径投票)。
-
外部方法:如LLM+P(结合经典规划器与PDDL语言)、LLM-DP(LLM+符号规划器解决实体任务)。
-
多阶段方法:如SwiftSage(快速直觉思考+审慎思考)、DECKARD(Dreaming分解子目标+Awake验证策略)。
-
规划能力:将目标分解为动作序列,方法分为三类:
-
记忆能力:
-
反思能力:通过评估与反馈优化行为,方法包括:
(二)多智能体系统(MAS)
- 核心特征与分类
多智能体系统由多个交互的智能体组成,擅长跨领域复杂任务,关键分类维度包括:
- 角色关系:协作型(如Generative Agents模拟人类协作)、竞争型(如Liang等的多智能体辩论)、混合型(如Werewolf游戏中的合作与背叛)、层级型(如AutoGen的任务分解)。
- 规划类型:
| 规划类型 | 定义 | 优势 | 不足 |
|---|---|---|---|
| 集中规划分散执行(CPDE) | 中央LLM负责规划,各智能体独立执行 | 全局优化,协调高效 | 计算复杂,单点故障风险高 |
| 分散规划分散执行(DPDE) | 各智能体独立规划,通过通信 | 鲁棒性强,适应动态环境 | 难达全局最优,通信开销大 |
- 通信机制与效率提升
- 信息交换方式:无通信(仅依赖本地信息)、有通信(消息传递)、共享内存(中央知识库如MetaGPT的全局内存池、共享参数)。
- 通信效率提升策略:
- 设计通信协议:定义消息语义、语法(如KQML、FIPA-ACL)、交互协议(对话结构)。
- 引入中介模型:判断智能体交互必要性,减少冗余通信(如Hu等的成本优化交互)。
- 抑制LLM无效输出:如CoVe(生成验证问题修正输出)、合成数据微调减少谄媚输出。
三、性能评估
(一)关键数据集
| 数据集名称 | 领域 | 核心内容与规模 |
|---|---|---|
| HotpotQA | NLP | 多跳问答,含11.4万训练样本、7千开发样本、3千测试样本 |
| CAMEL | 社会/代码 | 社会对话:50个助手角色+50个用户角色+10个任务=2.5万对话;代码对话:20种语言+50个领域=5万对话 |
| APPS | 编程 | 1万道编程题,覆盖不同难度 |
| HumanEval | 编程 | 164道原创编程题,评估语言理解与算法能力 |
| ToolBench | 工具使用 | 1.6万+真实RESTful API,含单工具与多工具场景 |
| MITCOURSE ES | 数学 | 7门课程(微积分、线性代数等),每门25道题 |
(二)主流基准测试
- ToolBench:工具使用评估,覆盖49类API场景。
- AgentSims:开源评估平台,模拟虚拟城镇等场景,测试规划与决策能力。
- AgentBench:综合评估智能体基础能力,包括工具使用、记忆、推理等。
- SmartPlay:6类游戏场景,20种评估配置,测试环境适应能力。
- MLAgentBench:机器学习任务基准,支持文件读写、代码执行等操作。
四、应用前景
(一)自然科学
- 数学:Math Agents探索数学问题、LeanDojo辅助定理证明、ToRA结合工具解决复杂数学问题。
- 化学与材料:Coscientist自主设计化学实验、ChatMOF预测生成MOF、ChemCrow访问化学数据库加速研究。
- 生物学:BioPlanner评估生物实验规划、OceanGPT生成海洋科学数据、模拟生态系统与分子机制。
- 气候科学:Kraus等用LLM提取ClimateWatch排放数据、模拟气候系统预测大气现象。
(二)通用自主智能体
- 通用任务助手:HuggingGPT(集成多AI模型)、AutoGPT(自动分解目标)、BabyAGI(任务生成与存储)。
- 工作/研究助手:GPT Researcher(生成研究报告)、Boiko等的智能体自主设计科学实验、MemWalker(长文本阅读交互)。
(三)社会科学与工程系统
| 领域 | 典型应用 |
|---|---|
| 经济学与金融 | Horton对比LLM与人类经济行为、TradingGPT的分层记忆提升交易决策、AucArena模拟拍卖 |
| 教育学 | AgentVerse模拟NLP课堂、CGMI模拟师生交互、Math Agents转换数学公式格式 |
| 机器人系统 | TaPA的实体任务规划、ProAgent的协作推理、RoCo的多机器人协作 |
| 医疗系统 | Williams等的流行病建模、AI-SCI评估临床任务能力、模拟药物发现与优化 |
五、发展趋势与挑战
- 趋势
- 标准化评估:建立基础能力(如推理、工具使用)与领域能力(如法律、医疗)的统一基准。
- 持续进化:实现持续学习(无灾难性遗忘)、自我评估与动态目标调整、环境适应性提升。
- 多模态融合:结合图像、语音等多模态信息,如GPT-4V、PALM-E的多模态任务处理。
- 挑战
- LLM固有约束:上下文长度有限、知识更新延迟、易产生幻觉。
- 动态扩展:系统需自适应调整规模与资源分配(如LLM级联降低成本)。
- 安全与信任:合理分配权限、测试可靠性(如ToolEmu模拟工具执行评估风险)。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 42
42 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)