【Agent专题】上下文工程:Context Engineering爆火!唤醒大模型“心智”,AI智能体落地的关键武器来了!
摘要: 随着大语言模型(LLM)能力的提升,**上下文工程(Context Engineering)**成为AI智能体开发的核心技术,由前特斯拉AI总监Andrej Karpathy提出并推动。上下文是LLM的“心智世界”,包含指令、知识、工具反馈和历史轨迹,决定模型的行为与认知边界。由于上下文窗口资源有限,需通过四大策略优化管理:写上下文(便签、记忆)、选上下文(动态检索关键信息)、压缩上下文(
随着大语言模型(LLM)能力的不断跃升,AI 智能体正在从纯对话系统迈向更复杂的多轮推理、多工具协同与长期任务执行。
而支撑这一演化的“幕后主角”,正是一个技术门槛日益提升的新领域:上下文工程(Context Engineering)。继 Vibe Coding(氛围编程)火了之后,AI圈又迎来一股新的技术热潮。
这一次,是由前特斯拉 AI 总监、深度学习布道者 Andrej Karpathy 亲自点燃的火。他在一次演讲中强调:“如果你想真正掌控一个大语言模型的行为,不是去微调权重,而是掌控它的‘心智世界’——你提供给它的上下文。”

在构建 AI 智能体的过程中,“上下文”不仅仅是几个提示词的组合,更是构成其“认知宇宙”的核心素材。它包含模型当前能“看到”的信息(如任务指令、外部知识、历史轨迹),也决定了模型“如何看到”(结构化与否)、“何时看到”(静态注入或动态更新)。
正如 Andrej Karpathy 所说:“LLM 是新的计算平台,模型本体就像 CPU,而上下文窗口就像 RAM。你无法重新训练模型每次适配具体任务,但你可以用上下文工程去控制它‘思考的材料’。”
于是,一个全新的工程范式被推上风口浪尖:****Context Engineering(上下文工程)。
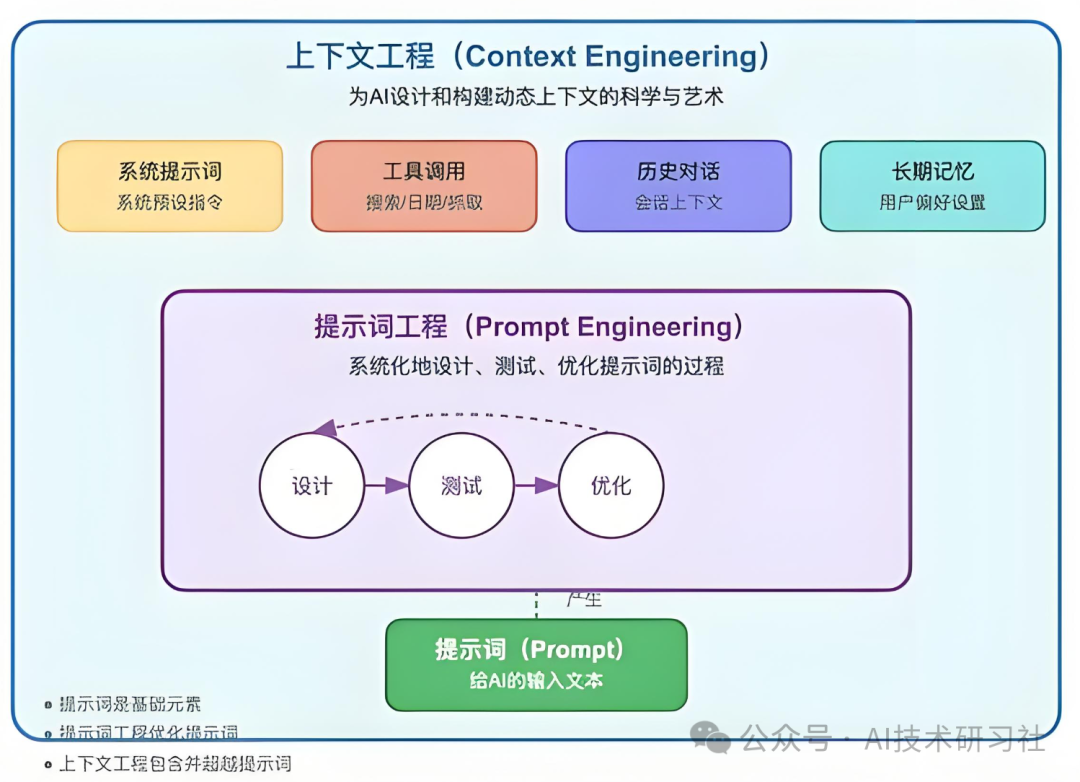


上下文工程是一门集艺术与科学于一体的学问,目标是高效填充 LLM 的上下文窗口,使其在每一步任务执行中都拥有“刚刚好”的信息量。它不仅涉及信息的选择、组织与注入方式,还关注上下文的动态性、可扩展性与准确性。
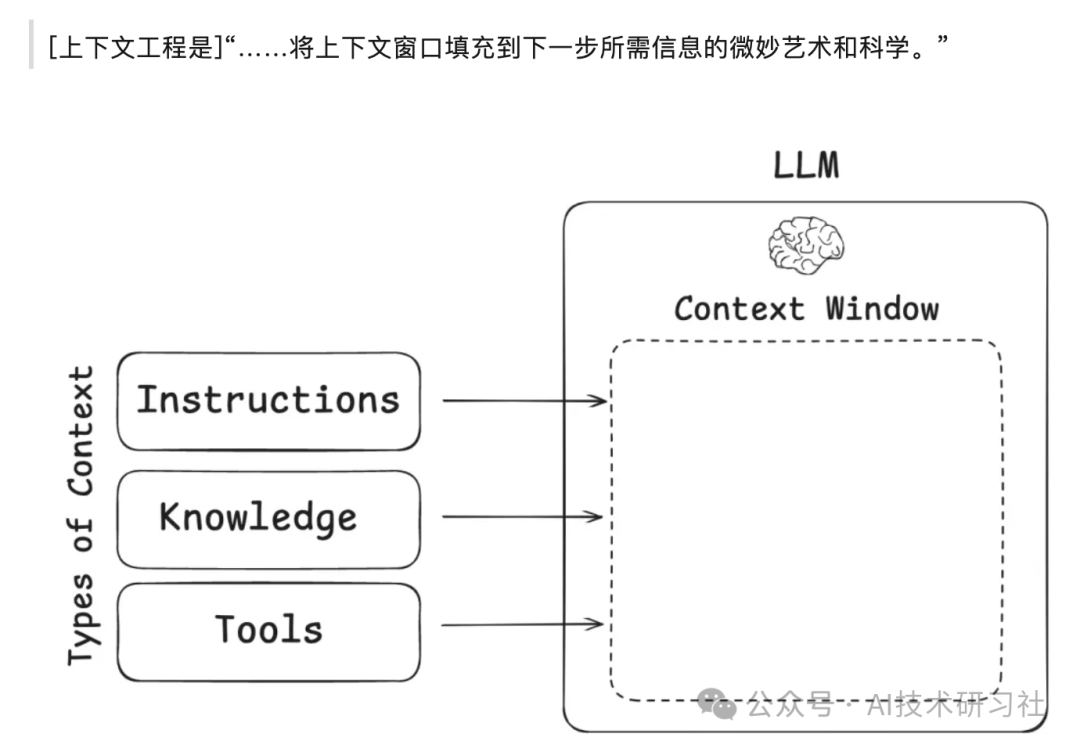
具体而言,构建 AI 智能体过程中所涉及的上下文类型包括:
- 指令:提示词、少样本示例、工具描述、系统角色设定等;
- 知识:结构化事实、外部知识库(通过RAG注入)或语义记忆;
- 工具反馈:函数调用、API 返回值、插件响应等多模态中间结果;
- 历史轨迹:对话上下文、用户输入记录、策略路径等。
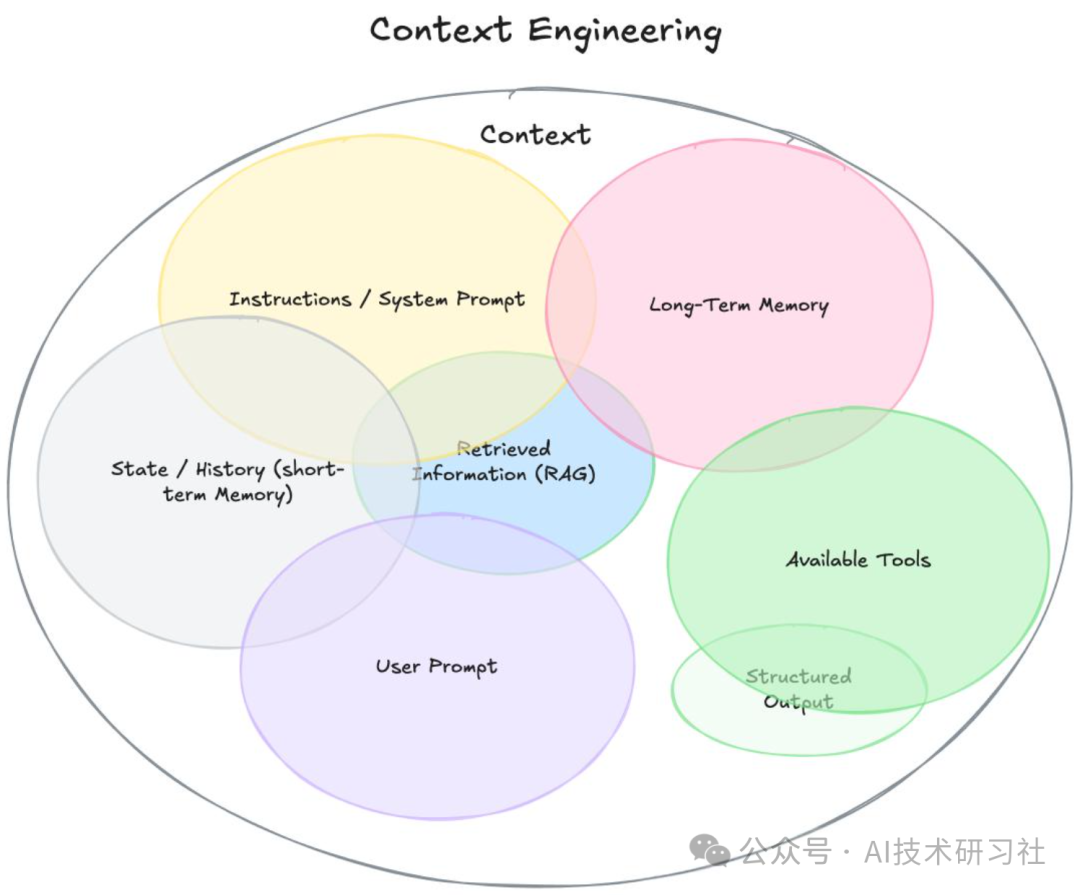
由于 LLM 的上下文窗口资源有限(即使扩展至百万 tokens 也依旧存在边界),不加选择地注入上下文将导致成本上升、响应延迟、性能退化甚至幻觉增强。因此,对上下文的管理与设计,必须借助系统化策略。
四大上下文工程策略详解:写、选、压缩、隔离。
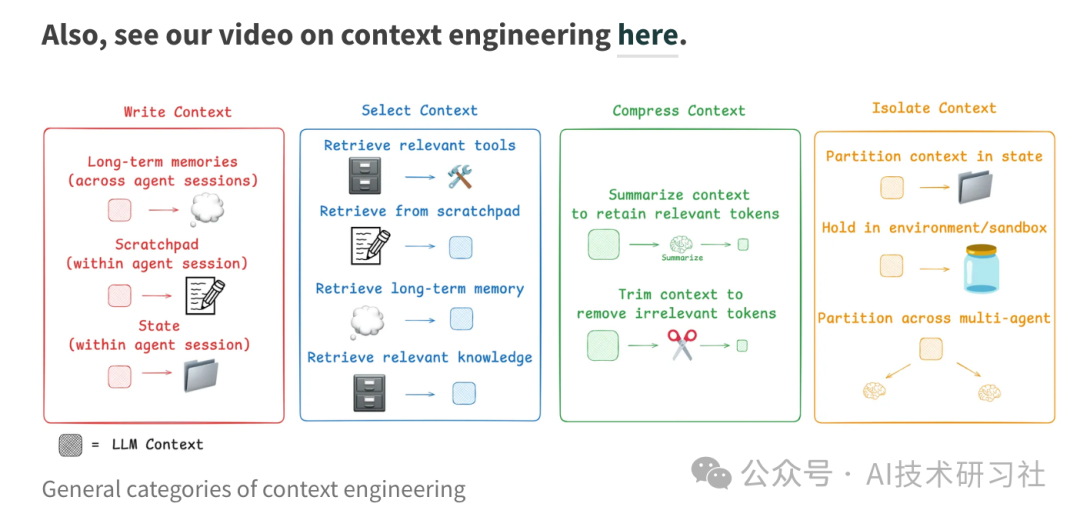
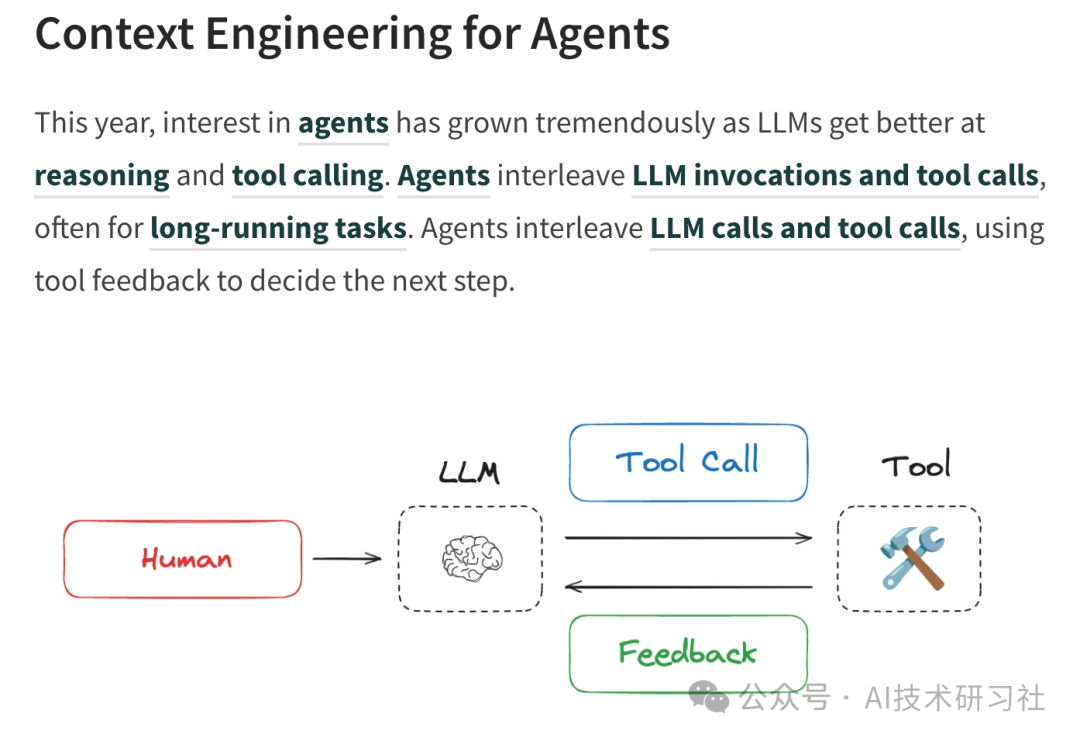
1. 写上下文(Write Context)
写上下文是指将关键任务信息保存在上下文窗口之外,但又可被模型间接利用的手段,类似人类“写便签”、“做笔记”的行为。
-
便签(Scratchpads):Anthropic 提出的研究显示,AI 智能体通过工具调用或状态字段记录计划信息,可帮助其在任务过程中持久化策略、参数或状态。例如,研究人员将超过 20 万 tokens 的长任务拆解为阶段性步骤,并通过便签记录每一阶段决策,从而避免窗口溢出。
-
记忆(Memory):指 AI 智能体自动从多轮历史对话中提取高价值事实(语义记忆)、行为流程(程序记忆)、案例轨迹(情景记忆)并长期保留。这一机制已被 ChatGPT、Cursor、Windsurf 等集成,用于实现“个性化响应”。如 ChatGPT 能记住用户的写作风格和工作场景,并在未来会话中主动融合。
2. 选上下文(Select Context)
选上下文是将最相关的信息拉入当前上下文窗口。它是上下文工程中最典型的动态部分,涵盖便签、记忆、工具与知识四种维度:
-
记忆选择:如 Claude Code 使用 CLAUDE.md 文件、Cursor 使用 config rules,用于提供始终注入的规则性知识。对于海量语义记忆,ChatGPT 结合知识图谱与向量索引过滤调用内容,但仍存在“意外注入”问题(如 Simon Willison 遭遇 AI 自动泄露位置信息)。

-
工具选择:大模型面对多种工具时,可能会因描述相似产生混淆。RAG-MCP 架构通过将工具说明索引入库,仅检索任务相关的工具描述,实验证明工具选择准确率提高 3 倍。
-
知识选择(RAG):以 Windsurf 为例,其代码 RAG 架构并非简单做文本嵌入,而是结合 AST 分块、语义重排、多源索引等手段,在千万行代码中快速定位任务相关逻辑模块,从而大幅提升智能体响应的专业度。
3. 压缩上下文(Compress Context)
压缩上下文用于精简冗余 tokens,通过“摘要”和“修剪”两类方式实现:
-
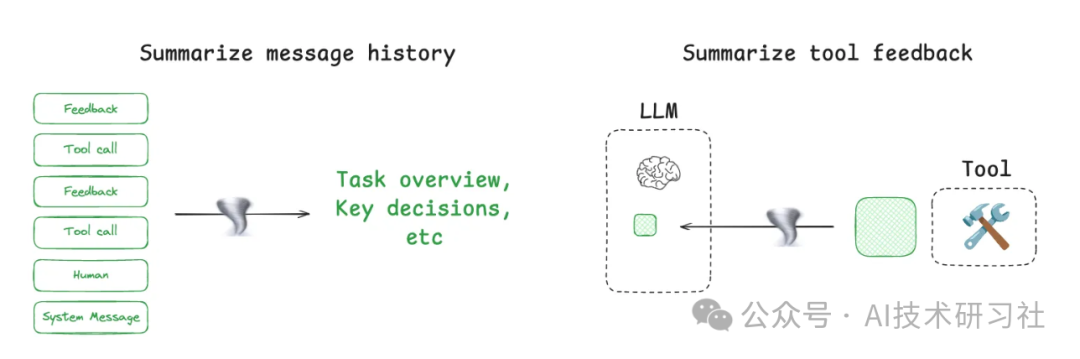
上下文摘要(Summarization):Claude Code 在上下文窗口使用率达到 95% 后会自动对对话轨迹进行总结,再替代注入。这种方式可以采用递归摘要、层次摘要等策略,也可以训练微调模型用于关键事件提取。
-
上下文修剪(Trimming):使用规则剔除老旧、无效或冲突上下文。例如清除最早回合信息、剔除中间无关路径等。这种策略操作简便,在工具调用频繁或成本敏感场景中尤为常用。
4. 隔离上下文(Isolate Context)
隔离上下文是将任务上下文拆分为多个“独立空间”,实现多 Agent 协作、环境分区或状态模块化:
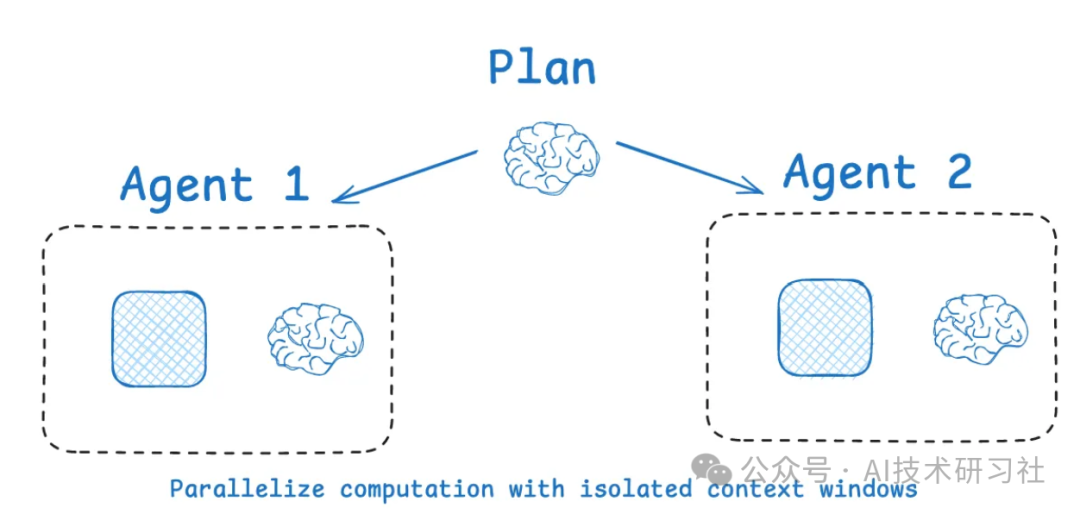
- 多智能体架构(Multi-Agent):如 OpenAI Swarm 和 Anthropic 多智能体团队研究,每个子 Agent 管理自己的上下文、工具与指令,适用于分布式复杂任务。实验显示,相较单体 Agent,这种模式响应准确率显著提高,尽管 token 使用量高达单 Agent 的 15 倍。
- 环境隔离(Environment Isolation):Hugging Face CodeAgent 架构将代码工具执行放入沙箱环境,工具调用参数与返回值在沙箱中完成状态隔离,仅返回结果注入 LLM,从而防止上下文污染。
- 运行时状态对象(State Object):以 LangGraph 为例,系统状态由结构化字段组成。开发者可精确控制哪些字段在每步注入模型,哪些信息保持隔离,仅在特定回合暴露,从而实现“动态上下文管理”。
上下文工程已逐步成为 AI 智能体设计的核心工程分支。无论是 Anthropic 的研究,OpenAI 的产品落地,还是 LangChain/LangGraph 等开发框架的演进,都在强调一个趋势:
上下文,不只是提示词,它是智能体的“工作内存”、“知识总线”与“行为约束”。
未来,随着工具生态扩张、多模态输入爆发与任务持续增长,AI 智能体的上下文管理将走向更自动化、更智能、更语义化。
Context Engineering 将从人工手工选择,进化为“智能上下文调度器”,成为每一个 AI 开发者的核心能力之一。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)