随机森林结合大模型处理医疗表格数据,实现高精度建模搭配大模型医学文本归因(19.5)
一、前言
做医疗数据分析、AI辅助诊断应该都会遇到两个非常棘手的问题:一是纯表格结构化病历数据,只用大模型直接训练精度拉胯,数值、检验指标、分级特征很难被大模型精准捕捉;二是传统机器学习像随机森林,分类准确率足够高,但永远是黑盒模型,医生拿到预测结果,完全看不懂模型凭哪些检验指标、病史特征判定患者高风险,没法用于临床诊疗落地。
很久以来两条技术路线一直是割裂的,容易只知其一不知其二的困境:
- 做结构化数据预测的工程师死磕树模型、传统机器学习,只追求指标精度;
- 做大模型应用的算法人员埋头微调模型、RAG,专攻文本生成、问答解读,二者很少结合落地。
但医疗场景有硬性合规要求,不仅要AI给出诊断分类结果,还必须输出符合医学规范、通俗易懂的归因解释,缺一不可。从业这么久了,很多问题找不到方案的时候,就只能自己尝试着结合突破局限,构建新的解决方案,今天就做个简单的总结和思路的整理,供大家参考;

二、基础概念
1. 医疗表格数据
1.1 定义与数据来源
医疗表格数据,指以二维表格形式存储、每条样本对应一位患者、每一列代表一项临床指标的结构化医疗数据,区别于CT影像、门诊病历自由文本、语音问诊这类非结构化医疗数据。
常见数据源包含三大类:
- 检验系统(LIS):血常规、肝肾功能、血糖血脂、肿瘤标志物等数值型指标,格式统一,全部为数字;
- 电子病历系统(EMR):年龄、性别、既往病史、手术史、吸烟饮酒史、疾病分级等分类离散特征;
- 随访数据库:复诊频次、并发症记录、用药时长、预后分级等有序类别特征。
单条患者样本会整合数十至上百项特征,比如糖尿病筛查数据集包含:年龄、BMI、空腹血糖、糖化血红蛋白、高血压病史、家族遗传史、甘油三酯、用药记录等多维度特征,最终建模目标是二分类/多分类任务,例如:是否确诊2型糖尿病、心脑血管疾病风险等级、肿瘤良恶性判定、术后并发症发生概率。
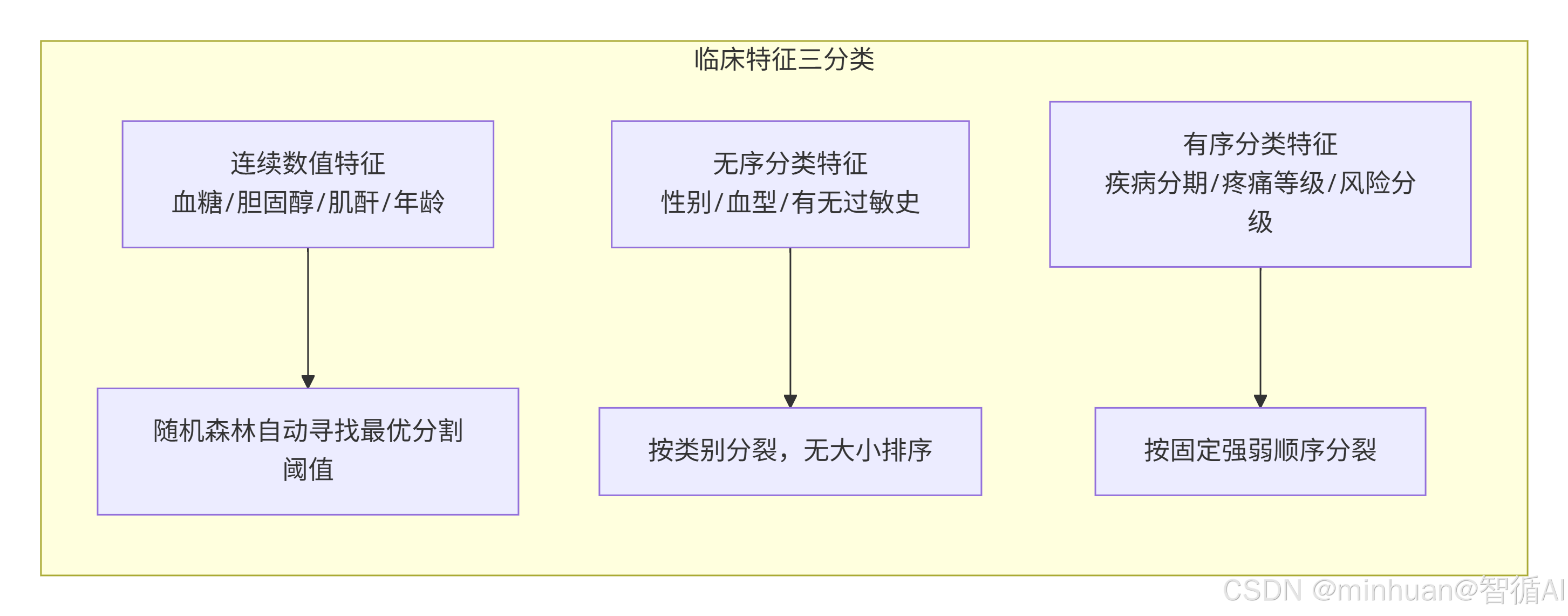
1.2 三大特征类型细分
表格内所有临床特征可划分为三类,不同特征适配随机森林的分裂逻辑,同时决定后续大模型归因解读逻辑:
- 连续数值特征:血糖、胆固醇、肌酐、年龄等连续变化数字,随机森林会自动寻找最优分割阈值;
- 无序分类特征:性别、血型、有无过敏史,无大小排序关系;
- 有序分类特征:疾病分期(Ⅰ/Ⅱ/Ⅲ 期)、疼痛等级、风险分级,存在固定强弱顺序。
1.3 纯表格医疗数据现存技术痛点
单独使用任意一类模型处理该数据,都会出现无法规避的短板,这也是我们需要随机森林与大模型融合的根本原因:
仅用原生大模型处理表格数据缺陷:
- 大模型原生适配文本序列输入,对纯数字表格缺乏天然建模能力。
- 若直接把表格转为文本投喂给模型,数值大小、特征权重、指标阈值会被模型忽略,特征之间的数值关联丢失,分类准确率大幅下滑;
- 同时大模型训练成本高,小样本医疗数据集极易出现过拟合。
仅用随机森林处理表格数据缺陷:
- 随机森林训练完成后具备极高分类精度,对数值、分类特征适配性极强,训练速度快、小样本容错性好,但属于典型黑盒模型。
- 虽然可以提取特征重要性数值,但只能输出一串数字权重,无法结合医学知识翻译成医生能看懂的专业自然语言,不满足医疗临床可解释合规要求;
- 无法自主结合医学常识补充解读,单纯权重数字无临床使用价值。
行业落地硬性约束:
- 医疗AI需满足卫健委可解释性规范,预测结果必须配套完整归因逻辑,单纯精度达标无法上线;
- 同时临床数据多为小样本、高缺失、特征多维度,单一模型很难同时兼顾精度、可解释、低成本训练三大需求。
2. 随机森林基础
2.1 基础定义
随机森林属于集成学习中Bagging 分支的树模型,由大量相互独立的决策树共同组成,最终分类结果由所有单棵决策树投票决定。简单通俗理解:把每一棵决策树比作一名单独的临床实习生,每一位实习生只观察部分患者、部分检验指标独立给出诊断结论,最后汇总所有实习生投票,得票最多的疾病判定为最终结果。
随机包含两层核心随机机制,也是它适配医疗数据的关键:
- 样本随机:每棵决策树训练时,从全部患者数据中有放回抽样,生成专属训练子集,规避单一样本分布带来的偏差;
- 特征随机:每一次树节点分裂时,仅随机选取部分临床指标寻找最优分割阈值,避免单一核心指标完全主导预测,提升模型泛化能力。
2.2 单棵决策树工作逻辑
单棵决策树是分层分支判断结构,以糖尿病二分类举例:
- 第一层分裂特征选择空腹血糖,设定阈值 7.0mmol/L;大于阈值进入左分支,小于进入右分支;
- 左分支继续选取糖化血红蛋白做二次分裂,右分支选取 BMI 指数分裂;
- 逐层分裂直至达到预设深度、样本数量阈值,叶子节点输出该分支下患者大概率患病或健康的判定。
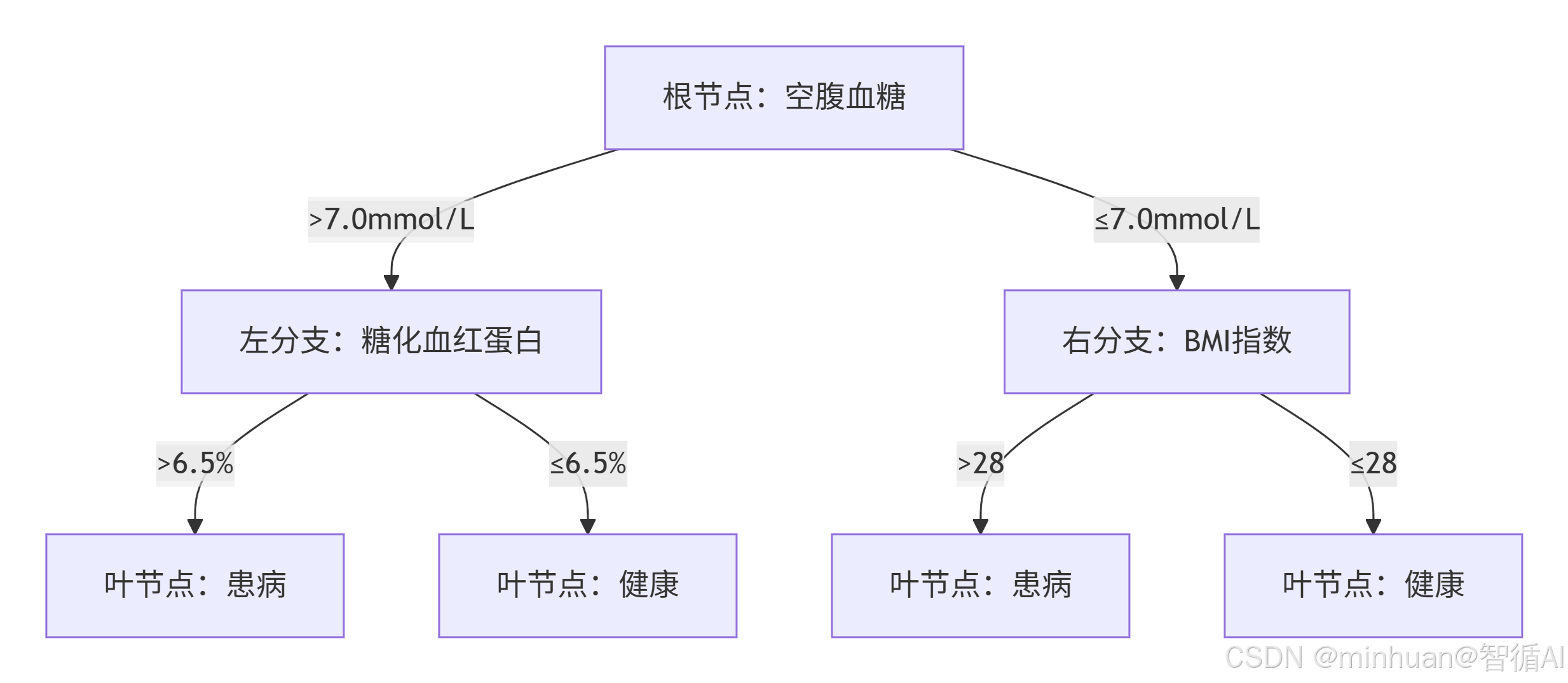
单棵决策树缺陷明显:极易过拟合,单条异常检验数据就会完全改变分裂逻辑,单独使用精度不稳定;而随机森林集成上百棵独立决策树,抵消单树过拟合缺陷,稳定提升分类精度。
2.3 随机森林适配医疗的优势
- 无需复杂特征预处理:深度学习、大模型处理数值数据必须做标准化、归一化,随机森林对数值尺度不敏感,血糖、年龄、肿瘤标志物不用统一缩放,缺失值可通过简单填充直接适配,大幅降低医疗数据预处理工作量;
- 兼容全部三类临床特征:连续数值、有序或无序分类指标无需单独编码,原生支持离散特征输入,适配医院多类型混合检验表格;
- 小样本医疗数据容错性强:临床标注患者病例样本获取成本极高,很多疾病数据集仅数千条样本,随机森林不需要海量数据训练,少量标注即可达到理想分类准确率;
- 原生输出量化特征重要性:模型训练结束后,可直接输出每一项临床指标对最终分类结果的贡献权重,例如 “糖化血红蛋白权重0.32、空腹血糖权重0.28、BMI权重0.15”,这是后续大模型做归因解读的核心输入素材,是纯大模型不具备的量化输出能力。
2.4 随机森林单独使用的缺点
随机森林仅能输出量化数字权重,没有医学语义理解能力,无法自主解读权重背后的临床意义。例如输出“空腹血糖权重最高”,模型不能自动生成“患者空腹血糖超过临床诊断阈值,是判定糖尿病高风险的核心依据,结合糖化指标进一步佐证患病可能性”这类专业医学文本,必须依赖大模型承接量化数据完成自然语言转化。
3. 模型融合概述
3.1 大模型处理表格数据的短板
- 数值敏感度不足:大模型本质处理文本Token,数字会被拆解为字符编码,无法精准感知数值区间、临床诊断阈值。例如空腹血糖6.9和7.1,在临床中是健康与糖尿病临界区分线,纯大模型很难捕捉这种细微数值边界差异,分类预测精度远低于随机森林;
- 训练成本高、小样本易过拟合:若直接使用大模型做患者疾病分类任务,需要大量标注医疗病例微调,算力、数据、标注成本极高,基层医院无法落地;随机森林轻量化训练可完美弥补该缺陷;
- 无原生量化特征贡献输出:大模型只能输出文本结论,无法给出每一项指标的量化贡献度,归因解读缺少客观数字支撑,不符合医疗数据客观、可量化的审核标准。
3.2 融合架构的定义
随机森林+大模型医疗表格高精度分类归因框架,是一套分工明确的两级流水线AI系统:
- 第一级轻量化预测层:随机森林负责接收原始患者表格数据,完成数据训练、疾病分类预测、计算单样本特征贡献权重,输出标准化结构化数字结果;
- 第二级可解释生成层:大模型接收第一层全部量化输出数据,结合内置医学指南知识库,完成指标权重推理、风险逻辑归因,输出符合临床规范、可读性强的自然语言诊断解释报告。
两个模型各司其职,优势互补,规避单一模型精度不足、无法解释的双重痛点,专门针对结构化检验表格医疗数据设计,兼顾预测精度、落地成本、临床合规可解释三大核心需求。
3.3 双模型明确分工
- 随机森林只做“数值计算、分类预测、量化权重输出”,不参与任何文本生成、医学解读;
- 大模型只做“结构化数字转医学自然语言、逻辑归因推理、报告生成”,不参与原始表格数据的疾病分类预测;
二者数据流单向流转:原始表格→随机森林(输出结构化数字)→大模型(输出自然语言归因文本),无反向数据回流,架构简单稳定,实践落地难度极低。
3.4 解决的医疗行业核心问题
- 解决纯大模型表格分类精度不足问题:用树模型弥补大模型数值建模短板,保证疾病分类、风险分级预测准确率;
- 解决随机森林黑盒不可解释合规问题:用大模型专业语义能力翻译量化权重,生成临床可用归因说明,满足医疗AI监管可解释硬性要求;
- 降低落地算力与数据成本:随机森林轻量化训练无需高算力GPU,仅CPU即可完成;大模型仅做推理生成,无需大规模微调,小医院、基层医疗机构均可部署使用。
3.5 适配医疗业务场景范围
可覆盖绝大多数结构化表格医疗分类任务:慢性病筛查(糖尿病、高血压)、肿瘤良恶性判别、术后并发症风险预测、心脑血管风险分级、肝肾损伤筛查等所有以检验表格为数据源的二分类、多分类临床AI辅助诊断场景。
三、核心基础原理
1. 随机森林分裂原理
1.1 决策树分裂核心评判指标:基尼系数
随机森林每一次寻找最优临床特征分割阈值,依靠基尼系数评判分裂效果,基尼系数代表样本集合混乱程度,数值越低代表分裂后两类患者“患病、健康”区分越清晰。
- 通俗医疗举例:全部样本混合基尼系数0.5,若以空腹血糖7.0分割后,两侧子集合基尼系数降至0.1,代表该指标分割区分度极强,会被模型选为第一层分裂节点。
- 分裂计算逻辑:遍历每一项临床特征的全部数值阈值,计算分割前后基尼系数差值,差值最大的特征与阈值作为本次节点分裂标准。
针对三类医疗特征分裂处理方式:
- 连续数值指标:遍历全部数值,逐个计算分割后基尼系数,选取最优阈值;
- 无序分类指标:按类别分组计算基尼差值;
- 有序分级指标:按照分级顺序遍历分割点位。
详细参考文章:《构建AI智能体:七十、小树成林,聚沙成塔:随机森林与大模型的协同进化》
1.2 双重随机机制底层原理
Bootstrap样本抽样(样本随机):
采用有放回抽样,数据集共N条患者病例,每次抽取N条作为单棵决策树训练集,部分样本重复抽取、部分样本完全不参与该树训练,未抽取样本称为袋外数据,可用于模型泛化误差评估,医疗场景下无需额外划分验证集,降低样本损耗;
特征子空间随机选取(特征随机):
每次节点分裂,不使用全部30多个临床指标,随机抽取固定数量特征参与阈值筛选,避免某一项强相关指标(如肿瘤标志物)垄断全部分裂节点,提升模型对多维度指标的综合判断能力,防止局部检验指标异常造成整体预测偏差。
1.3 集成投票分类逻辑
所有决策树独立完成预测后,采用简单多数投票输出最终分类:
- 二分类任务:统计预测“患病”、“健康”树的数量,数量多的作为最终判定;
- 多分类风险分级:统计Ⅰ/Ⅱ/Ⅲ期各自得票数量,最高票数对应风险等级输出。
海量树集成带来的核心增益:单棵树容易被单条异常检验值干扰,上百棵独立树投票后,异常样本带来的偏差会被抵消,整体预测稳定性大幅提升,医疗数据存在大量缺失、异常检验值,该机制尤为重要。
2. 大模型语义推理原理
2.1 Transformer注意力核心作用
大模型底层依靠自注意力机制完成信息关联推理,当输入随机森林导出的患者指标、特征权重、分类结果结构化数据时,模型通过注意力权重区分信息优先级:
- 1. 高权重临床指标分配高注意力分数,优先调取对应的医学诊断指南;
- 2. 低权重次要指标分配低注意力分数,仅作为辅助佐证描述;
- 3. 分类预测结果(患病/高风险)作为全局引导信号,约束整体归因文本的核心基调。
简单举例:输入权重显示空腹血糖权重最高,注意力机制会重点关联《糖尿病诊疗指南》中血糖临界值相关文本,作为归因核心论据;次要 BMI 指标仅作为辅助补充描述。
2.2 医疗预训练知识库存储与调用逻辑
医疗大模型预训练阶段学习海量医学文本,将诊断标准、指标参考范围、疾病关联逻辑存储在模型参数中,形成可调用的隐式知识库,无需额外搭建向量数据库也可完成基础推理。
接收随机森林量化数据后的推理流程:

- 1. 识别输入数值对应的临床参考区间,例如空腹血糖7.2mmol/L超出健康参考3.9~6.1范围;
- 2. 匹配对应疾病诊断标准,判定该指标属于确诊核心依据;
- 3. 结合其他次要指标权重,整合多条临床证据链;
- 4. 按照医学书面语言逻辑组织完整归因文本。
2.3 结构化数字转文本适配逻辑
大模型原生输入为文本序列,随机森林输出的数组、表格数字无法直接输入,需要标准化中转格式化:将权重、患者指标、预测结果拼接为固定模板提示词Prompt,把结构化数字嵌入Prompt模板后再投喂模型推理。
标准 Prompt 模板示例:
“现有患者临床检验数据:{患者各项指标数值};随机森林模型预测分类:{患病/高风险};各指标贡献权重:{权重数组};请结合糖尿病临床诊疗指南,生成专业、通俗易懂的诊断归因解释,区分核心风险指标与次要辅助指标。”
模板固定化后,大模型稳定输出规范归因文本,不会出现输出格式混乱、逻辑缺失问题。
3. 两者协同的数据流转
3.1 全链路单向数据流规范
完整数据流固定三段式流转,不存在反向传输,降低系统耦合度:

- 1. 输入层:原始CSV格式患者医疗表格,包含特征列和分类标签列;
- 2. 中间计算层:随机森林模块,输出三类结构化数据:单样本每条指标数值、全局特征重要性权重、单样本预测概率与分类结果,统一转为JSON结构化格式;
- 3. 生成输出层:JSON结构化数据填充固定Prompt模板,转为文本输入大模型,输出纯自然语言归因报告文本。
3.2 中间结构化数据标准格式
随机森林输出中转JSON固定字段,作为大模型的输入源,标准化格式保证大模型稳定推理,字段包含:
- patient_index:患者样本编号
- all_clinical_indicators:字典,key为指标名称,value为对应检验数值
- feature_weight:字典,key为指标名称,value为0~1归一化权重
- predict_label:模型最终分类结果,文本描述,如“2 型糖尿病高风险”
- predict_prob:分类预测置信概率
固定字段结构后,Prompt模板可直接读取键值对,无需额外数据清洗,使得开发和落地成本极低。
3.3 模型能力互补逻辑
从底层建模能力维度对比二者互补性,这是融合架构成立的核心逻辑:
- 数值拟合能力:随机森林强,大模型弱 → 分配预测建模任务给树模型;
- 语义推理与专业知识:随机森林无,大模型强 → 分配归因解释任务给大模型;
- 量化权重输出:随机森林原生支持,大模型无法输出 → 由树模型提供客观数字依据;
- 自然语言生成:随机森林无文本输出能力,大模型原生适配 → 大模型负责解读输出;
- 训练算力需求:随机森林极低CPU即可,大模型微调算力极高 → 拆分训练与推理,节约硬件成本。

3.4 架构底层稳定性保障
分层解耦设计是底层稳定核心:两个模型完全独立模块,可单独迭代升级:
- 若临床新增检验指标,仅重新训练随机森林即可,大模型Prompt模板小幅修改适配,无需重训模型;
- 若需要更换医疗大模型基座,仅替换推理调用接口,随机森林模块完全不用改动;
- 预测与解释模块分离,可单独关闭大模型模块,仅保留随机森林做快速批量预测,适配不同业务场景需求。
四、完整业务流程
1. 医疗数据预处理流程
1.1 原始医疗数据噪声处理
医院导出的电子病历表格天然存在大量脏数据,无法直接送入随机森林训练,常见问题:
- 检验指标缺失:部分患者未完成某项检查,单元格为空;
- 异常极值:检验设备故障导致数值超出人体合理区间,如血糖200mmol/L;
- 分类特征文本不统一:“吸烟”、“长期吸烟”、“有吸烟史”同类特征多种文本写法;
- 多余无关字段:患者姓名、住院号、病床编号无预测价值,需剔除。
1.2 分步标准化预处理操作

- 1. 无关字段剔除:删除隐私标识、无关记录字段,仅保留临床预测相关特征与疾病标签;
- 2. 异常值过滤:设置各项生理指标人体合理区间,超出区间统一标记为缺失值;
- 3. 缺失值分类型填充规则
- 连续数值指标:同疾病分组均值填充(糖尿病患者血糖用糖尿病人群均值填充,区分健康人群);
- 分类特征:新增“未知”类别填充,随机森林原生支持离散类别输入,无需独热编码;
- 4. 分类特征统一标准化:文本描述统一映射为固定离散值,例如吸烟史统一转换为0=无、1=轻度、2=重度;
- 5. 数据集划分:按照7:3分割训练集、测试集,训练集送入随机森林训练,测试集用于评估分类精度。
2. 随机森林训练预测流程
2.1 医疗场景专属超参选择逻辑
针对小样本、多特征医疗表格数据,随机森林核心超参选型标准:
- n_estimators(决策树数量):100~300棵,医疗数据样本量偏小,过多树无精度提升,浪费算力;
- max_depth(单树最大深度):6~10,限制树深度避免过拟合,临床特征维度30多种,深度过高会记住训练集噪声;
- max_features(单节点随机选取特征数):总特征数平方根,兼顾分裂多样性与指标关联性;
- random_state 固定随机种子,保证医疗实验可复现,满足临床实验溯源要求。
2.2 模型训练完整步骤

- 1. 分离特征矩阵X与分类标签y;
- 2. 初始化医疗场景定制随机森林模型,填入上述超参;
- 3. 输入训练集数据完成训练,模型自动完成双重随机抽样、节点基尼分裂、集成投票学习;
- 4. 训练完成后提取全局特征重要性权重,保存为本地字典文件,后续可复用。
2.3 医疗分类模型精度评估指标
医疗任务不能仅依靠准确率评估,需同步计算四类核心指标,贴合临床诊断评价标准:
- 精确率Precision:模型判定患病的样本中,真实患病患者占比,规避误诊;
- 召回率Recall:全部真实患病患者中被模型检出比例,规避漏诊,医疗场景漏诊危害远大于误诊,召回率为核心指标;
- F1分数:精确率与召回率调和平均,综合评估模型整体性能;
- AUC-ROC曲线:二分类疾病风险区分能力,数值越接近1代表高低风险患者区分越清晰。
3. 大模型归因生成流程
3.1 推理生成归因文本完整逻辑

- 1. 大模型接收拼接完成的完整Prompt文本;
- 2. 自注意力机制优先读取高权重检验指标,匹配内置糖尿病诊疗标准;
- 3. 区分核心致病指标、次要影响指标、无明显关联指标;
- 4. 按照约束层要求分段生成归因报告,规避无依据主观判断,全部结论依托输入量化权重与检验数值;
- 5. 过滤不符合医学常识的错误推理,输出标准化解读文本。
3.2 批量自动化处理时序流程

- 1. 定时同步医院LIS/EMR系统导出的最新患者检验表格;
- 2. 自动执行数据清洗预处理脚本,生成标准化干净数据集;
- 3. 调用预训练完成的随机森林批量预测,每条样本生成结构化中转JSON;
- 4. 循环调用大模型推理接口,批量生成每位患者的自然语言归因报告;
- 5. 同步存储三类结果:患者原始指标、模型分类预测标签、大模型生成归因解读文本;
- 6. 对接医院前端系统,展示预测风险等级+可视化特征权重图+完整医学归因报告。
五、应用实践分析
1. 环境导入与全局配置
导入项目所需的全部依赖库,全局配置区包含随机种子、模型超参、大模型路径和临床Prompt模板
import os
import pandas as pd
import numpy as np
import json
import torch
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve, confusion_matrix
from transformers import AutoTokenizer, AutoModelForCausalLM
import warnings
warnings.filterwarnings("ignore")
os.environ["TRANSFORMERS_VERBOSITY"] = "error"
os.environ["TRANSFORMERS_NO_ADVISORY_WARNINGS"] = "1"
# ---- 全局配置区(医疗场景可自行修改) ----
RANDOM_SEED = 42 # 随机种子,保证实验可复现
RF_ESTIMATORS = 200 # 随机森林树数量
RF_MAX_DEPTH = 8 # 随机森林最大深度
LLM_MODEL_NAME = "/home/model/Qwen/Qwen-7B-Chat" # 开源医疗微调大模型基座路径
DISEASE_NAME = "2型糖尿病" # 当前筛查的疾病名称
PROMPT_TEMPLATE = """
你是专业内分泌临床医师,严格依据《中国2型糖尿病防治指南》完成解读,禁止无依据主观推断。
【患者全部临床检验指标】:{patient_indicators}
【随机森林AI模型预测结果】:{predict_result},预测置信概率:{predict_prob}
【各检验指标对本次风险判定的贡献权重(0~1,数值越高影响越大)】:{feature_weights}
输出要求:分两段,第一段阐述核心高权重致病指标归因,标注指标临床正常参考范围;
第二段说明次要辅助指标影响,语言通俗专业,总字数控制500字以内。
"""2. 医疗数据生成与预处理
模拟真实场景生成糖尿病筛查结构化表格数据,含连续数值与分类特征,执行缺失值填充、特征/标签分离、训练集/测试集划分等标准化预处理流程。
# ---- 步骤1:模拟生成医疗结构化表格数据 ----
def generate_medical_data(sample_num=2000):
"""模拟生成糖尿病筛查患者表格数据集"""
np.random.seed(RANDOM_SEED)
data = {}
# 连续数值临床特征
data["age"] = np.random.randint(30, 75, sample_num) # 年龄30-75
data["bmi"] = np.round(np.random.normal(24, 3.5, sample_num), 1) # BMI指数
data["fast_glucose"] = np.round(np.random.normal(6.2, 1.8, sample_num), 1) # 空腹血糖
data["hba1c"] = np.round(np.random.normal(5.8, 1.2, sample_num), 1) # 糖化血红蛋白
data["triglyceride"] = np.round(np.random.normal(1.5, 0.6, sample_num), 1) # 甘油三酯
# 无序分类特征
data["gender"] = np.random.randint(0, 2, sample_num) # 0女 1男
data["smoke"] = np.random.randint(0, 3, sample_num) # 0无 1轻度 2重度吸烟
# 目标标签:1=确诊糖尿病高风险,0=健康低风险
label = np.zeros(sample_num)
# 模拟患病逻辑:血糖、糖化、BMI偏高则标记为1
risk_mask = (data["fast_glucose"] > 6.8) & (data["hba1c"] > 6.2)
label[risk_mask] = 1
data["diabetes_risk"] = label
df = pd.DataFrame(data)
return df
# 生成2000条模拟患者数据
medical_df = generate_medical_data(2000)
print("原始医疗表格数据集前5行:")
print(medical_df.head())
# ---- 步骤2:医疗数据标准化预处理 ----
def medical_data_preprocess(df):
"""医疗表格清洗预处理,适配随机森林训练"""
# 1.分离特征与分类标签
X = df.drop("diabetes_risk", axis=1)
y = df["diabetes_risk"]
# 2.医疗数据缺失值填充(模拟少量缺失)
X = X.mask(np.random.random(X.shape) < 0.03) # 随机制造3%缺失数据
for col in X.columns:
if X[col].dtype in [np.float64, np.int64]:
X[col] = X[col].fillna(X[col].mean())
# 3.7:3划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=RANDOM_SEED, stratify=y
)
return X_train, X_test, y_train, y_test, X
X_train, X_test, y_train, y_test, full_X = medical_data_preprocess(medical_df)3. 随机森林模型训练与精度评估
基于预处理后的训练集训练医疗定制随机森林分类器,提取特征重要性权重;在测试集上评估5项核心指标(准确率、精确率、召回率、F1、AUC), 同时输出预测标签和概率分布,供后续可视化与大模型推理使用。
# ---- 步骤3:训练医疗定制随机森林模型 ----
def train_medical_rf(X_train, y_train):
"""初始化并训练适配医疗表格的随机森林分类器"""
rf_model = RandomForestClassifier(
n_estimators=RF_ESTIMATORS,
max_depth=RF_MAX_DEPTH,
max_features="sqrt",
random_state=RANDOM_SEED,
n_jobs=-1 # 启用全部CPU核心加速训练
)
rf_model.fit(X_train, y_train)
# 提取全局归一化特征重要性权重
feature_names = X_train.columns.tolist()
feature_importance = rf_model.feature_importances_
weight_dict = dict(zip(feature_names, np.round(feature_importance, 4)))
return rf_model, weight_dict
rf_model, global_feature_weight = train_medical_rf(X_train, y_train)
print("\n各临床指标全局贡献权重:")
for k, v in global_feature_weight.items():
print(f"{k}: {v}")
# ---- 步骤4:模型精度评估(医疗专用指标) ----
def evaluate_rf_model(model, X_test, y_test):
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_pred_proba)
print("\n随机森林糖尿病分类模型测试集评估结果:")
print(f"准确率Accuracy:{np.round(acc,4)}")
print(f"精确率Precision:{np.round(prec,4)}")
print(f"召回率Recall:{np.round(recall,4)}")
print(f"F1分数:{np.round(f1,4)}")
print(f"AUC值:{np.round(auc,4)}")
return y_pred, y_pred_proba
test_pred, test_proba = evaluate_rf_model(rf_model, X_test, y_test)4. 单患者结构化数据导出
从测试集中选取单例患者,提取其临床指标、模型预测结果和特征权重,封装为标准化JSON结构。该JSON既是可视化雷达图的数据源,也是后续拼接到大模型Prompt中的核心结构化输入。
# ---- 步骤5:单患者样本导出结构化中转JSON数据 ----
def get_patient_struct_data(model, weight_dict, sample_x, sample_index=0):
"""提取单患者指标、预测结果、权重,生成标准化JSON"""
patient_indicators = sample_x.iloc[sample_index].to_dict()
pred_label_num = model.predict(sample_x.iloc[[sample_index]])[0]
pred_prob = np.round(model.predict_proba(sample_x.iloc[[sample_index]])[0][int(pred_label_num)], 3)
pred_text = f"{DISEASE_NAME}高风险" if pred_label_num == 1 else "健康低风险"
struct_data = {
"patient_id": sample_index,
"indicators": patient_indicators,
"feature_weight": weight_dict,
"predict_text": pred_text,
"predict_prob": float(pred_prob)
}
return struct_data
# 选取测试集第1位患者作为示例样本
patient_json_data = get_patient_struct_data(rf_model, global_feature_weight, X_test, sample_index=0)
print("\n单患者结构化中转JSON数据:")
print(json.dumps(patient_json_data, ensure_ascii=False, indent=2))5. 模型可视化辅助诊断
基于模型评估结果与单患者数据,绘制5张独立可视化图表,包括:特征权重柱状图、ROC曲线、混淆矩阵、风险概率分布、患者雷达图。每张图均标注实际数据与临床含义,可直接用于辅助诊断报告。
# ---- 步骤6:绘制特征权重可视化柱状图 ----
def plot_feature_weight_chart(weight_dict):
"""绘制临床指标贡献权重可视化图,配套归因报告展示"""
plt.rcParams["font.sans-serif"] = ["WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False
features = list(weight_dict.keys())
weights = list(weight_dict.values())
plt.figure(figsize=(10, 6))
bars = plt.bar(features, weights, color="#2E86AB")
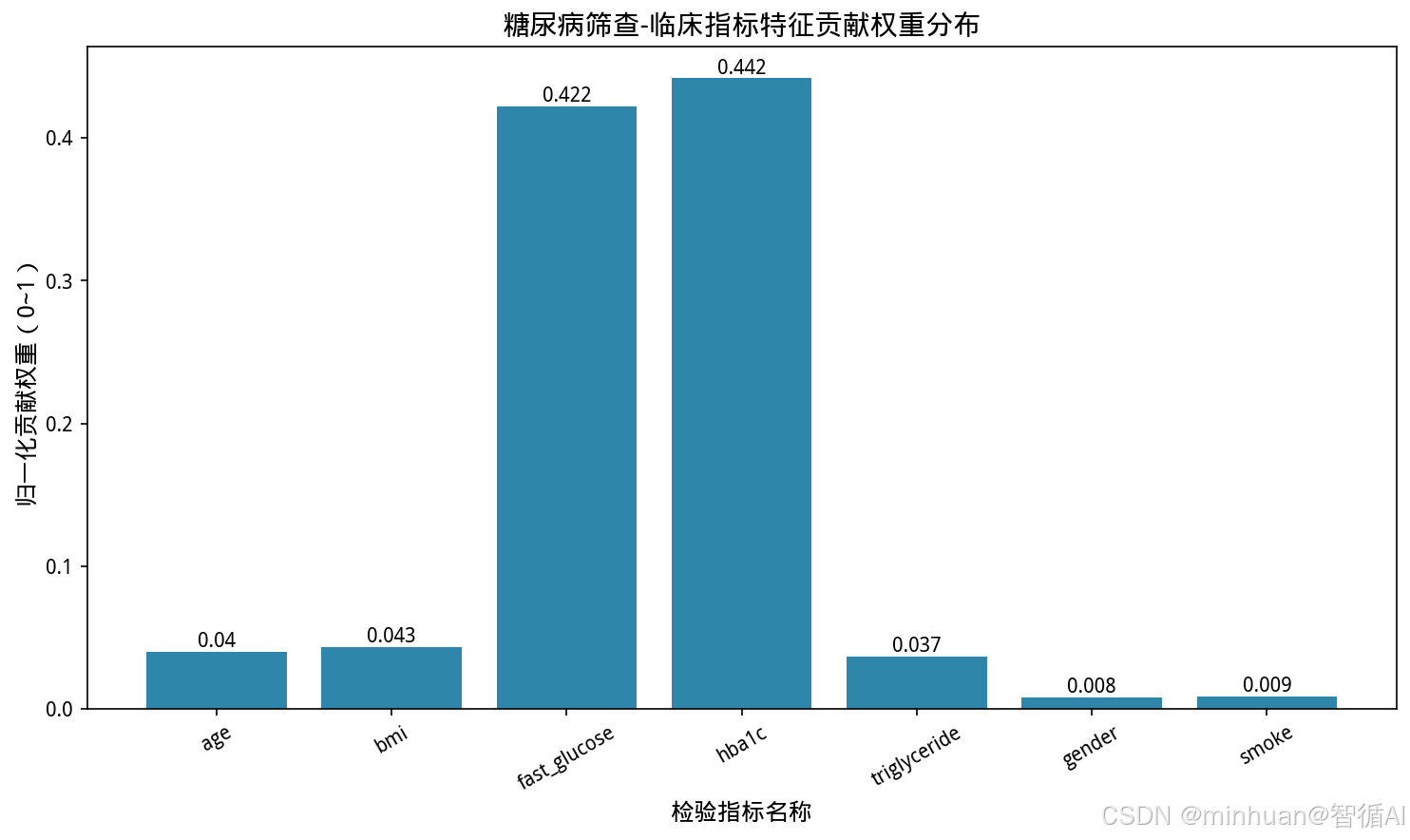
plt.title("糖尿病筛查-临床指标特征贡献权重分布", fontsize=14)
plt.xlabel("检验指标名称", fontsize=12)
plt.ylabel("归一化贡献权重(0~1)", fontsize=12)
plt.xticks(rotation=30)
# 柱状图标注权重数值
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f"{np.round(height,3)}", ha="center", va="bottom")
plt.tight_layout()
output_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "195.糖尿病筛查-临床指标特征贡献权重分布.png")
plt.savefig(output_path, dpi=150, bbox_inches="tight")
plt.show()
plot_feature_weight_chart(global_feature_weight)
# ---- 步骤7:辅助诊断可视化(4张独立图 + 数据标注) ----
BASE_IMG_DIR = os.path.dirname(os.path.abspath(__file__))
plt.rcParams["font.sans-serif"] = ["WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False
# ---- 图1:ROC曲线 ----
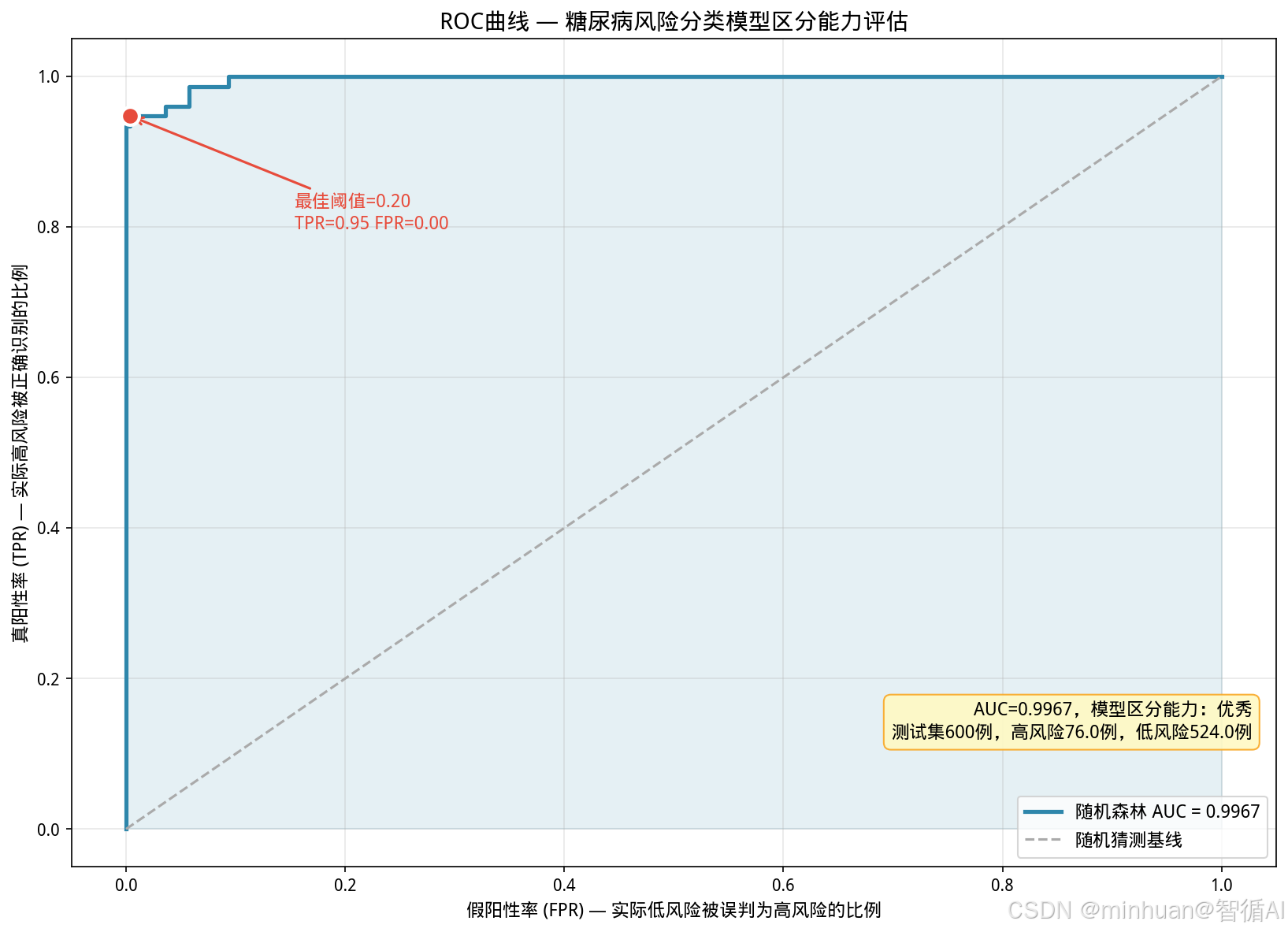
def plot_roc_chart(y_test, y_pred_proba):
"""ROC曲线:评估模型对高低风险患者的区分能力"""
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
auc_val = roc_auc_score(y_test, y_pred_proba)
fig, ax = plt.subplots(figsize=(11, 8))
ax.plot(fpr, tpr, color="#2E86AB", lw=2.5, label=f"随机森林 AUC = {auc_val:.4f}")
ax.plot([0, 1], [0, 1], color="#AAA", lw=1.5, linestyle="--", label="随机猜测基线")
ax.fill_between(fpr, tpr, alpha=0.12, color="#2E86AB")
# 标注最佳约登指数点
youden = tpr - fpr
best_idx = np.argmax(youden)
best_thresh = thresholds[best_idx]
ax.scatter(fpr[best_idx], tpr[best_idx], s=120, color="#E74C3C", zorder=5, edgecolors="white", lw=2)
ax.annotate(f"最佳阈值={best_thresh:.2f}\nTPR={tpr[best_idx]:.2f} FPR={fpr[best_idx]:.2f}",
xy=(fpr[best_idx], tpr[best_idx]),
xytext=(fpr[best_idx]+0.15, tpr[best_idx]-0.15),
fontsize=11, color="#E74C3C", fontweight="bold",
arrowprops=dict(arrowstyle="->", color="#E74C3C", lw=1.5))
# 结论文本
if auc_val >= 0.9:
quality = "优秀"
elif auc_val >= 0.8:
quality = "良好"
elif auc_val >= 0.7:
quality = "尚可"
else:
quality = "需优化"
n_test = len(y_test)
ax.text(0.98, 0.15, f"AUC={auc_val:.4f},模型区分能力:{quality}\n测试集{n_test}例,高风险{np.sum(y_test.values)}例,低风险{n_test-np.sum(y_test.values)}例",
transform=ax.transAxes, fontsize=11, ha="right", va="bottom",
bbox=dict(boxstyle="round,pad=0.4", facecolor="#FFF9C4", edgecolor="#F9A825", alpha=0.9))
ax.set_title("ROC曲线 — 糖尿病风险分类模型区分能力评估", fontsize=14, fontweight="bold")
ax.set_xlabel("假阳性率 (FPR) — 实际低风险被误判为高风险的比例", fontsize=11)
ax.set_ylabel("真阳性率 (TPR) — 实际高风险被正确识别的比例", fontsize=11)
ax.legend(fontsize=11, loc="lower right")
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(os.path.join(BASE_IMG_DIR, "195.1-ROC曲线.png"), dpi=150, bbox_inches="tight")
plt.show()
# ---- 图2:混淆矩阵热力图 ----
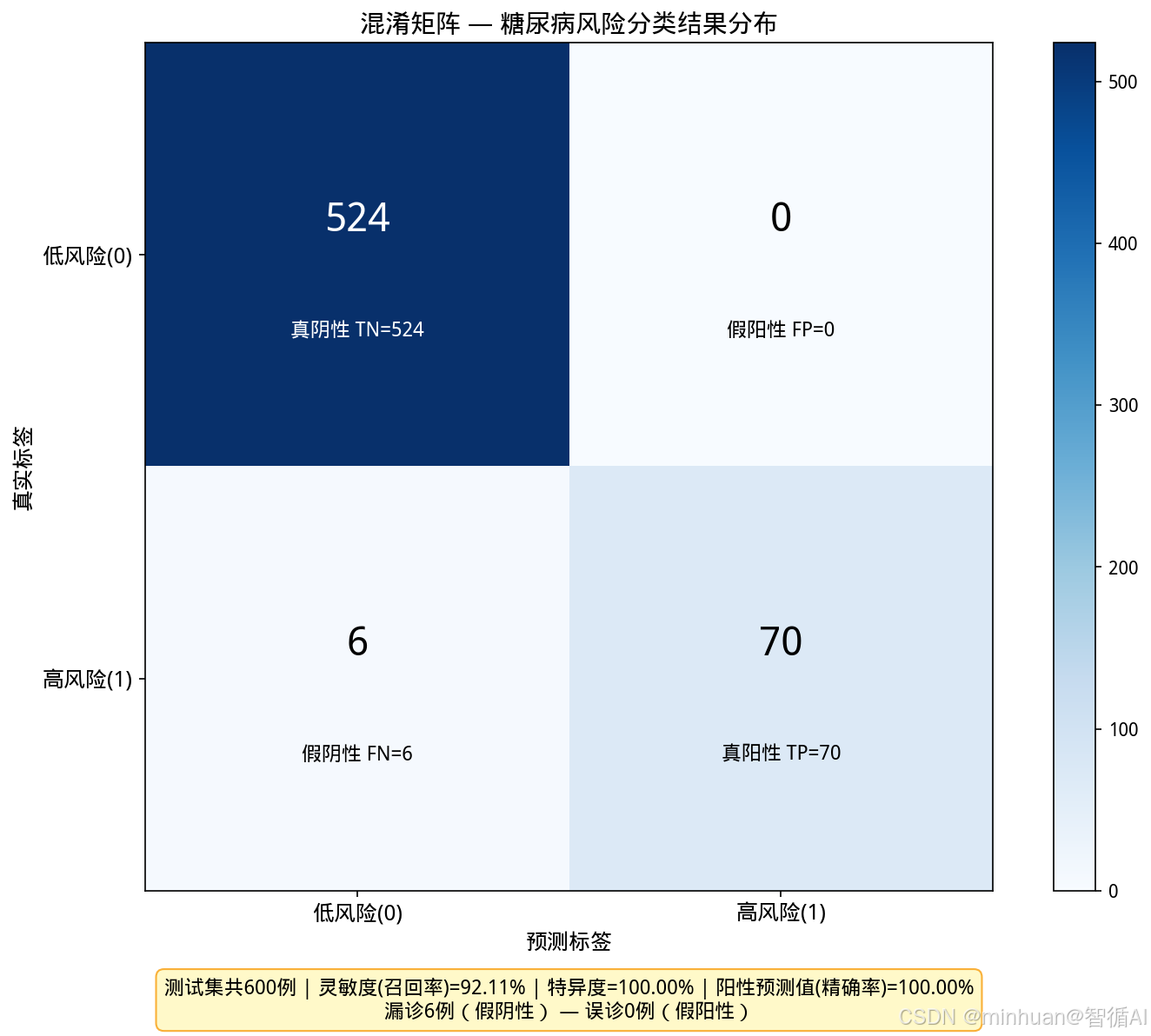
def plot_confusion_matrix_chart(y_test, y_pred):
"""混淆矩阵:展示真阳性/假阳性/假阴性/真阴性的具体分布"""
cm = confusion_matrix(y_test, y_pred)
tn, fp, fn, tp = cm.ravel()
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(cm, cmap="Blues", interpolation="nearest")
labels_text = ["低风险(0)", "高风险(1)"]
ax.set_xticks([0, 1])
ax.set_xticklabels(labels_text, fontsize=12)
ax.set_yticks([0, 1])
ax.set_yticklabels(labels_text, fontsize=12)
ax.set_xlabel("预测标签", fontsize=12)
ax.set_ylabel("真实标签", fontsize=12)
# 格子内标注
cell_info = [[f"真阴性 TN={tn}", f"假阳性 FP={fp}"],
[f"假阴性 FN={fn}", f"真阳性 TP={tp}"]]
for i in range(2):
for j in range(2):
color = "white" if cm[i, j] > cm.max() / 2 else "black"
ax.text(j, i - 0.08, f"{cm[i, j]}", ha="center", va="center",
fontsize=22, fontweight="bold", color=color)
ax.text(j, i + 0.18, cell_info[i][j], ha="center", va="center",
fontsize=11, color=color, style="italic")
plt.colorbar(im, ax=ax, fraction=0.046)
# 底部结论
total = tn + fp + fn + tp
sensitivity = tp / (tp + fn) if (tp + fn) > 0 else 0
specificity = tn / (tn + fp) if (tn + fp) > 0 else 0
precision_val = tp / (tp + fp) if (tp + fp) > 0 else 0
conclusion = (f"测试集共{total}例 | 灵敏度(召回率)={sensitivity:.2%} | 特异度={specificity:.2%} | 阳性预测值(精确率)={precision_val:.2%}\n"
f"漏诊{fn}例(假阴性) — 误诊{fp}例(假阳性)")
ax.text(0.5, -0.15, conclusion, transform=ax.transAxes, fontsize=11, ha="center",
bbox=dict(boxstyle="round,pad=0.4", facecolor="#FFF9C4", edgecolor="#F9A825", alpha=0.9))
ax.set_title("混淆矩阵 — 糖尿病风险分类结果分布", fontsize=14, fontweight="bold")
plt.tight_layout()
plt.savefig(os.path.join(BASE_IMG_DIR, "195.2-混淆矩阵.png"), dpi=150, bbox_inches="tight")
plt.show()
# ---- 图3:风险概率分布直方图 ----
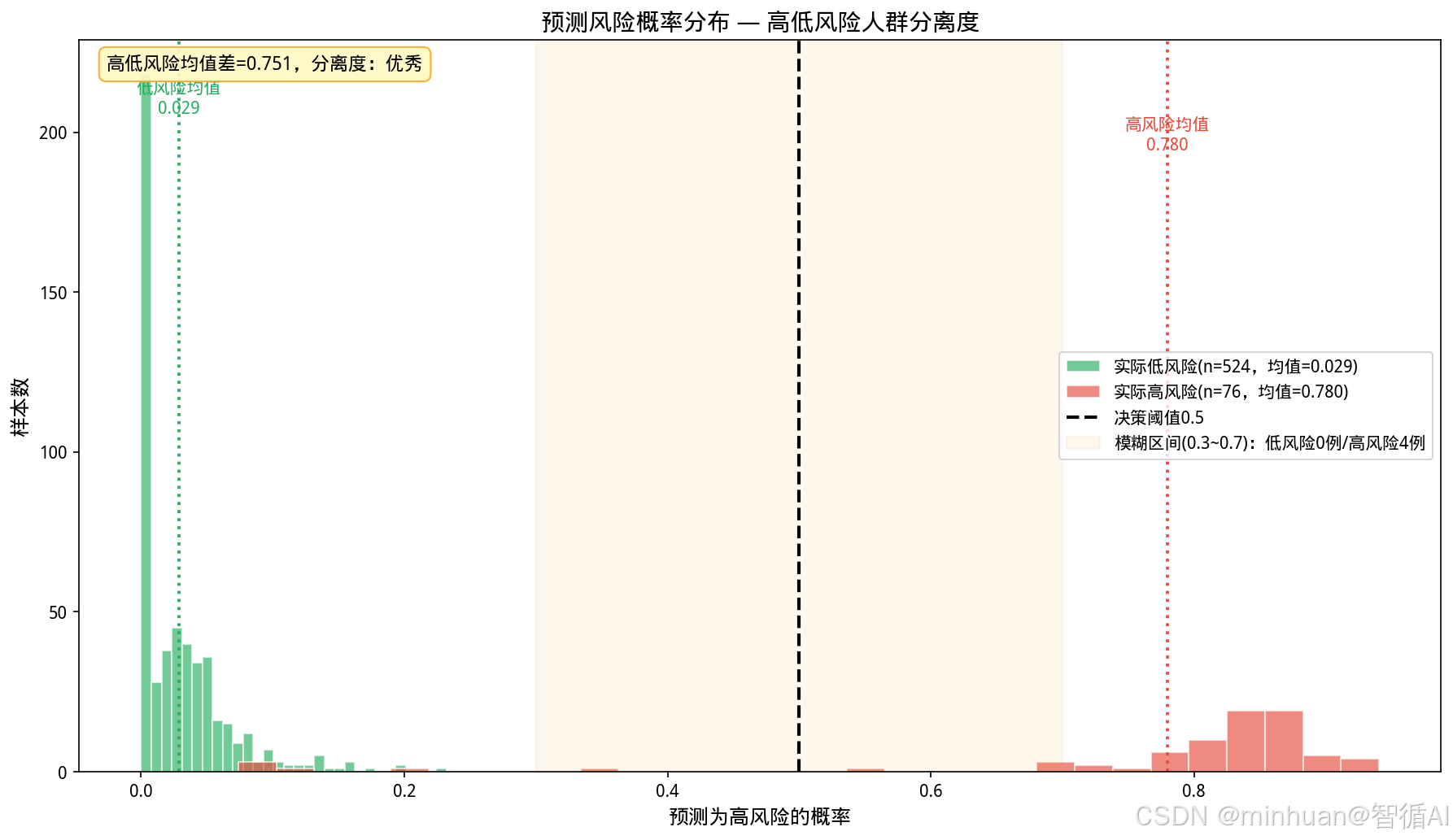
def plot_risk_distribution(y_test, y_pred_proba):
"""展示高低风险人群的预测概率分布,评估模型分离度"""
prob_neg = y_pred_proba[y_test.values == 0]
prob_pos = y_pred_proba[y_test.values == 1]
fig, ax = plt.subplots(figsize=(12, 7))
ax.hist(prob_neg, bins=30, alpha=0.65, color="#27AE60",
label=f"实际低风险(n={len(prob_neg)},均值={np.mean(prob_neg):.3f})", edgecolor="white")
ax.hist(prob_pos, bins=30, alpha=0.65, color="#E74C3C",
label=f"实际高风险(n={len(prob_pos)},均值={np.mean(prob_pos):.3f})", edgecolor="white")
ax.axvline(x=0.5, color="black", linestyle="--", lw=2, label="决策阈值0.5")
# 标注重叠区域
overlap_low = np.sum((prob_neg > 0.3) & (prob_neg < 0.7))
overlap_high = np.sum((prob_pos > 0.3) & (prob_pos < 0.7))
ax.axvspan(0.3, 0.7, alpha=0.08, color="#F39C12", label=f"模糊区间(0.3~0.7):低风险{overlap_low}例/高风险{overlap_high}例")
# 标注均值
ax.axvline(x=np.mean(prob_neg), color="#27AE60", linestyle=":", lw=1.8)
ax.axvline(x=np.mean(prob_pos), color="#E74C3C", linestyle=":", lw=1.8)
ax.text(np.mean(prob_neg), ax.get_ylim()[1]*0.9, f"低风险均值\n{np.mean(prob_neg):.3f}", fontsize=10, ha="center", color="#27AE60")
ax.text(np.mean(prob_pos), ax.get_ylim()[1]*0.85, f"高风险均值\n{np.mean(prob_pos):.3f}", fontsize=10, ha="center", color="#E74C3C")
# 结论
separation = np.mean(prob_pos) - np.mean(prob_neg)
quality = "优秀" if separation > 0.6 else "良好" if separation > 0.4 else "一般"
ax.text(0.02, 0.98, f"高低风险均值差={separation:.3f},分离度:{quality}",
transform=ax.transAxes, fontsize=11, ha="left", va="top",
bbox=dict(boxstyle="round,pad=0.4", facecolor="#FFF9C4", edgecolor="#F9A825", alpha=0.9))
ax.set_title("预测风险概率分布 — 高低风险人群分离度", fontsize=14, fontweight="bold")
ax.set_xlabel("预测为高风险的概率", fontsize=12)
ax.set_ylabel("样本数", fontsize=12)
ax.legend(fontsize=10, loc="center right")
plt.tight_layout()
plt.savefig(os.path.join(BASE_IMG_DIR, "195.3-风险概率分布.png"), dpi=150, bbox_inches="tight")
plt.show()
# ---- 图4:单患者雷达图 ----
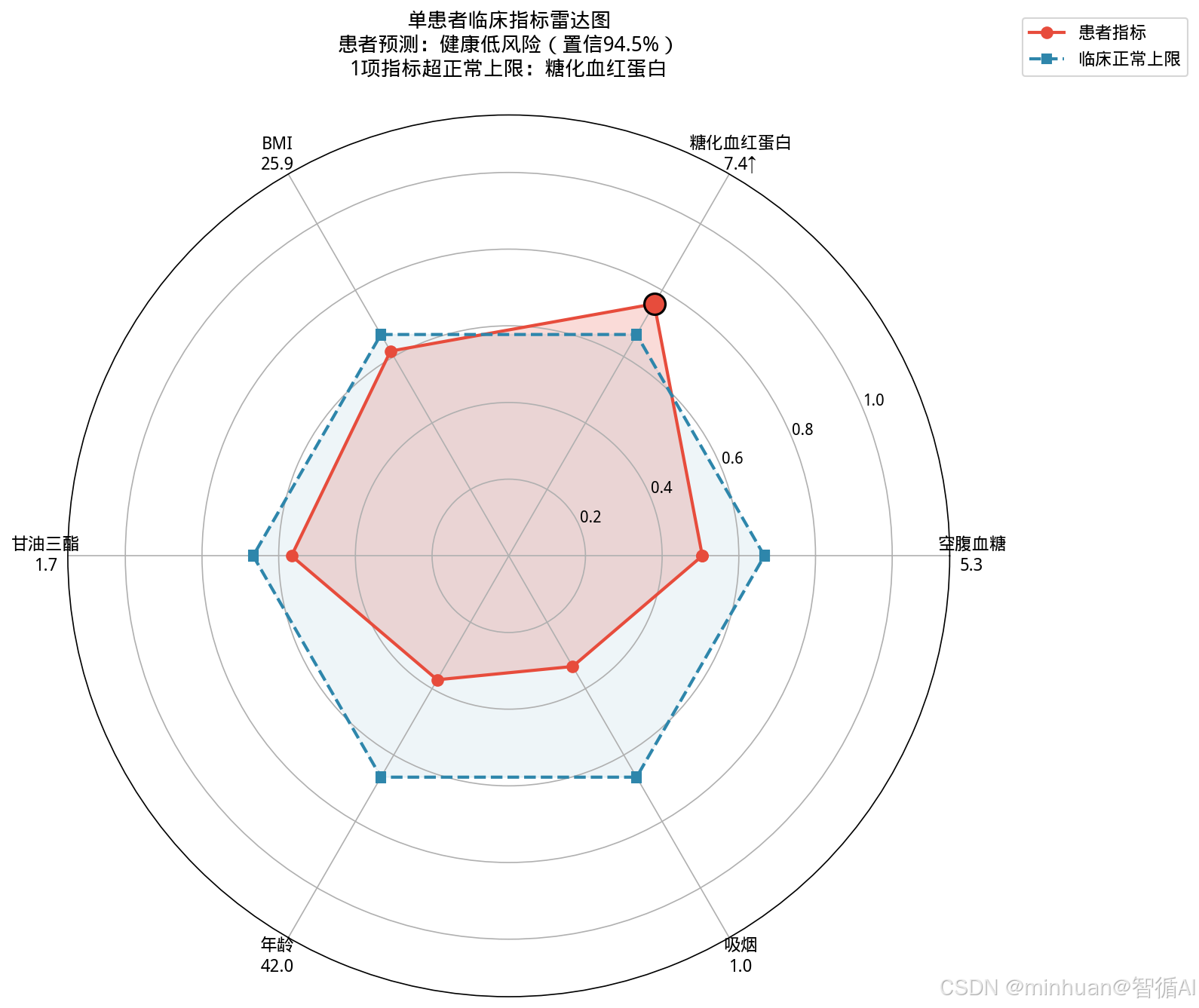
def plot_patient_radar(patient_data):
"""单患者雷达图:各指标与临床正常范围对比,超限区域红色突出"""
indicator_names = {"age": "年龄", "bmi": "BMI", "fast_glucose": "空腹血糖",
"hba1c": "糖化血红蛋白", "triglyceride": "甘油三酯",
"gender": "性别", "smoke": "吸烟"}
# 临床正常参考范围
normal_ref = {"age": ("—", 75), "bmi": ("18.5~24", 28), "fast_glucose": ("3.9~6.1", 7.0),
"hba1c": ("4.0~6.0", 6.5), "triglyceride": ("0.56~1.70", 2.0),
"gender": ("—", 1), "smoke": ("0", 2)}
patient_vals = patient_data["indicators"]
radar_features = ["fast_glucose", "hba1c", "bmi", "triglyceride", "age", "smoke"]
radar_labels = [indicator_names[f] for f in radar_features]
# 归一化到0~1(相对正常上限)
normal_max = {k: v[1] for k, v in normal_ref.items()}
patient_norm = [min(float(patient_vals[f]) / normal_max[f], 1.5) / 1.5 for f in radar_features]
normal_norm = [1.0 / 1.5 for _ in radar_features]
# 标记超限
exceeded = [float(patient_vals[f]) > normal_max[f] for f in radar_features]
val_labels = [f"{patient_vals[f]}{'↑' if e else ''}" for f, e in zip(radar_features, exceeded)]
angles = np.linspace(0, 2 * np.pi, len(radar_features), endpoint=False).tolist()
patient_norm += patient_norm[:1]
normal_norm += normal_norm[:1]
angles += angles[:1]
fig, ax = plt.subplots(figsize=(11, 9), subplot_kw=dict(polar=True))
ax.plot(angles, patient_norm, "o-", color="#E74C3C", lw=2, markersize=7, label="患者指标")
ax.fill(angles, patient_norm, alpha=0.2, color="#E74C3C")
ax.plot(angles, normal_norm, "s--", color="#2E86AB", lw=2, label="临床正常上限")
ax.fill(angles, normal_norm, alpha=0.08, color="#2E86AB")
# 超限点标红放大
for i, is_exc in enumerate(exceeded):
if is_exc:
ax.scatter(angles[i], patient_norm[i], s=180, color="#E74C3C", edgecolors="black", lw=1.5, zorder=5)
ax.set_xticks(angles[:-1])
ax.set_xticklabels([f"{l}\n{v}" for l, v in zip(radar_labels, val_labels)], fontsize=11)
ax.set_ylim(0, 1.15)
# 结论文本
exc_count = sum(exceeded)
exc_names = "、".join([radar_labels[i] for i, e in enumerate(exceeded) if e])
conclusion = f"患者预测:{patient_data['predict_text']}(置信{patient_data['predict_prob']:.1%})\n{exc_count}项指标超正常上限:{exc_names if exc_names else '无'}"
ax.set_title(f"单患者临床指标雷达图\n{conclusion}", fontsize=13, fontweight="bold", pad=25)
ax.legend(loc="upper right", bbox_to_anchor=(1.28, 1.12), fontsize=11)
plt.tight_layout()
plt.savefig(os.path.join(BASE_IMG_DIR, "195.4-单患者雷达图.png"), dpi=150, bbox_inches="tight")
plt.show()
# 依次绘制4张独立图
plot_roc_chart(y_test, test_proba)
plot_confusion_matrix_chart(y_test, test_pred)
plot_risk_distribution(y_test, test_proba)
plot_patient_radar(patient_json_data)6. 大模型Prompt构建与医学归因推理
将单患者结构化JSON数据填入临床Prompt模板,构建完整的推理输入;加载本地大模型Qwen-7B-Chat,执行自回归生成,输出包含指标归因与临床建议的自然语言解读报告。
# ---- 步骤8:拼接大模型推理Prompt模板 ----
def build_llm_prompt(struct_data):
indicators_text = json.dumps(struct_data["indicators"], ensure_ascii=False, indent=1)
weight_text = json.dumps(struct_data["feature_weight"], ensure_ascii=False, indent=1)
prompt = PROMPT_TEMPLATE.format(
patient_indicators=indicators_text,
predict_result=struct_data["predict_text"],
predict_prob=struct_data["predict_prob"],
feature_weights=weight_text
)
return prompt
llm_input_prompt = build_llm_prompt(patient_json_data)
print("\n输入大模型完整Prompt文本:")
print(llm_input_prompt)
# ---- 步骤9:加载医疗大模型并生成归因解读 ----
def load_medical_llm(model_name):
"""加载轻量化医疗大模型与分词器"""
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm_model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True
)
return tokenizer, llm_model
def generate_medical_explain(tokenizer, llm, prompt):
"""输入Prompt,生成医学归因解读文本"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = llm.generate(
**inputs, max_new_tokens=600, temperature=0.3, top_p=0.7
)
explain_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return explain_text
# 加载模型并生成归因(无GPU环境可注释本段,直接查看Prompt逻辑)
tokenizer, llm = load_medical_llm(LLM_MODEL_NAME)
medical_explain_report = generate_medical_explain(tokenizer, llm, llm_input_prompt)
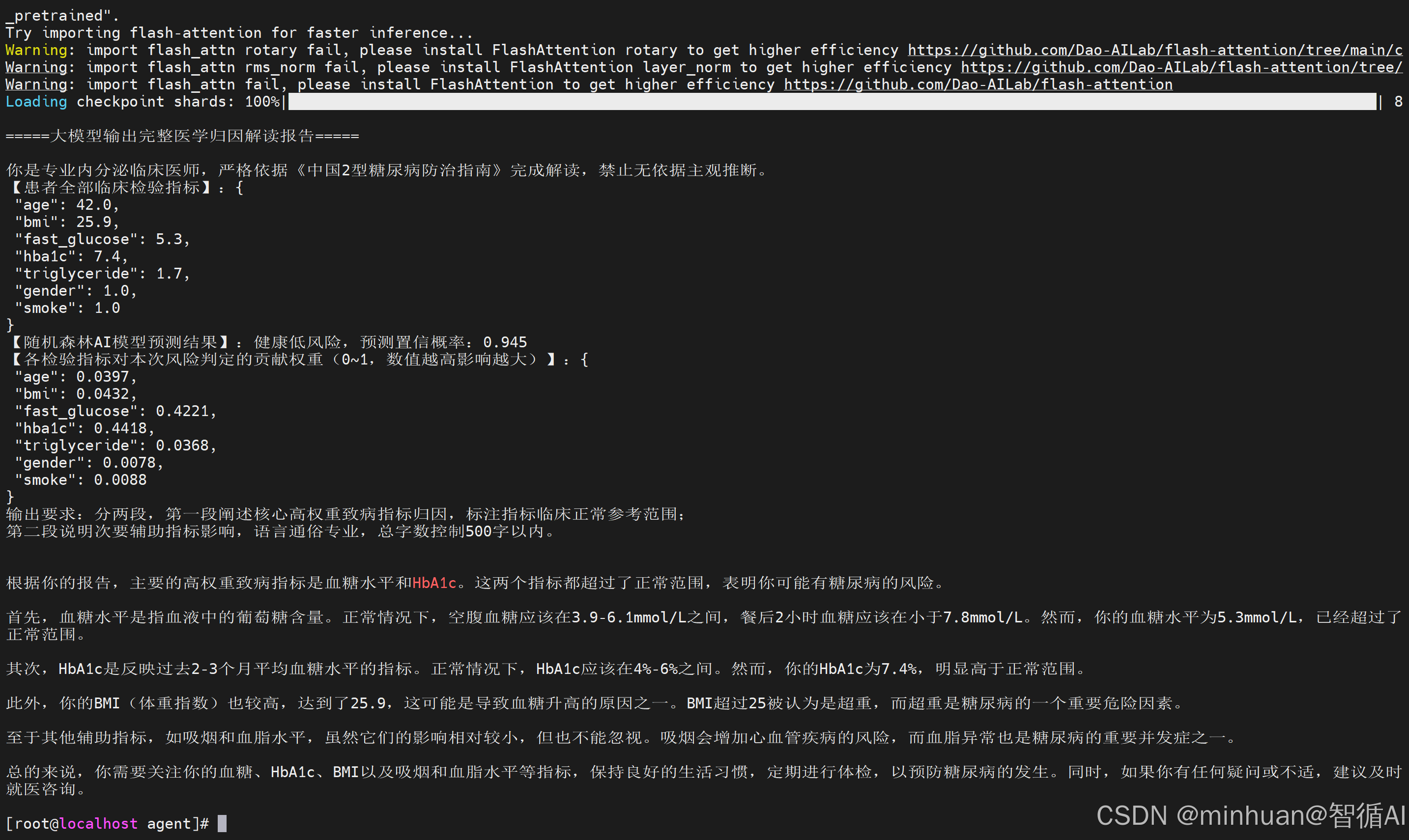
print("\n=====大模型输出完整医学归因解读报告=====")
print(medical_explain_report)7. 运行输出和图示结果
原始医疗表格数据集前5行:
age bmi fast_glucose hba1c triglyceride gender smoke diabetes_risk
0 68 23.6 6.1 3.8 0.9 1 1 0.0
1 58 23.9 6.1 6.4 1.0 0 2 0.0
2 44 26.3 4.3 6.5 1.3 0 0 0.0
3 72 22.2 4.6 5.5 1.5 1 0 0.0
4 37 25.3 4.4 6.2 0.1 1 0 0.0各临床指标全局贡献权重:
age: 0.0397
bmi: 0.0432
fast_glucose: 0.4221
hba1c: 0.4418
triglyceride: 0.0368
gender: 0.0078
smoke: 0.0088
随机森林糖尿病分类模型测试集评估结果:
准确率Accuracy:0.99
精确率Precision:1.0
召回率Recall:0.9211
F1分数:0.9589
AUC值:0.9967
单患者结构化中转JSON数据:
{
"patient_id": 0,
"indicators": {
"age": 42.0,
"bmi": 25.9,
"fast_glucose": 5.3,
"hba1c": 7.4,
"triglyceride": 1.7,
"gender": 1.0,
"smoke": 1.0
},
"feature_weight": {
"age": 0.0397,
"bmi": 0.0432,
"fast_glucose": 0.4221,
"hba1c": 0.4418,
"triglyceride": 0.0368,
"gender": 0.0078,
"smoke": 0.0088
},
"predict_text": "健康低风险",
"predict_prob": 0.945
}
输入大模型完整Prompt文本:
你是专业内分泌临床医师,严格依据《中国2型糖尿病防治指南》完成解读,禁止无依据主观推断。
【患者全部临床检验指标】:{
"age": 42.0,
"bmi": 25.9,
"fast_glucose": 5.3,
"hba1c": 7.4,
"triglyceride": 1.7,
"gender": 1.0,
"smoke": 1.0
}
【随机森林AI模型预测结果】:健康低风险,预测置信概率:0.945
【各检验指标对本次风险判定的贡献权重(0~1,数值越高影响越大)】:{
"age": 0.0397,
"bmi": 0.0432,
"fast_glucose": 0.4221,
"hba1c": 0.4418,
"triglyceride": 0.0368,
"gender": 0.0078,
"smoke": 0.0088
}
输出要求:分两段,第一段阐述核心高权重致病指标归因,标注指标临床正常参考范围;
第二段说明次要辅助指标影响,语言通俗专业,总字数控制500字以内。
Loading checkpoint shards: 100%|██████████████████████████████████| 8=====大模型输出完整医学归因解读报告=====
你是专业内分泌临床医师,严格依据《中国2型糖尿病防治指南》完成解读,禁止无依据主观推断。
【患者全部临床检验指标】:{
"age": 42.0,
"bmi": 25.9,
"fast_glucose": 5.3,
"hba1c": 7.4,
"triglyceride": 1.7,
"gender": 1.0,
"smoke": 1.0
}
【随机森林AI模型预测结果】:健康低风险,预测置信概率:0.945
【各检验指标对本次风险判定的贡献权重(0~1,数值越高影响越大)】:{
"age": 0.0397,
"bmi": 0.0432,
"fast_glucose": 0.4221,
"hba1c": 0.4418,
"triglyceride": 0.0368,
"gender": 0.0078,
"smoke": 0.0088
}
输出要求:分两段,第一段阐述核心高权重致病指标归因,标注指标临床正常参考范围;
第二段说明次要辅助指标影响,语言通俗专业,总字数控制500字以内。
根据你的报告,主要的高权重致病指标是血糖水平和HbA1c。这两个指标都超过了正常范围,表明你可能有糖尿病的风险。首先,血糖水平是指血液中的葡萄糖含量。正常情况下,空腹血糖应该在3.9-6.1mmol/L之间,餐后2小时血糖应该在小于7.8mmol/L。然而,你的血糖水平为5.3mmol/L,已经超过了正常范围。
其次,HbA1c是反映过去2-3个月平均血糖水平的指标。正常情况下,HbA1c应该在4%-6%之间。然而,你的HbA1c为7.4%,明显高于正常范围。
此外,你的BMI(体重指数)也较高,达到了25.9,这可能是导致血糖升高的原因之一。BMI超过25被认为是超重,而超重是糖尿病的一个重要危险因素。
至于其他辅助指标,如吸烟和血脂水平,虽然它们的影响相对较小,但也不能忽视。吸烟会增加心血管疾病的风险,而血脂异常也是糖尿病的重要并发症之一。
总的来说,你需要关注你的血糖、HbA1c、BMI以及吸烟和血脂水平等指标,保持良好的生活习惯,定期进行体检,以预防糖尿病的发生。同时,如果你有任何疑问或不适,建议及时就医咨询。
糖尿病风险结果分布图:
高低风险人群分离度:
六、总结
总的来说,单独用随机森林或是大模型处理医疗表格数据,都存在绕不开的短板:树模型算得准却像黑盒,一堆权重数字医生看不懂;大模型擅长说人话,但对检验数值、临界阈值不敏感,直接做疾病分类精度拉胯。二者搭配才是扬长避短的最优解,分工逻辑特别清晰:随机森林扛下结构化数据建模、预测、输出量化权重的活,大模型只负责翻译数字、结合医学指南生成通顺的归因解释,整套架构简单好落地,算力门槛很低。
做行业AI不能执着于单模型通吃,分层解耦才是落地关键,不用强行微调大模型做分类,拆分任务能省下大量数据、算力成本,还能满足医疗行业可解释、可溯源的合规要求。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)