Agent的记忆系统应该如何构建?

核心洞察
:大多数AI编程代理失败不是因为模型不够强,而是因为缺少一个被忽视的基础层——记忆系统。反复纠正同样的错误、重复下达相同的指令——这种"AI失忆症"才是最大的效率黑洞。
◆ 导读
你是否经历过这样的循环:
你告诉 Claude:"我们项目用 pnpm,别用 npm。"下一轮对话:它又敲下了 npm install。你强调:"这里不要用 default export。"下一个会话:它写了一个 export default。每一次纠正,都在会话结束时蒸发得一干二净。
这不是模型的问题。是架构的问题。
Rahul(@sairahul1)花了三个月反复摸索,找到了一个"单文件修复方案"——用记忆文件层补齐AI代理缺失的最后一块拼图。以下是他的完整经验。
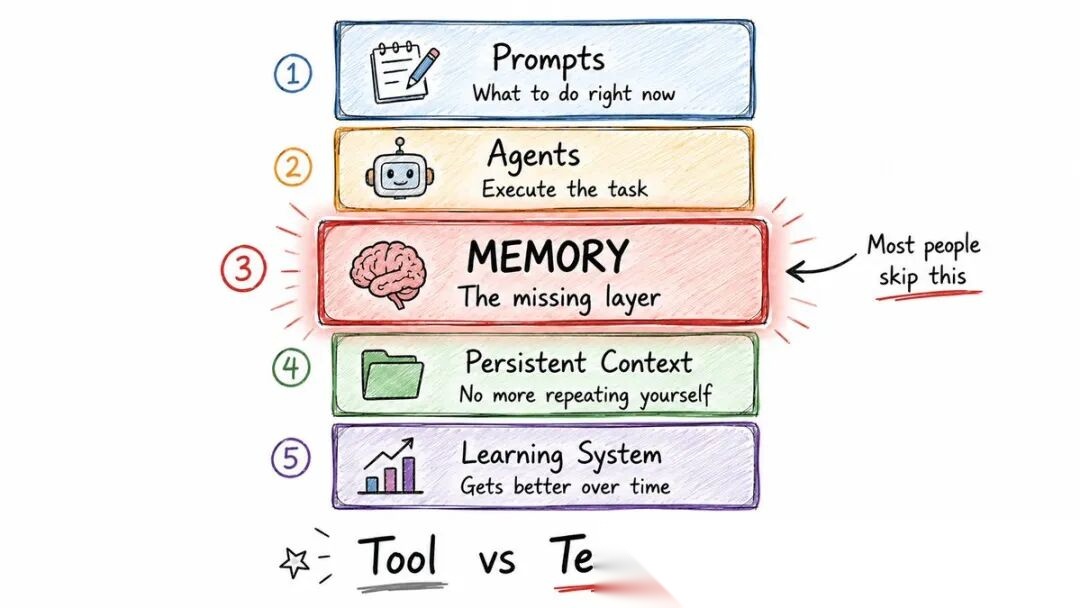
◆ 为什么大多数AI代理会失败
不是因为模型。
是因为模型底下缺失的那一层。
流程是这样的:
→ 你写一段 prompt
→ 代理完成任务
→ 会话结束
→ 记忆清零
→ 下一个会话:同样的错误
→ 你重复同样的指令
→ 永远循环
这就是AI编程中最大的时间黑洞。不是烂代码,不是幻觉——是重复。
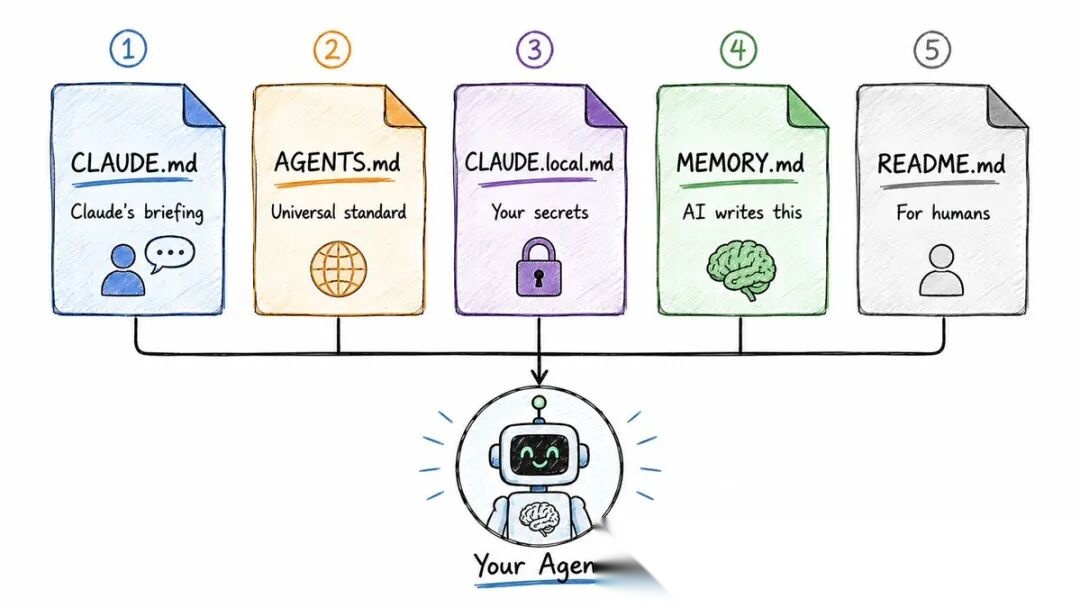
◆ 缺失的那一层:记忆系统
所有人都在争"哪个模型最聪明",但关注错了层面。
真正的升级不是换一个更强的模型,而是给模型一个存储所学内容的地方。
→ Prompt → 告诉代理当前该做什么
→ 代理(Agent)→ 执行任务
→ 记忆(Memory)→ 跨会话保持上下文
→ 持久化上下文 → 不再重复纠正
→ 学习系统 → 代理真正随时间进步
这就是"工具"和"队友"的区别。工具每次从零开始执行你告诉它的。队友记得昨天发生的事。
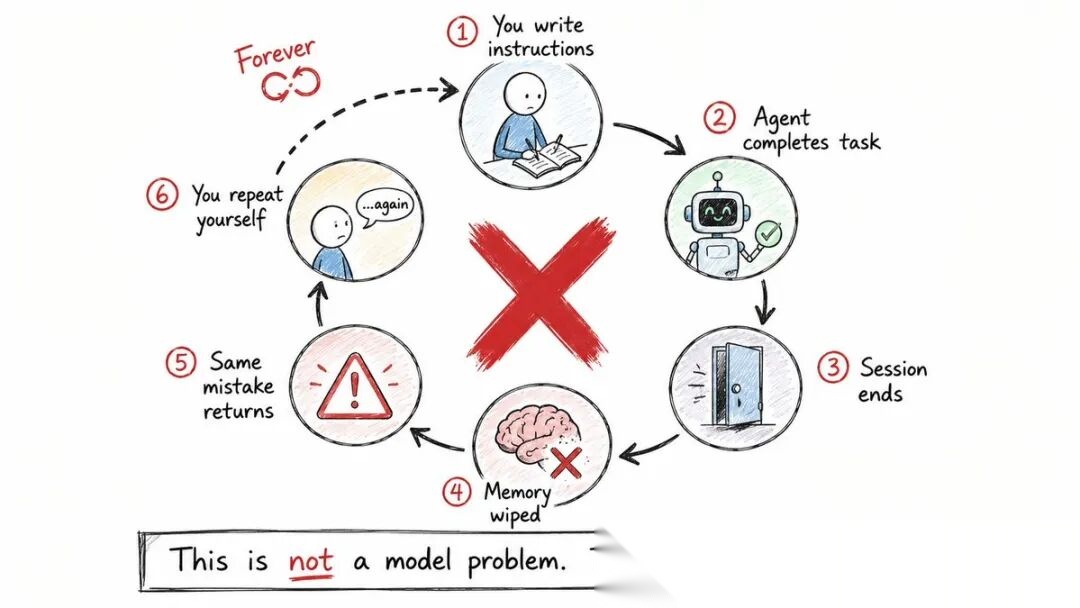
◆ AI代理必备的5个记忆文件
一旦你接受了"记忆是缺失层"这个前提,下一个问题就是:记忆存在哪里?
答案是五个文件,各司其职:
-
CLAUDE.md — Claude 的个人简报文档
-
AGENTS.md — 通用标准,所有主流AI工具都读取
-
CLAUDE.local.md — 你的个人偏好,不提交到Git
-
MEMORY.md — AI自动记录的自我笔记
-
README.md — 给人类看的,不是给代理的
我们逐一来看。
◆ CLAUDE.md — 一切从这里开始
把它放在项目根目录。Claude 在每次会话开始时自动读取它。
可以把它想象成——给一个患有失忆症的新同事写的入职简报。
一份好的 CLAUDE.md 包含四个部分:
→ 项目上下文 — 一句话。“Next.js 电商应用,Postgres + Stripe。”
→ 代码风格 — 不是"格式化代码",而是"使用 ES modules、named exports、2空格缩进"
→ 命令 — 精确字符串。pnpm test:integration,而不是"跑测试"
→ 架构 — “API 路由在 /src/api/[resource]/route.ts,数据库用 repository pattern”
示例 CLAUDE.md:
# CLAUDE.md ## Project Context Next.js 14 e-commerce app. Postgres + Stripe integration. ## Code Style - ES modules only - Named exports, never default exports - 2-space indentation - TypeScript strict mode ## Commands - Install: pnpm install - Dev: pnpm dev - Test: pnpm test:integration - Lint: pnpm lint:fix ## Architecture - API routes: /src/api/[resource]/route.ts - DB access: repository pattern only - Components: /src/components, one file per component
关键原则:控制在300行以内。 每一行都在和工作内容争夺注意力。运行 /init 让 Claude 自动生成一个初稿,然后大胆删——生成的文件里有很多从 package.json 就能看出来的废话。只保留"没有这个文件 Claude 就会搞错"的内容。
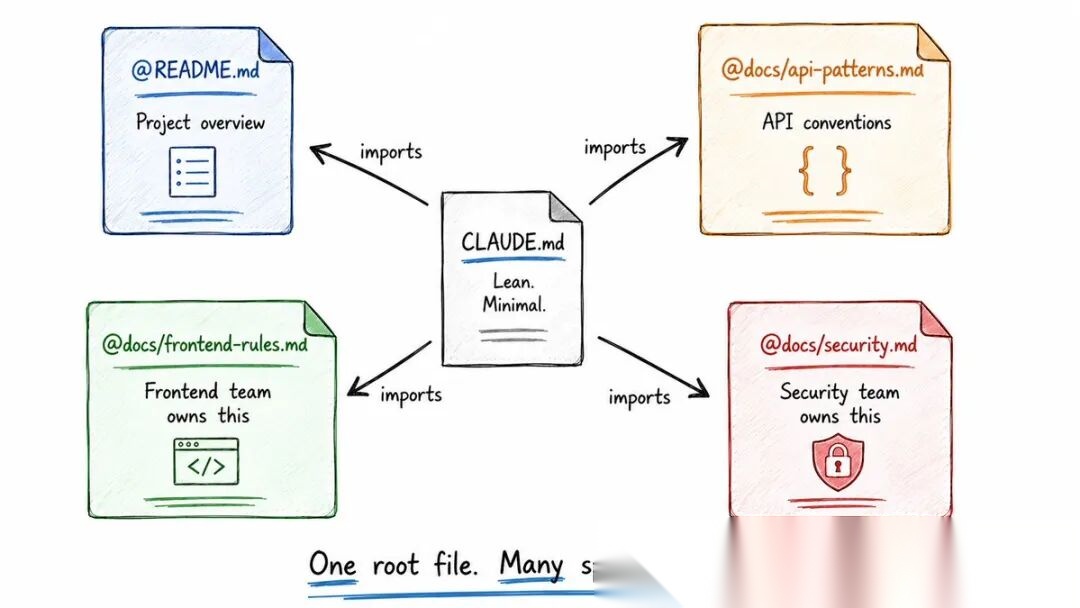
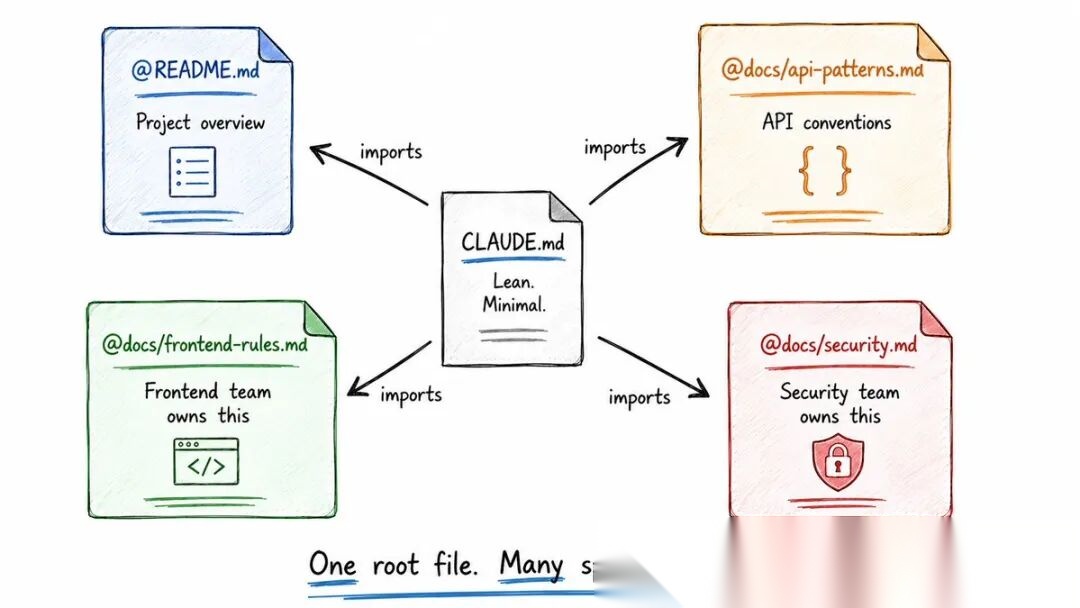
◆ @imports 系统 —— 保持精简
CLAUDE.md 不需要装下所有内容。它可以导入其他文件:
See @README.md for project overview
See @docs/api-patterns.md for API conventions
See @package.json for available npm scripts
导入可以递归——最多5层。这解决了"一个巨大文件"的问题。
对团队来说更强大:前端组维护 docs/frontend-rules.md,安全组维护 docs/security.md,CLAUDE.md 只是导入它们。一个根文件,多个专业来源。
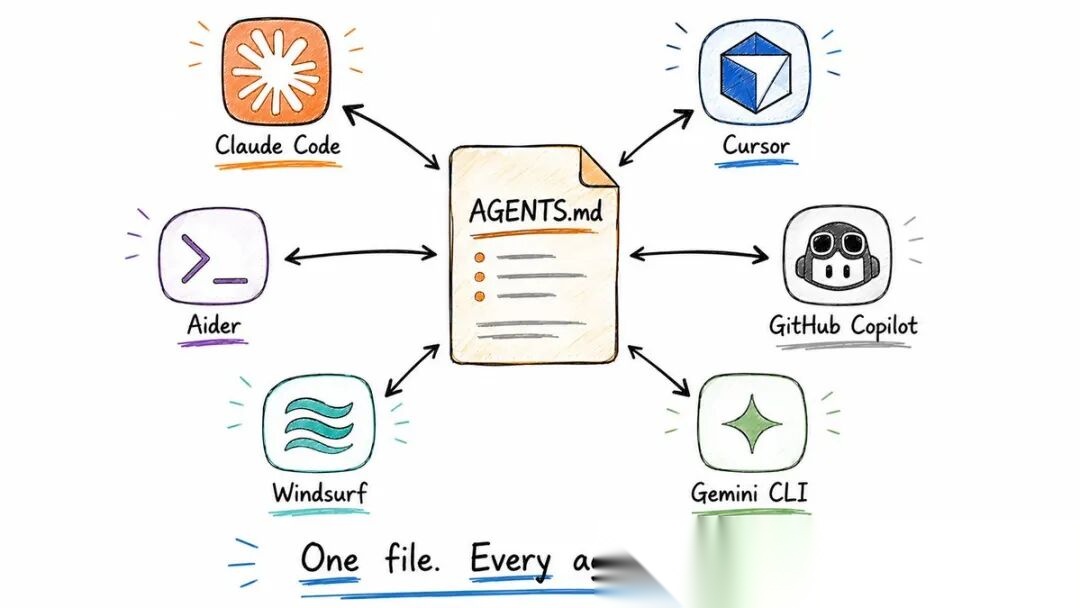
◆ AGENTS.md — 通用标准
CLAUDE.md 只有 Claude 读。如果你的团队同时用 Cursor、Copilot 或 Gemini CLI——它们不会碰 CLAUDE.md。
AGENTS.md 解决了这个问题。一个文件,所有主流代理都读取。
支持的工具包括:Claude Code、Cursor、GitHub Copilot、Gemini CLI、Windsurf、Aider、Zed、Warp 等等。
它就是标准 Markdown,不需要特殊 schema,不需要 YAML。
示例 AGENTS.md:
# AGENTS.md ## Project Overview E-commerce platform built with Next.js 14, Postgres, and Stripe. ## Build & Test - Install: pnpm install - Dev: pnpm dev - Test: pnpm test - Lint: pnpm lint:fix ## Code Standards - TypeScript strict mode - Named exports over default exports - API routes follow REST conventions in /src/api/ ## Testing Requirements - All PRs must include tests - vitest for unit tests, playwright for e2e
三者关系:README.md 是给人看的;AGENTS.md 是给所有代理看的,无论厂商;CLAUDE.md 在上面叠加 Claude 特有的额外指令。它们是互补的,不是互斥的。
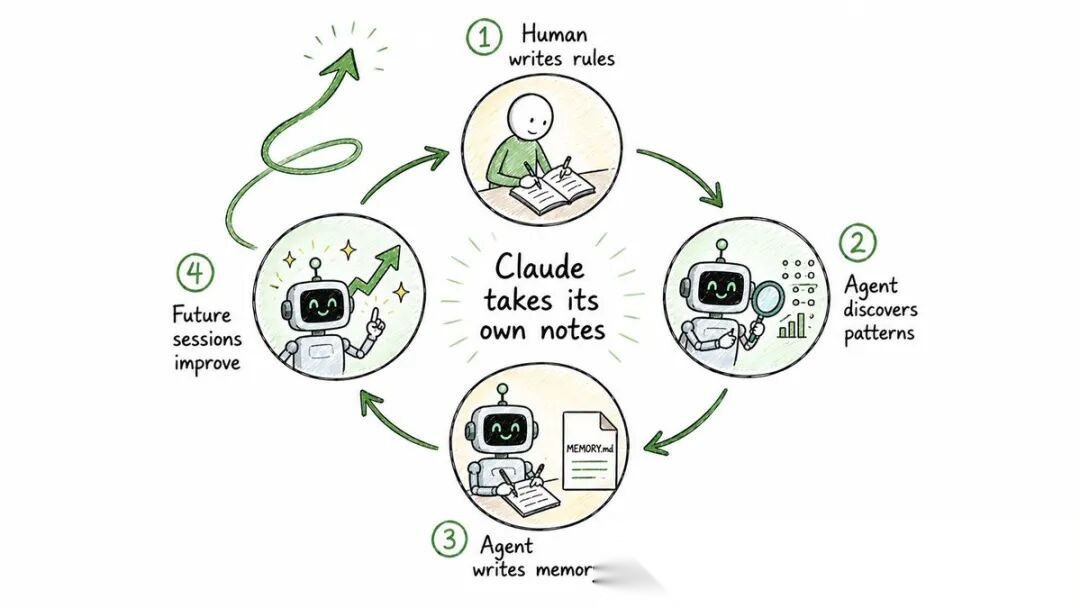
◆ 自动记忆 —— AI自己记笔记
这是最新也最有意思的一层。Claude Code 现在可以在会话过程中自己写记忆文件:
memory/ ├── MEMORY.md ← 索引,每次会话都加载 ├── debugging.md ← 调试模式笔记 ├── api-conventions.md ← API 设计决策 └── ...
关键区别:
-
你写 CLAUDE.md —— 你提供指令
-
Claude写 MEMORY.md —— 它捕捉自己学到的东西
→ 人类写规则
→ 代理在工作时发现模式
→ 代理写自己的记忆
→ 未来会话从更聪明的位置开始
你可以直接触发这个流程。在一个高产的会话结束时,说:
“Update your memory files with what you learned about our codebase today.”
这些学习成果会持久化。不用第五次重新解释你的自定义 ORM 封装了。随时运行 /memory 查看或编辑 Claude 保存了什么。
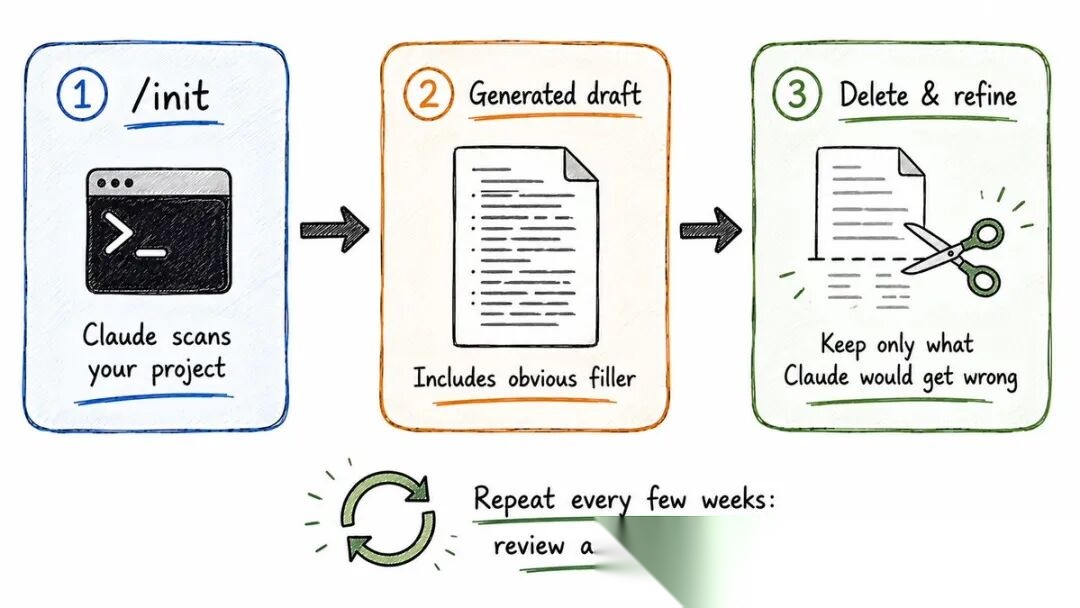
◆ /init 然后删除的工作流
在一个新项目上最快搭建记忆文件的方法:
-
在项目目录运行
/init -
Claude 基于你的代码库生成一个 CLAUDE.md 草稿
-
删除你不需要的
第三步是大多数人犯错的地方。生成的文件是草稿,不是成品。它经常包含填充内容,比如"本项目使用 JavaScript"——谢了,从 package.json 就能看出来。
从一份合理的草稿开始删,比从空白文件写要快得多。
持续维护:当 Claude 做了一个错误的假设——比如说它老是用一个已经废弃的包——不要只纠正一次。告诉它:"把这条加到我的 CLAUDE.md:始终从 @company/utils-v2 导入,不要用 @company/utils。"这个指令会在所有未来的会话中持续生效。
每隔几周,让 Claude 审查并清理 CLAUDE.md。指令会累积,有些变冗余,有些开始冲突。快速过一遍能让它保持锋利。
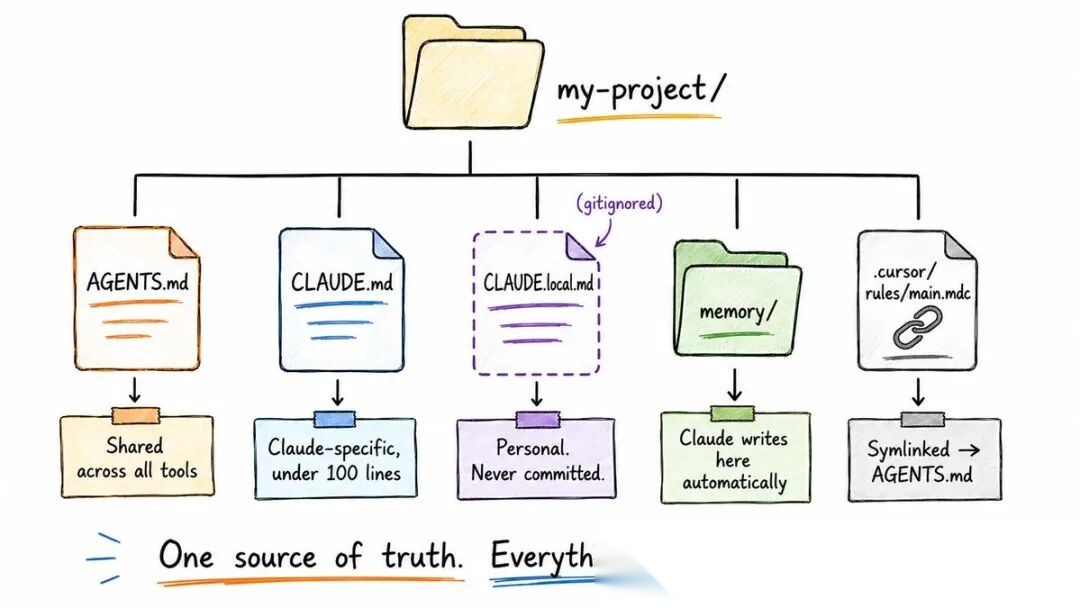
◆ 我的实际配置
在多个生产项目中测试后,留下来的方案是:
→ AGENTS.md 放在项目根目录——所有AI工具共享的指令。构建命令、代码标准、测试要求。
→ CLAUDE.md 配合 @imports 用于 Claude 特有的行为。保持在100行以内,主要指向 docs/ 文件。
→ CLAUDE.local.md 用于个人癖好——我的测试数据、沙箱URL、快捷命令。永远不提交到Git。
→ 自动记忆开启。Claude 自己记笔记,我每月审查一次。
→ 其他一切用符号链接指向 AGENTS.md。 单一事实来源:
# 符号链接设置,实现多工具一致性 ln -sfn AGENTS.md .github/copilot-instructions.md mkdir -p .cursor/rules && ln -sfn ../../AGENTS.md .cursor/rules/main.mdc
不优雅,但能消灭团队中所有工具的指令漂移。
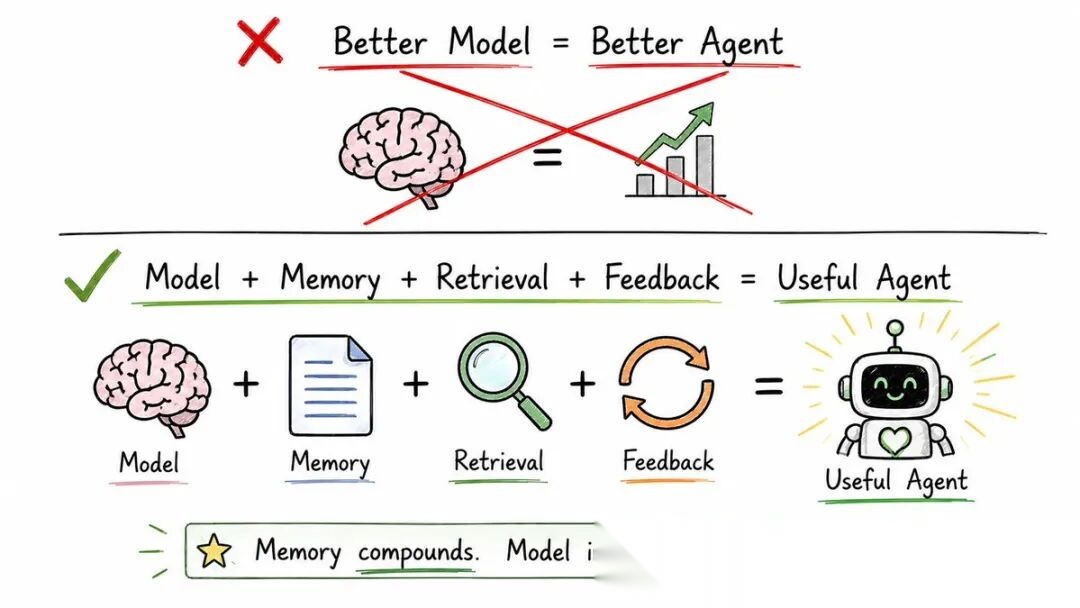
◆ 更大的转变
大多数开发者想的是:
更好的模型 = 更好的代理。
错了。
真正的公式是:
模型 + 记忆 + 检索 + 反馈 = 有用的代理
一个更聪明的模型如果没有记忆,明天依然会忘记你的测试命令。一个中等模型配上优秀的记忆系统,每周都会变得更锋利。
记忆是复利变量,模型智能不是。
◆ 总结
我在AI工作流上做的最大改进不是换模型。
是给模型配了一个记忆。
“Claude,我们用 pnpm”——每次会话都要说
和
“Claude 已经知道了”——每次会话
这两者之间的差距,就是工具和队友的差距。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 2
2 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)